前回、決定木モデルで70%の精度でした。
今回はロジスティック回帰を使って予測してみようと思います。
私が一番好きなモデルで実業務でもよく使っています。
評価指標
タイタニックのデータセットは生存有無を正確に予測できた乗客の割合(Accuracy)を評価指標としています。
ロジスティック回帰
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
学習データと評価データの読み込み
import pandas as pd
import numpy as np
# タイタニックデータセットの学習用データと評価用データの読み込み
df_train = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_train.csv")
df_eval = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_eval.csv")概要確認
# 概要確認
df_train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 891 non-null object
12 FamilyCnt 891 non-null int64
13 SameTicketCnt 891 non-null int64
14 Pclass_str_1 891 non-null float64
15 Pclass_str_2 891 non-null float64
16 Pclass_str_3 891 non-null float64
17 Sex_female 891 non-null float64
18 Sex_male 891 non-null float64
19 Embarked_C 891 non-null float64
20 Embarked_Q 891 non-null float64
21 Embarked_S 891 non-null float64
dtypes: float64(10), int64(7), object(5)
memory usage: 153.3+ KB
# 概要確認
df_eval.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 418 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 418 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
11 Pclass_str_1 418 non-null float64
12 Pclass_str_2 418 non-null float64
13 Pclass_str_3 418 non-null float64
14 Sex_female 418 non-null float64
15 Sex_male 418 non-null float64
16 Embarked_C 418 non-null float64
17 Embarked_Q 418 non-null float64
18 Embarked_S 418 non-null float64
19 FamilyCnt 418 non-null int64
20 SameTicketCnt 418 non-null int64
dtypes: float64(10), int64(6), object(5)
memory usage: 68.7+ KB
# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)モデル作成
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=0,max_iter=1000,verbose=3)max_iterの値を1000にしています。
これは最初にfitしたときに下記エラー?警告?に遭遇したためです。
Increase the number of iterations (max_iter) or scale the data as shown in:
デフォルトの値(max_iter=100)だと警告が出てくるので、iterの回数を上げています。
ただ上げても精度は変わらなかったです。
# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(df_train, test_size=0.20,random_state=100)
# 説明変数
FEATURE_COLS=[
'Age'
, 'Fare'
, 'SameTicketCnt'
, 'Pclass_str_1'
, 'Pclass_str_3'
, 'Sex_female'
, 'Embarked_Q'
, 'Embarked_S'
]
X_train = x_train[FEATURE_COLS] # 説明変数 (train)
Y_train = x_train["Survived"] # 目的変数 (train)
X_test = x_test[FEATURE_COLS] # 説明変数 (test)
Y_test = x_test["Survived"] # 目的変数 (test)model = clf.fit(X_train,Y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
This problem is unconstrained.
・・・省略・・・
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
9 104 121 1 0 0 9.765D-02 3.172D+02
X = -3.8864D-02 3.1145D-03 -1.9699D-01 8.1966D-01 -1.3555D+00 2.4869D+00
-7.4909D-02 -4.1107D-01 6.8544D-01
F = 317.22127537805329
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
モデルの精度の確認
# 訓練データへの当てはまりを確認
# Return mean accuracy on the given test data and labels.
model.score(X_train,Y_train)
