前回データを一通り俯瞰してみました。
今回は相関係数を確認するのと、目的変数と従属変数の関係をグラフで可視化してみようと思います。
エイムズの住宅価格のデータセットの読み込み
import pandas as pd
# エイムズの住宅価格のデータセットの訓練データを読み込み
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/train.csv",dtype={'MSSubClass': str})最初からdtype={'MSSubClass': str}をread_csvメソッド内で指定してあげることにより、データ型を設定しています。
import seaborn as sns
# 描画設定
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)相関係数の確認
# 相関係数確認 (r < 0.3は非表示)
import matplotlib.pyplot as plt
plt.figure(figsize=(18,14))
corr=df.drop(columns=df.columns[[0]]).corr()
sns.heatmap(corr, vmax=1, vmin=-1, center=0, mask = corr < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})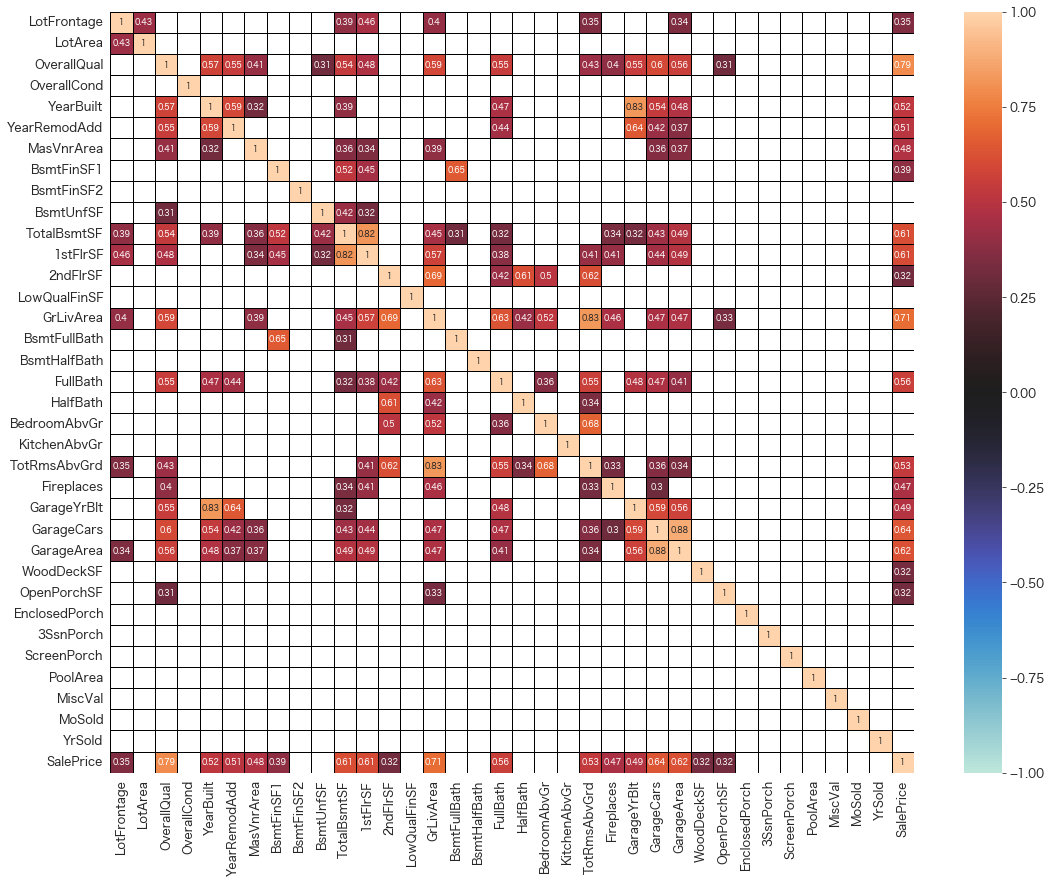
興味があるのは相関が高い変数なので、相関係数が0.3より下の値は見えなくしています。
マトリックスで見てもいいのですが、単純に相関係数が高い順にリストで並べてあげても良かったかもしれません。
次回相関係数を計算する機会があったときはそういったアウトプットも試してみようと思います。
・GarageCars x GarageAreaは相関が0.88と高いのでどちらかに絞ってもいいかも知れません。
・GrLivArea x SalePriceも0.71と強い相関がありますので、床面積が大きい家ほど住宅価格も高くなっていそうです。
・OverallQual x SalePriceも0.79と強い相関があります。状態がいい家の方が住宅価格が高くなっていそうです。