0.8117977528089888
# テストデータへの当てはまりを確認
# Return mean accuracy on the given test data and labels.
model.score(X_test,Y_test)
0.7988826815642458
訓練データとテストデータへの当てはまりを確認しましたが、そこまで差がなさそうなのでオーバーフィットはしていなさそうです。
デフォルトの設定の正則化でいい感じに学習してくれているだと思います。
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_estimator(clf,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()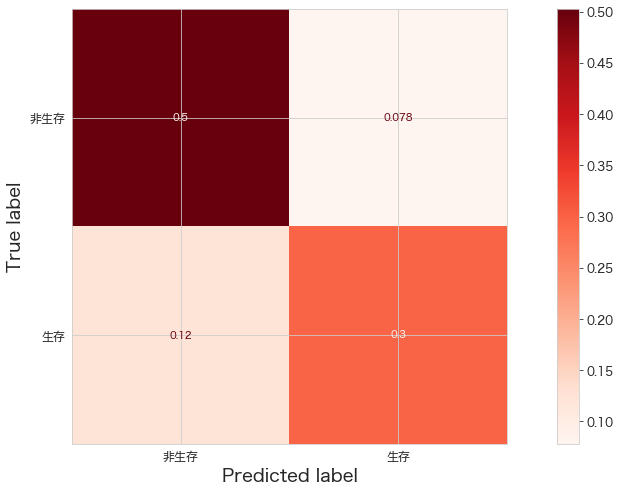
TP(正解=1、予測=1)とFP(正解=0、予測=0)の割合を確認。意外とTPを当てることが出来ていそう。
# モデルパラメーターの確認
model.get_params()
{'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 1000,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': 0,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 3,
'warm_start': False}
係数と切片の確認
# 係数確認
coef = pd.DataFrame()
coef["features"] = model.feature_names_in_
coef["coef"] = model.coef_[0]
coef
features coef 0 Age -0.038864 1 Fare 0.003114 2 SameTicketCnt -0.196987 3 Pclass_str_1 0.819655 4 Pclass_str_3 -1.355546 5 Sex_female 2.486910 6 Embarked_Q -0.074909 7 Embarked_S -0.411074
女性であることやPclass=1であることは符号がプラスなので生存に関わっていそうです。
ここで符号の反転などが起きている場合(Pclass=1なのに係数がマイナスなど)は不安定なモデルと判断し、私は使わないことにしています。
変数間の値の比較はデータを標準化していれば可能だと思います。
今回は標準化せずにモデリングしてしまったので、標準化バージョンもやってみようと思います。
# 切片確認
print("Intercept =",model.intercept_[0])Intercept = 0.6854377614688429
ここで出てくる係数や切片を数式に落とし込みシステムへ導入するなんてことも出来るかと思います。
クロスバリデーションで精度を確認
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
# StratifiedKFold with KFold = 10
from sklearn.model_selection import cross_val_score
X = df_train[FEATURE_COLS] # 説明変数 (train)
Y = df_train["Survived"] # 目的変数 (train)
np.mean(cross_val_score(clf, X, Y, cv=10,verbose=3))
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
This problem is unconstrained.
・・・省略・・・
0.8036204744069912
8956D-01
F = 359.97764259905961
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
精度は80%でした。
Kaggle提出用データの作成
df_eval["Survived"] = clf.predict(df_eval[FEATURE_COLS])df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)Kaggleへアップロード
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #002. logistic regression"
100%|████████████████████████████████████████| 2.77k/2.77k [00:04<00:00, 586B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
コンペの精度確認

75%になりました!
データを標準化した場合としない場合の比較
sklearnのロジスティック回帰(sklearn version 1.0.2)では過学習を防ぐためにL2正則化(L2 regularization)がデフォルトで使用されています。
正則化に関してはRidgeとLassoの記事が分かりやすかったです。
正則化ではマンハッタン距離やユークリッド距離が関係するようで、距離の計算をする都合上データの標準化をした方がいいようです。
また、Elements of Statistical Learningという図書でも正則化の際はデータを正規化することを推奨しているようです。
Regularization makes the predictor dependent on the scale of the features.