目的変数と従属変数の関係を見てみる
量的変数と質的変数と目的変数に分ける
## 数値型変数のデータフレーム
numerical_df = df.select_dtypes(exclude=['object']).copy()
## オブジェクト型変数のデータフレーム
obj_df = df.select_dtypes(include=['object']).copy()
## 目的変数のSeries
y = df.loc[:,"SalePrice"]住宅価格と各数値型変数の関係を描画
# 目的変数と各変数の関係 (数値型変数)
fig = plt.figure(figsize=(18,40))
for index in range(len(numerical_df.columns)):
plt.subplot(10,4,index+1)
sns.histplot(data=numerical_df,x=numerical_df.iloc[:,index].dropna(),y="SalePrice",bins=20)
fig.tight_layout(pad=1.0)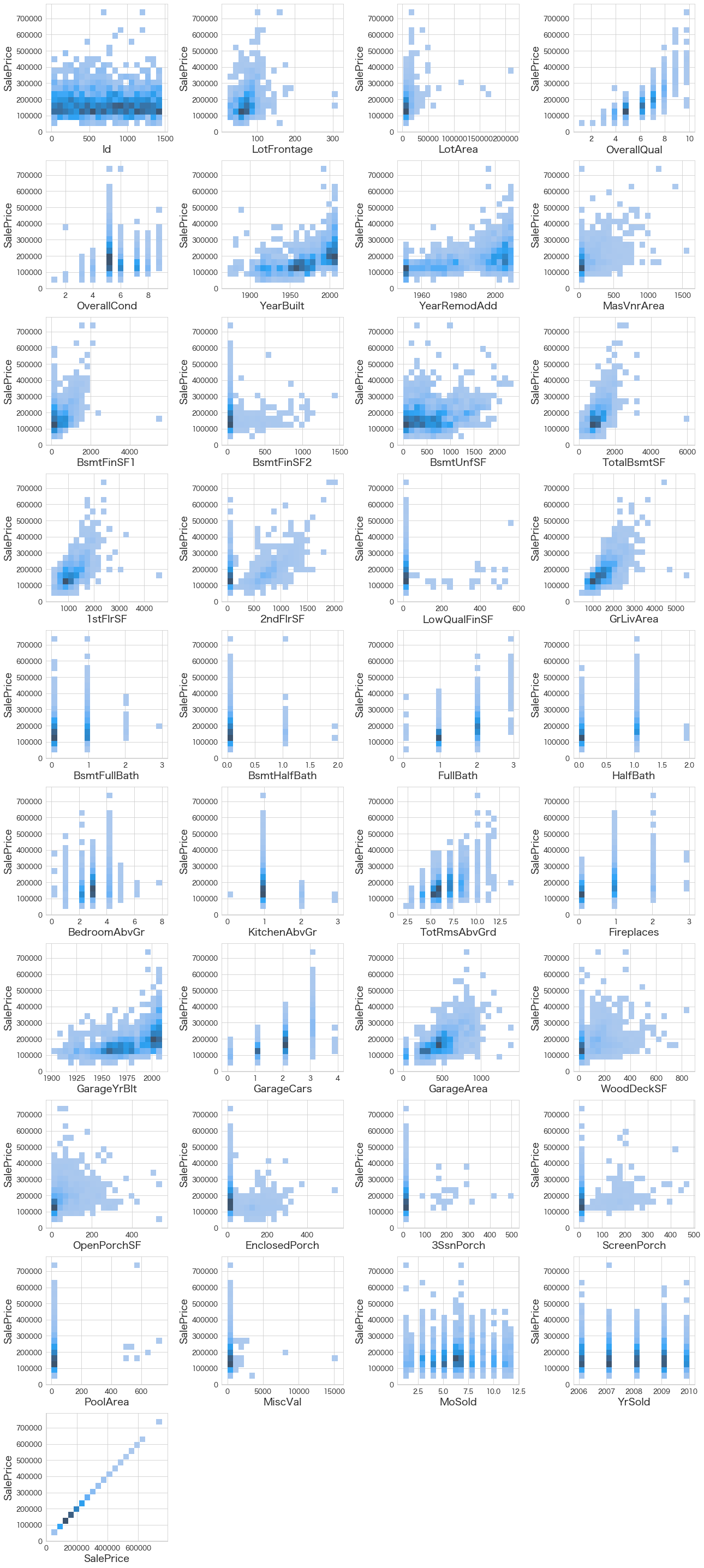
ただの散布図だと重なっている部分が分かりづらいので密度がわかるグラフで表現してみました。
色が濃いほど密度が高い(プロットがたくさん重なり合っている)という意味になります。
結果を確認すると相関係数通りの関係性になっているようです。時々外れ値の影響などで相関が高く見える場合もあるので、きちんと2軸グラフで確認した方が丁寧ですね。
住宅価格と各名義型変数の関係を描画
# obj_dfにSalePriceの情報を追加する
obj_df["SalePrice"] = y
for index in range(len(obj_df.columns)):
# SalePrice x SalePriceは除外
if obj_df.columns[index] == 'SalePrice':
break;
print(index,obj_df.columns[index])
g = sns.displot(obj_df, x="SalePrice", col=obj_df.columns[index],bins=20,col_wrap=5)
g.set_xticklabels(rotation = -90)
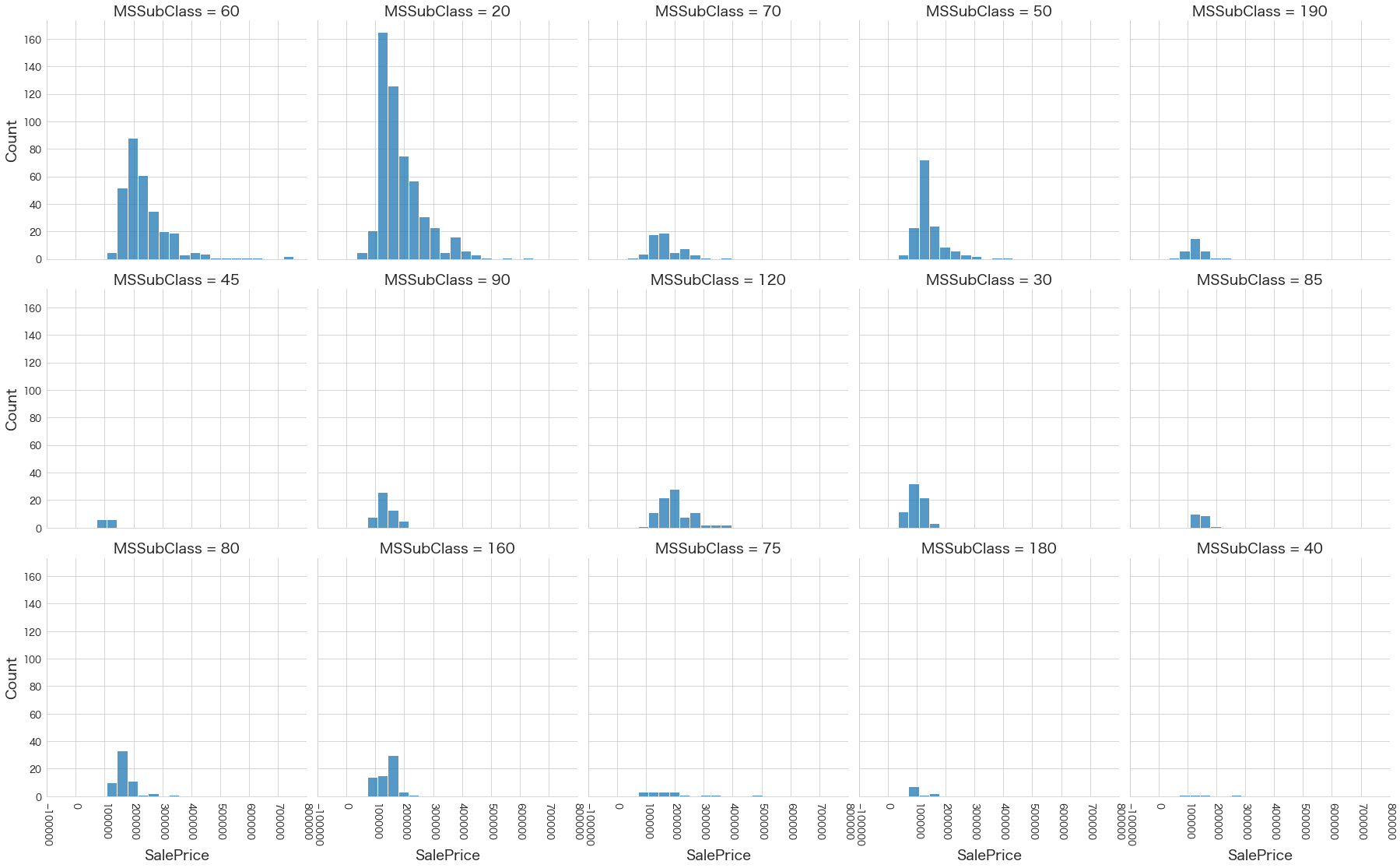
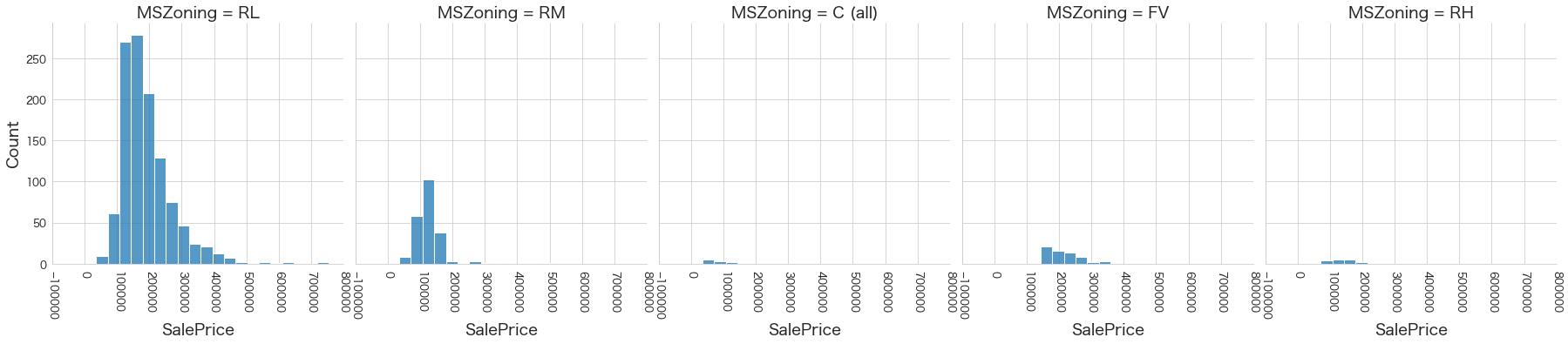
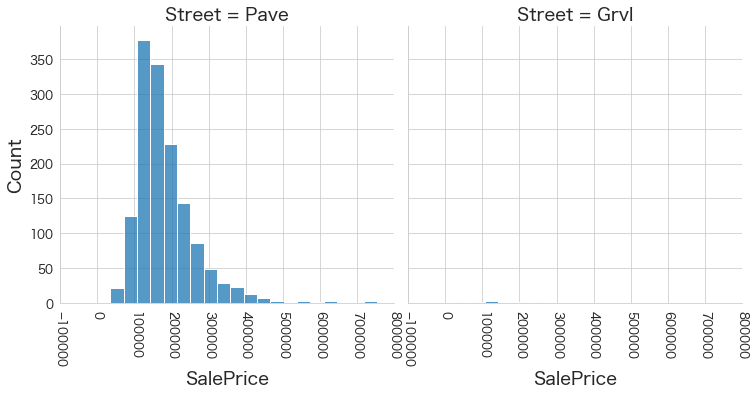
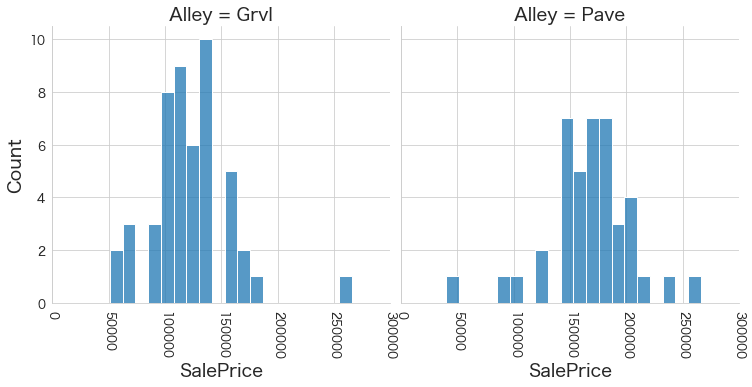
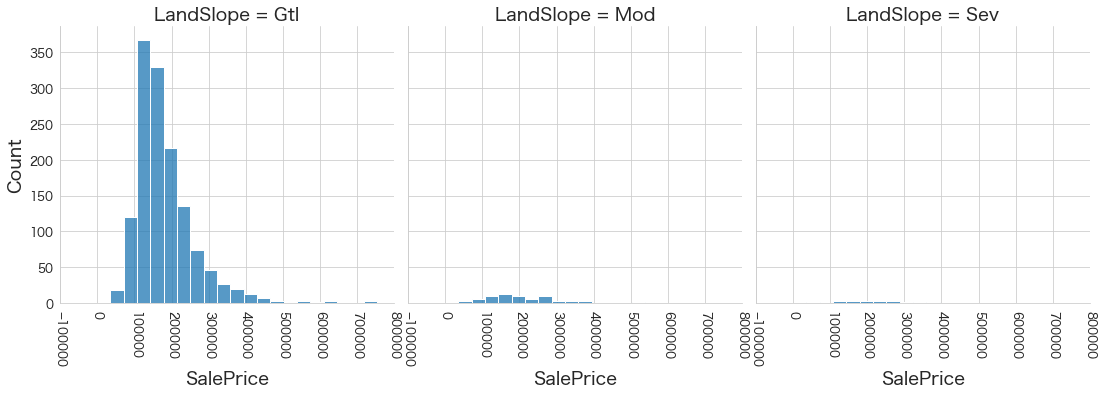
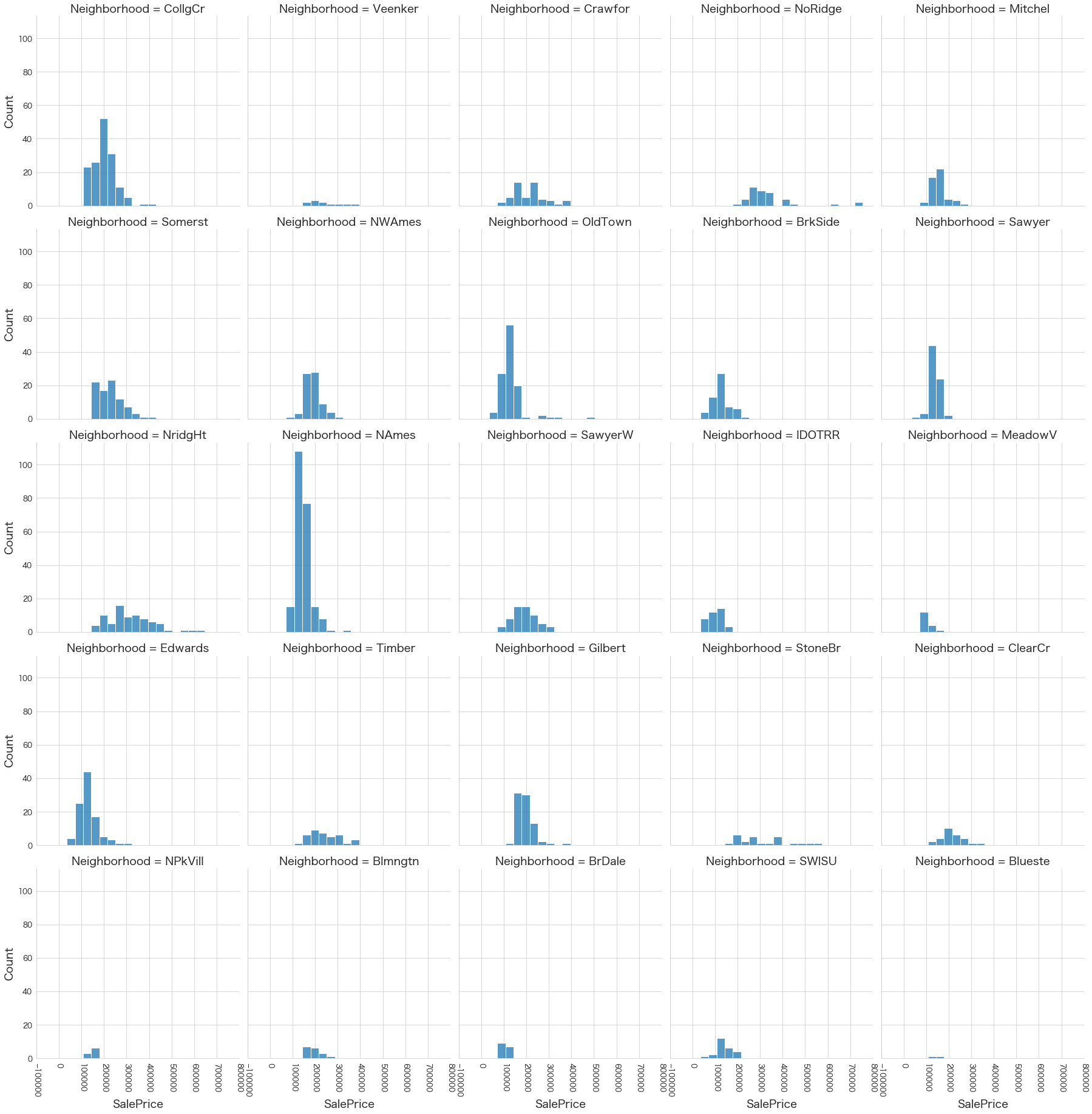
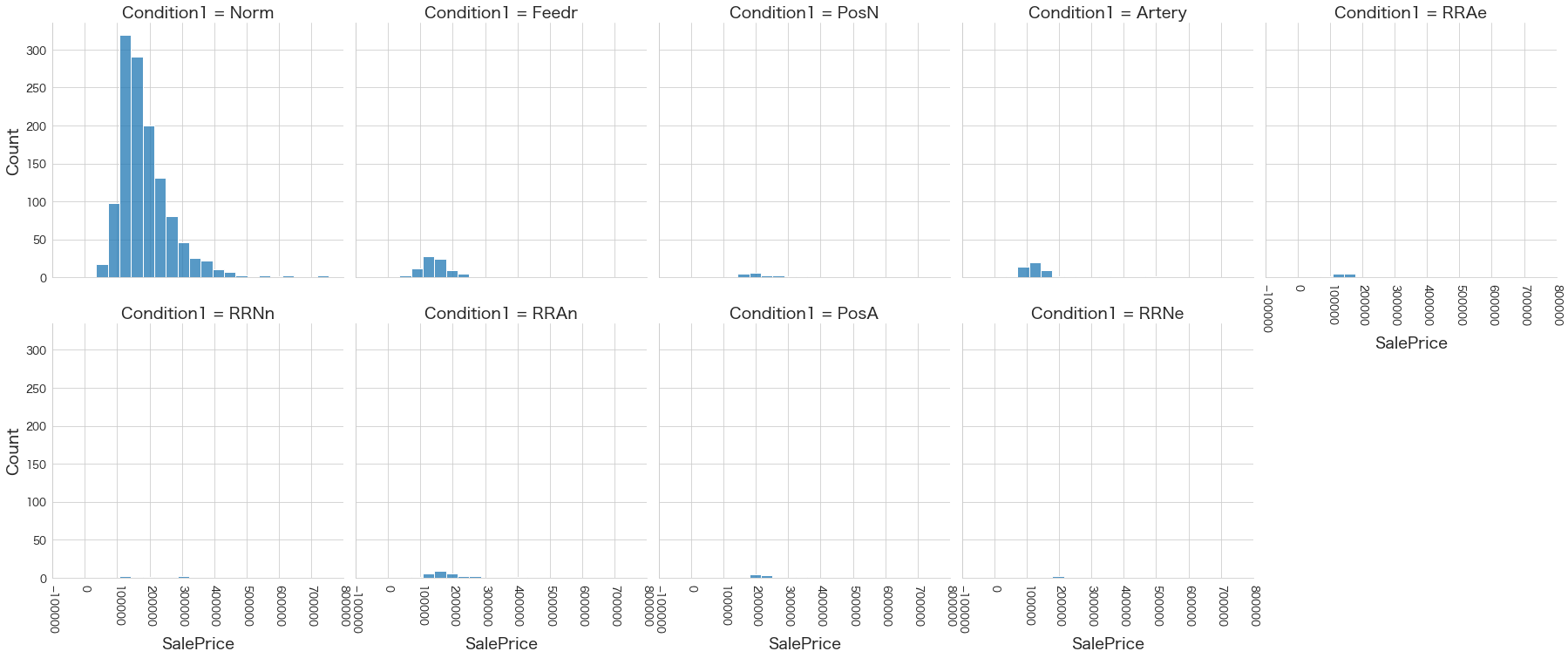
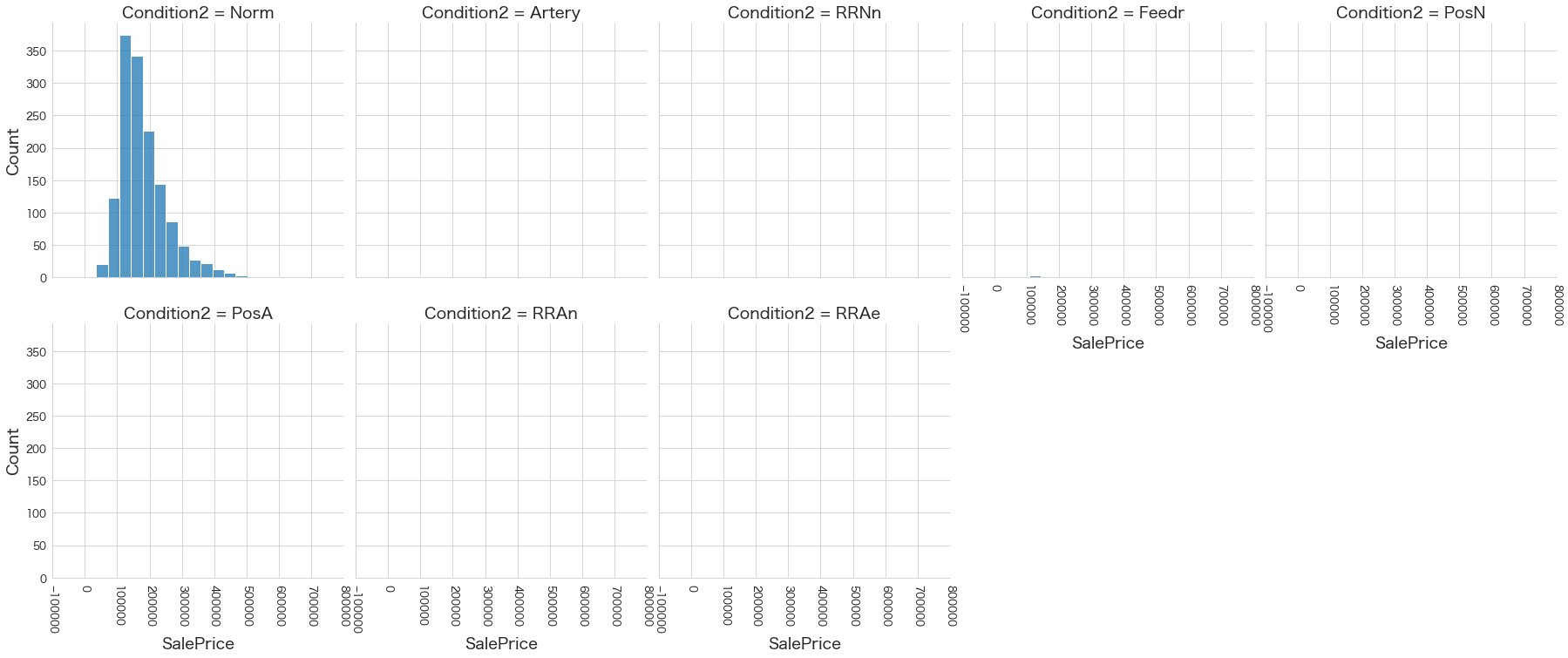
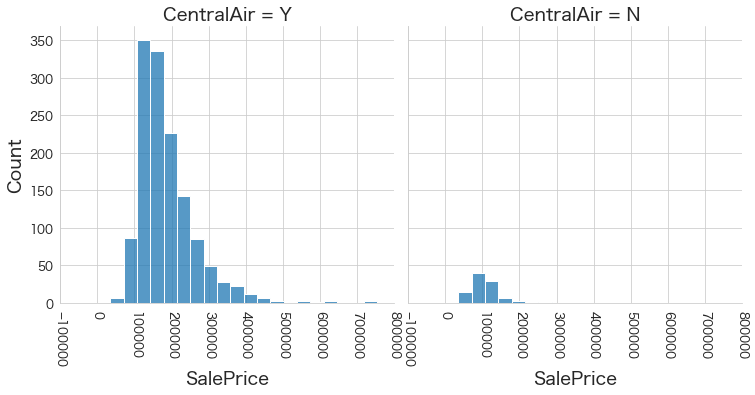
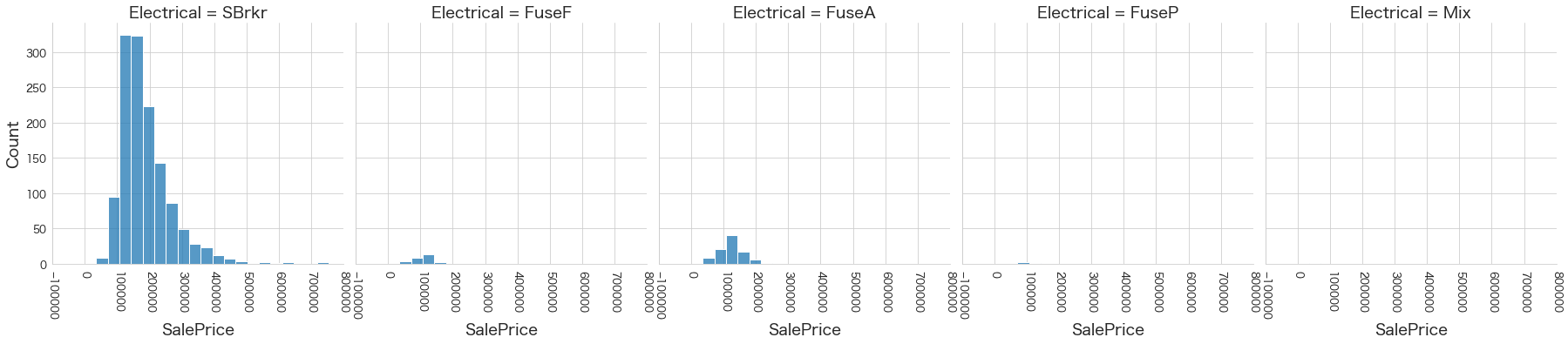
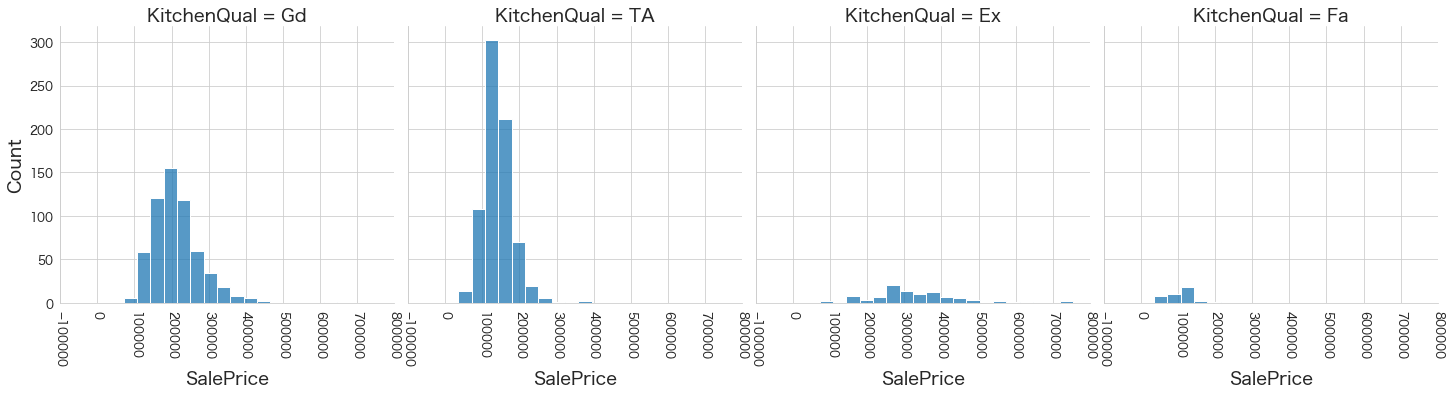
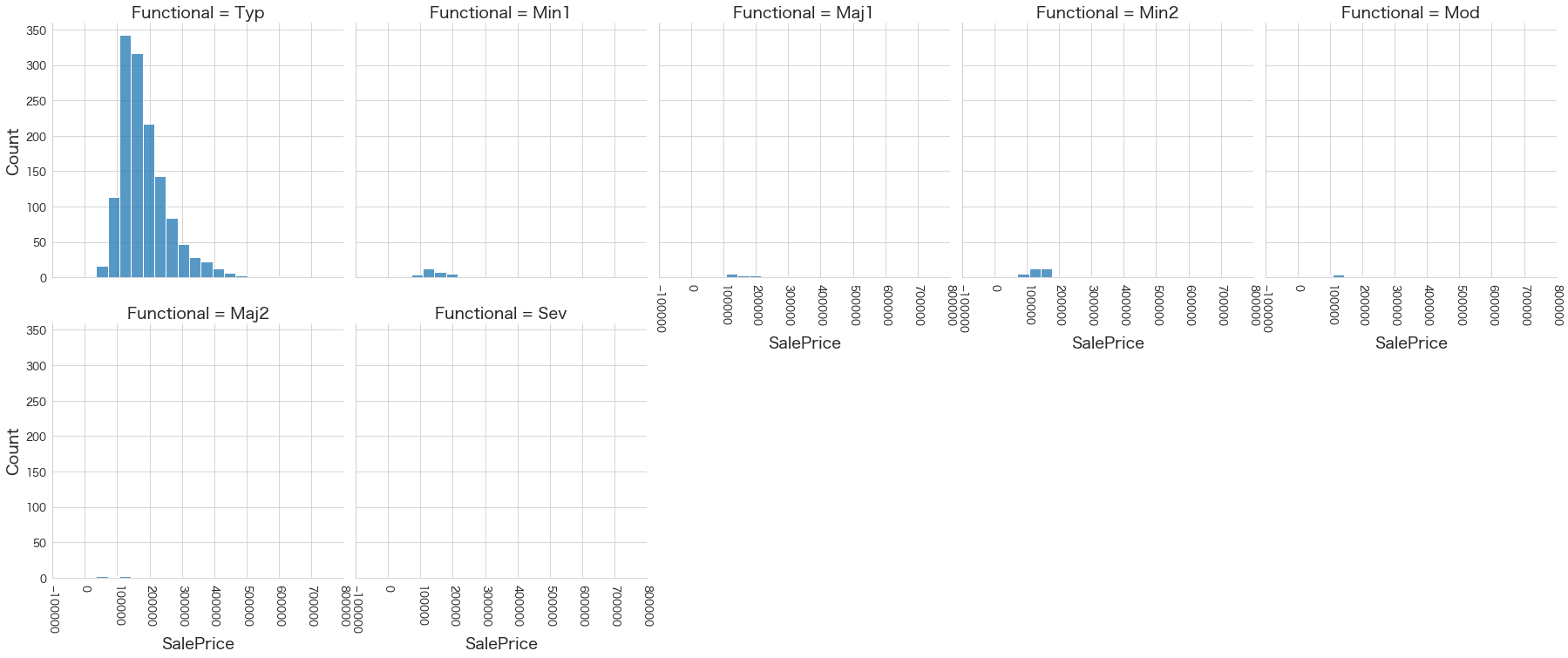
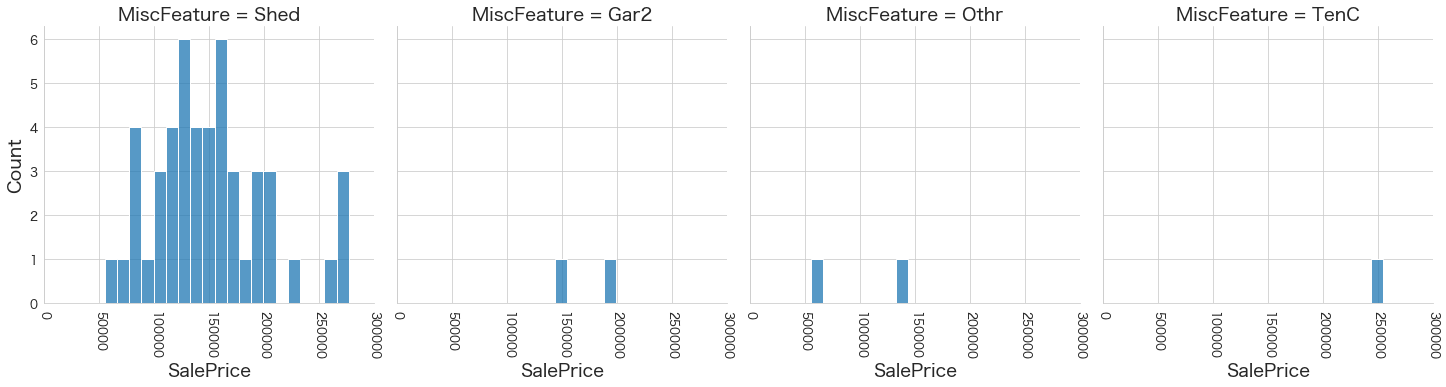
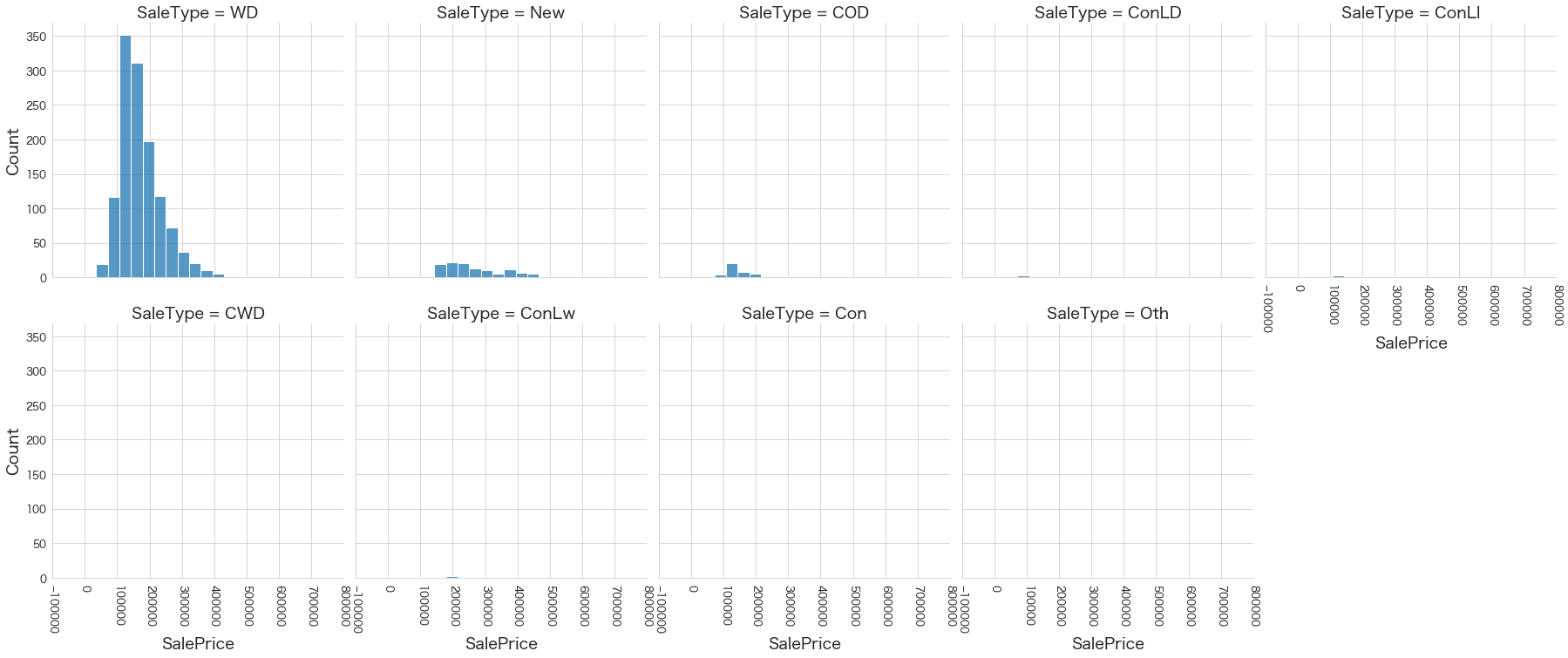
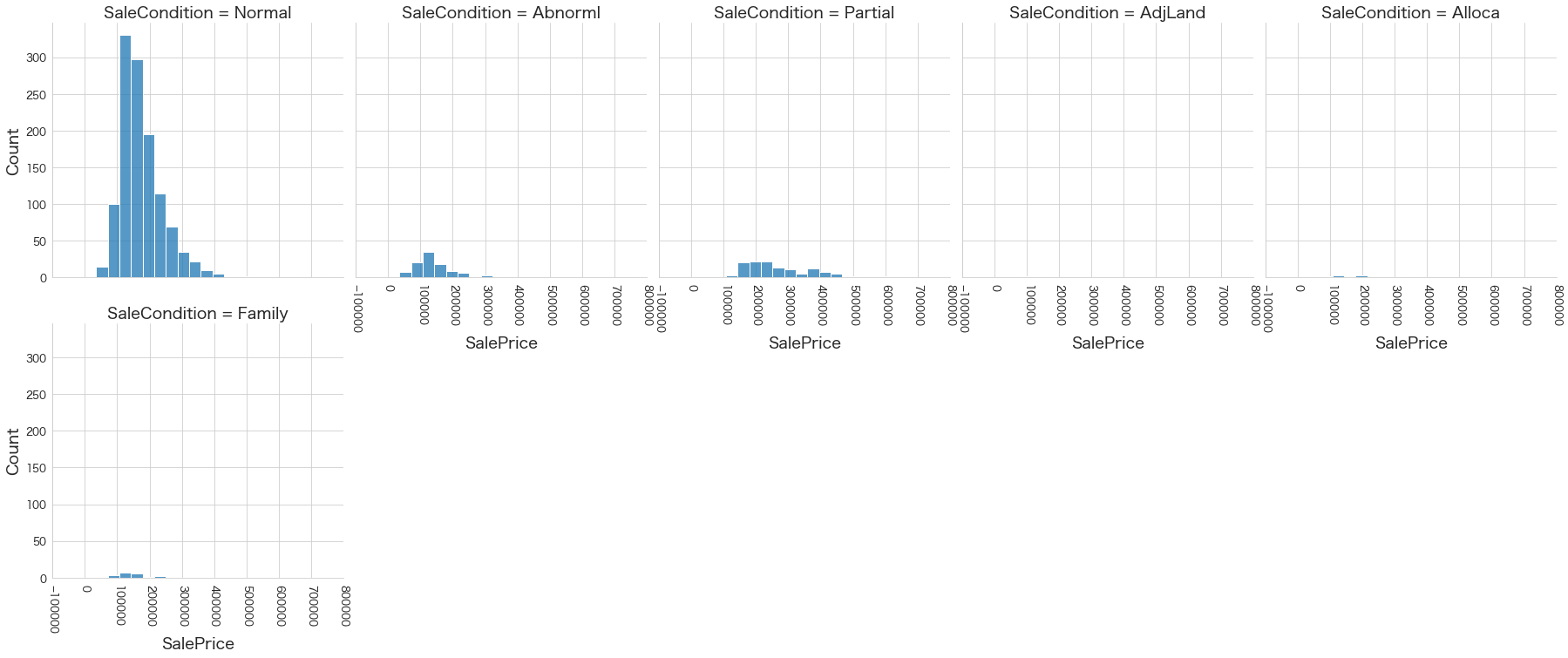
plt.show()各名義変数の区分値 x 住宅価格の分布を確認しています。
特定の区分値は住宅価格が高い傾向にありそうなどと言ったことがあると、予測モデルに組み込みやすくなりますね。
今回は住宅価格が低いもしくは高い傾向にある区分はなさそうに見えました。
0 MSSubClass
1 MSZoning
2 Street
3 Alley
4 LotShape
5 LandContour
6 Utilities
7 LotConfig
8 LandSlope
9 Neighborhood
10 Condition1
11 Condition2
12 BldgType
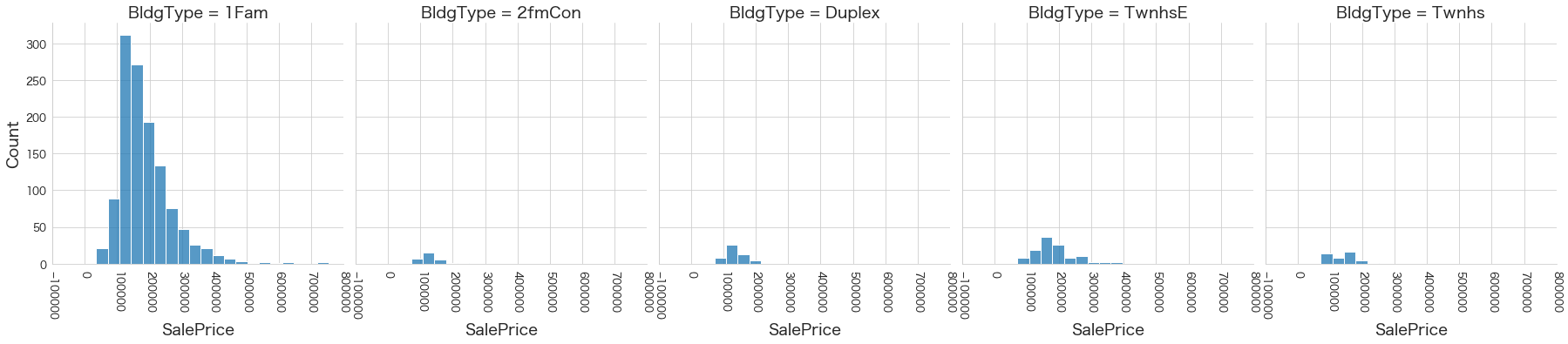
13 HouseStyle
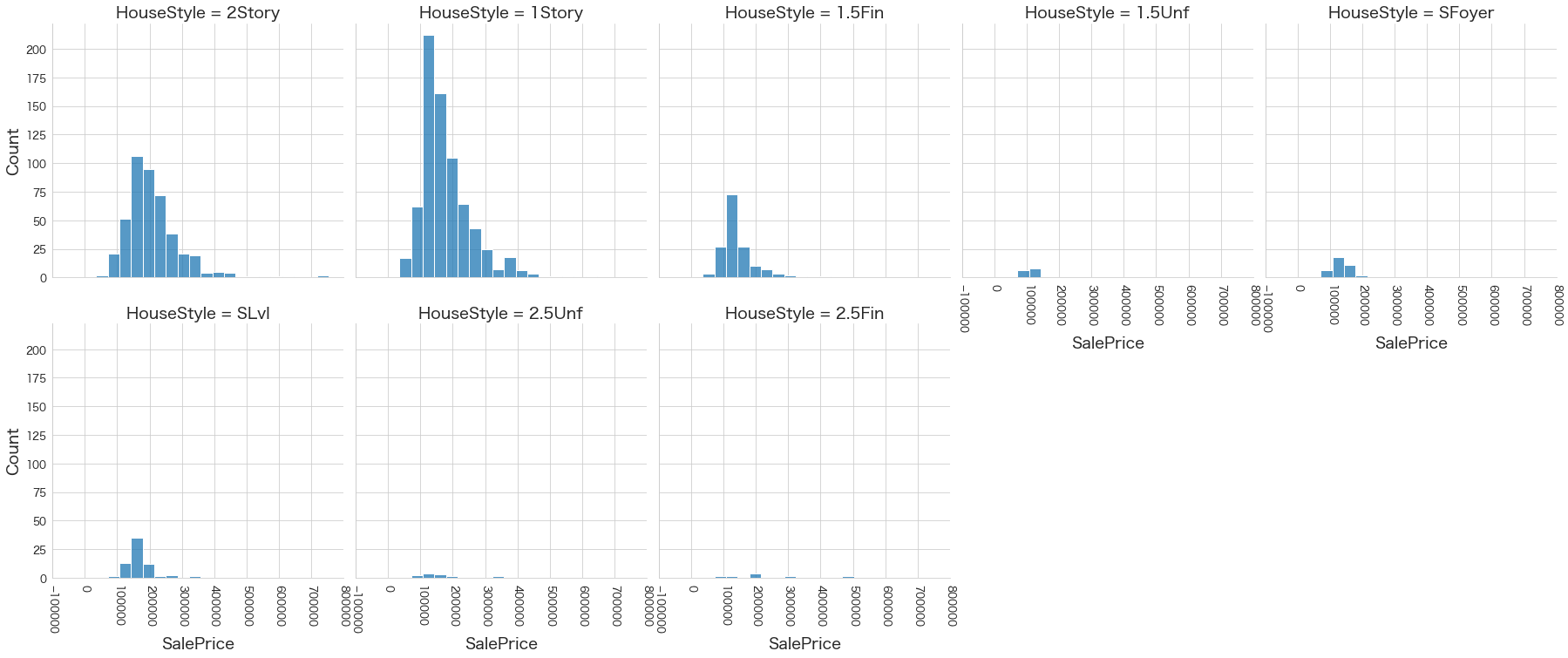
14 RoofStyle
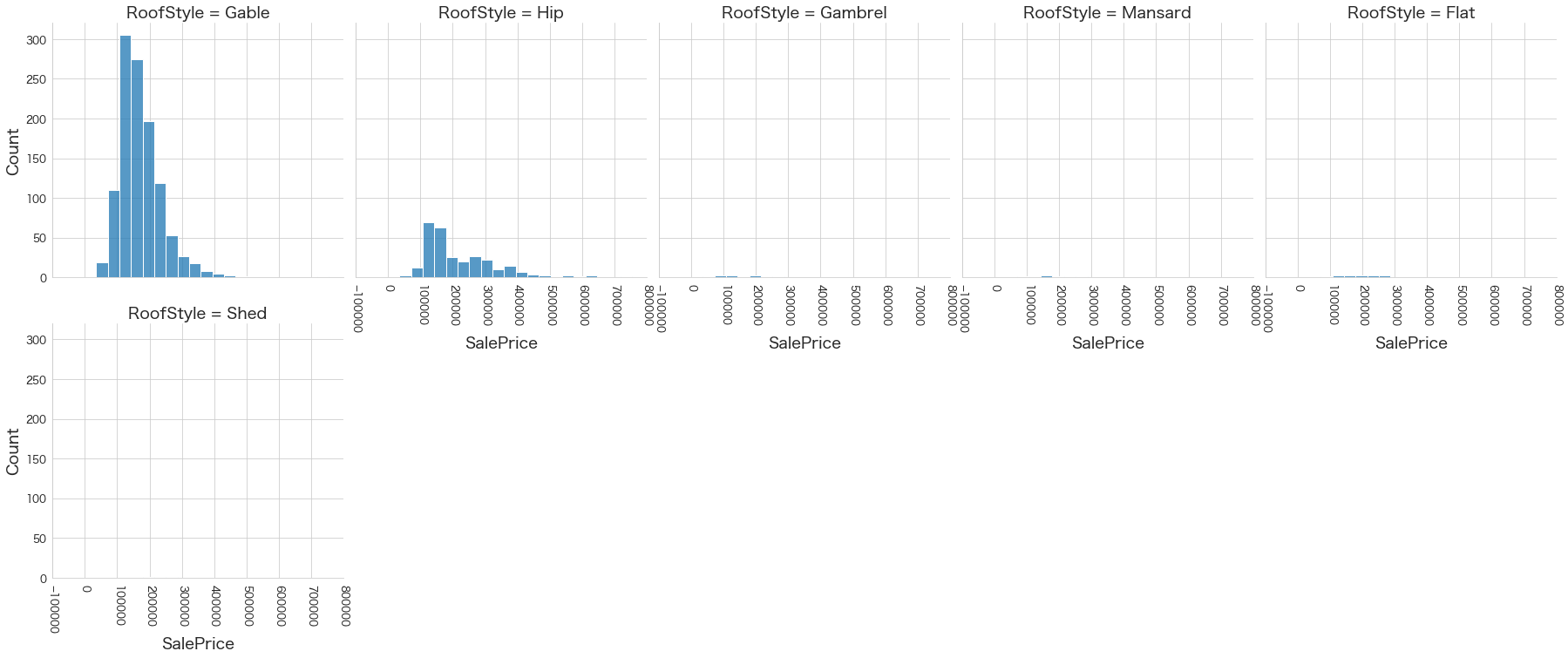
15 RoofMatl
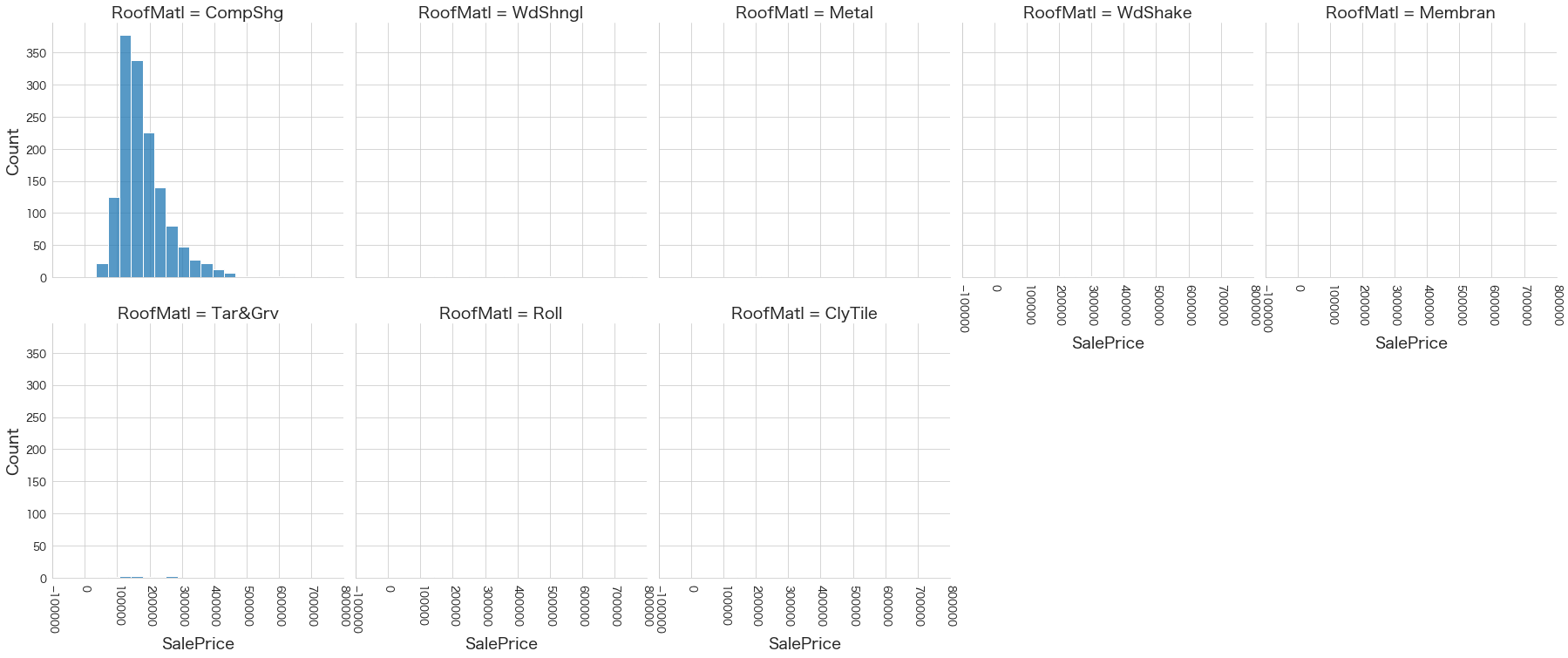
16 Exterior1st
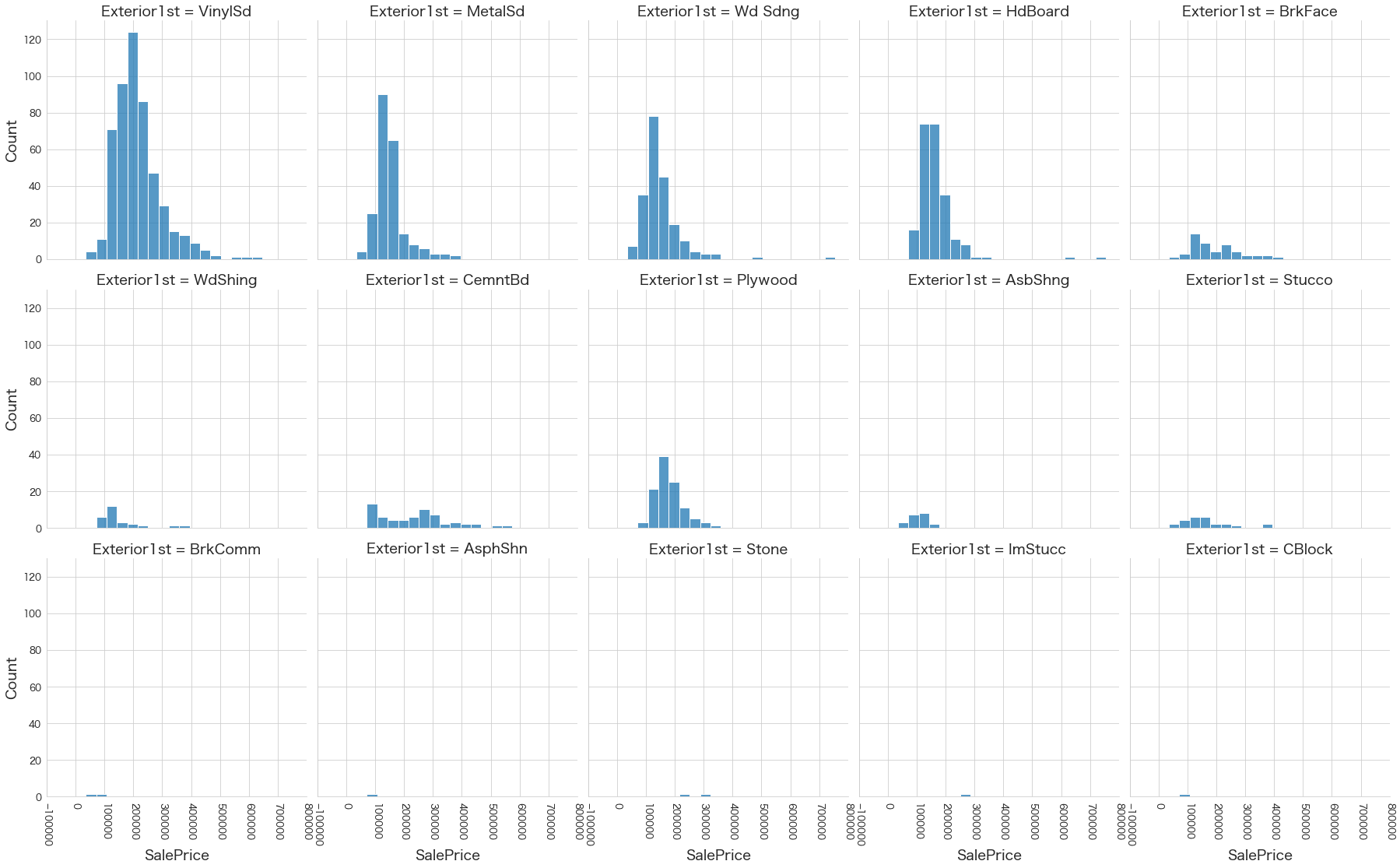
17 Exterior2nd
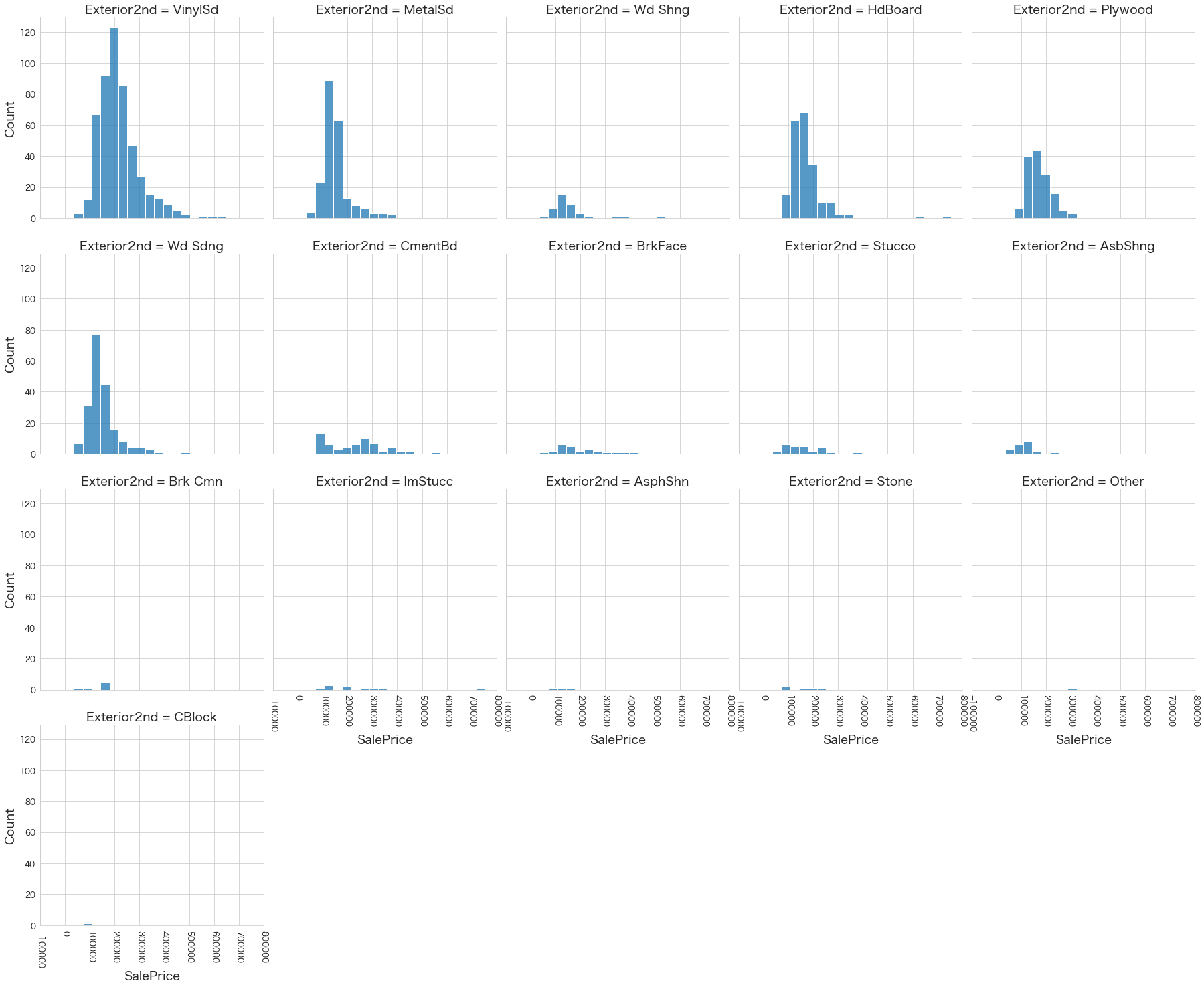
18 MasVnrType
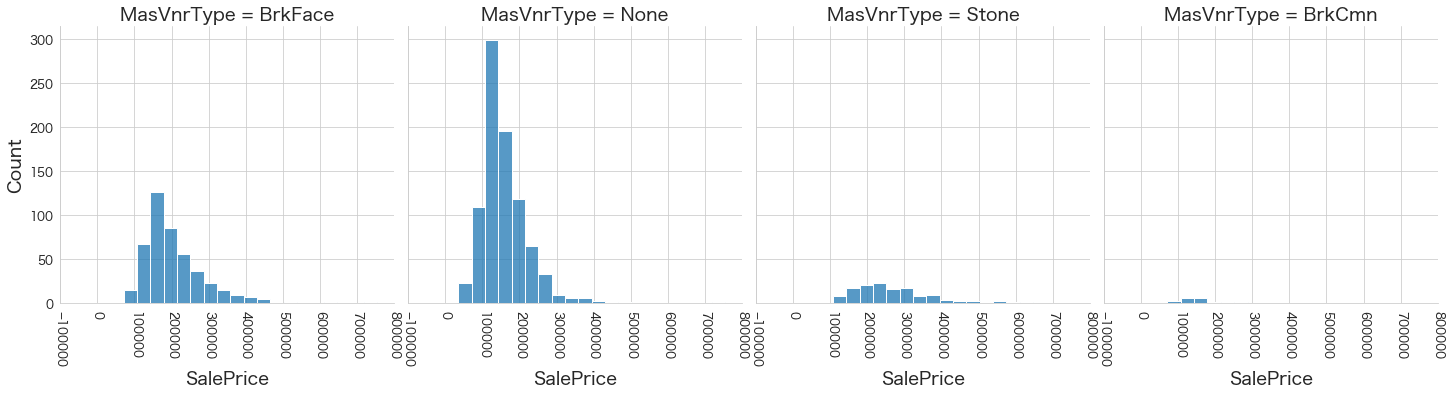
19 ExterQual
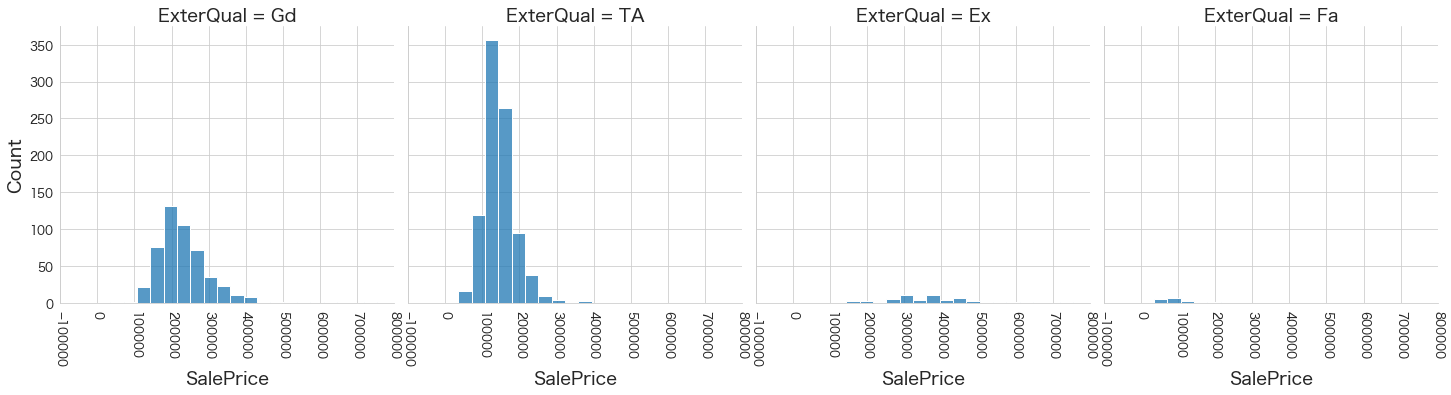
20 ExterCond
21 Foundation
22 BsmtQual
23 BsmtCond
24 BsmtExposure
25 BsmtFinType1
26 BsmtFinType2
27 Heating

28 HeatingQC
29 CentralAir
30 Electrical
31 KitchenQual
32 Functional
33 FireplaceQu
34 GarageType
35 GarageFinish
36 GarageQual
37 GarageCond
38 PavedDrive
39 PoolQC
40 Fence
41 MiscFeature
42 SaleType
43 SaleCondition
まとめ
相関係数と目的変数と各変数の関係性をグラフにして確認して見ました。
名義型より数値型の方が予測モデルの説明変数に使いやすそうですね。
次はデータ加工をやろうと思います。
参照
https://seaborn.pydata.org/generated/seaborn.heatmap.html
https://stackoverflow.com/questions/33104322/auto-adjust-font-size-in-seaborn-heatmap
https://stackoverflow.com/questions/63516973/how-can-i-mark-xticks-at-the-center-of-bins-for-a-seaborn-distplot