The authors of Elements of Statistical Learning recommend to normalize the features when doing logistic regression with regularization
https://stats.stackexchange.com/questions/290958/logistic-regression-and-scaling-of-features
ということで、標準化をしてからモデルに学習データを渡してあげてみます。
標準化 (pipeline + StandardScaler)
# pipelineでデータを標準化してモデリングをする
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
pipeline = make_pipeline(StandardScaler(), LogisticRegression(random_state=0,max_iter=1000,verbose=3))# fitする
fit_pipeline = pipeline.fit(X_train,Y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
・・・省略・・・
N Tit Tnf Tnint Skip Nact Projg F
9 11 12 1 0 0 9.252D-04 3.138D+02
X = -5.3102D-01 1.3868D-01 -2.6803D-01 3.7883D-01 -7.0413D-01 1.2292D+00
-2.7997D-02 -1.9567D-01 -7.1526D-01
F = 313.81239604323093
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
iterationの数が減ったような気がします。標準化の効果でしょうか。
# 訓練データへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
fit_pipeline.score(X_train,Y_train)
0.8103932584269663
あとで比較しますが、標準化しなかった場合より精度が若干下がっています。
オーバーフィットが若干和らいでいるのかも知れません。
# テストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
fit_pipeline.score(X_test,Y_test)
0.7988826815642458
テストデータへの精度は変わりないようです。
# モデルパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('standardscaler', StandardScaler()),
('logisticregression',
LogisticRegression(max_iter=1000, random_state=0, verbose=3))],
'verbose': False,
'standardscaler': StandardScaler(),
'logisticregression': LogisticRegression(max_iter=1000, random_state=0, verbose=3),
'standardscaler__copy': True,
'standardscaler__with_mean': True,
'standardscaler__with_std': True,
'logisticregression__C': 1.0,
'logisticregression__class_weight': None,
'logisticregression__dual': False,
'logisticregression__fit_intercept': True,
'logisticregression__intercept_scaling': 1,
'logisticregression__l1_ratio': None,
'logisticregression__max_iter': 1000,
'logisticregression__multi_class': 'auto',
'logisticregression__n_jobs': None,
'logisticregression__penalty': 'l2',
'logisticregression__random_state': 0,
'logisticregression__solver': 'lbfgs',
'logisticregression__tol': 0.0001,
'logisticregression__verbose': 3,
'logisticregression__warm_start': False}
「steps」という項目が増えていますね
# stepsからlogistic regressionの部分を抽出
model_pipeline = fit_pipeline.named_steps["logisticregression"] # or pipeline.steps[1][1]pipelineだと係数(model.coef_)が確認できないので、モデルをpipelineから取り出しておきます。
# モデル部分のパラメーターを確認。
model_pipeline.get_params()
{'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 1000,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': 0,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 3,
'warm_start': False}
# 説明変数の係数を確認
coef = pd.DataFrame()
coef["features"] = fit_pipeline.feature_names_in_
coef["coef"] = model_pipeline.coef_[0]
coef["coef_pct"] = np.abs(coef["coef"]) / np.abs(coef["coef"]).sum()
coef.sort_values(by="coef_pct",ascending=False)
features coef coef_pct 5 Sex_female 1.229169 0.353867 4 Pclass_str_3 -0.704128 0.202712 0 Age -0.531025 0.152877 3 Pclass_str_1 0.378831 0.109062 2 SameTicketCnt -0.268033 0.077164 7 Embarked_S -0.195670 0.056332 1 Fare 0.138682 0.039925 6 Embarked_Q -0.027997 0.008060
標準化前と係数の値は変更になっていますが、序列は変わってないように見えます。
標準化することによって、変数間の比較も可能になったので寄与度(coef_pct)を計算してみました。
女性であること、Pclass=3であること、年齢が予測に寄与しているようです。
これは映画タイタニックのセリフであった、女性と子供を優先して救命ボートに乗せるに合致していますね。
標準化 (StandardScalerのみ)
# 標準化する
scaler = StandardScaler()
X_train_normalized = scaler.fit_transform(X_train)
X_test_normalized = scaler.fit_transform(X_test)# モデル作成
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=0,max_iter=1000,verbose=3)# fitする
model_normalized = clf.fit(X_train_normalized,Y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
・・・省略・・・
N Tit Tnf Tnint Skip Nact Projg F
9 11 12 1 0 0 9.252D-04 3.138D+02
X = -5.3102D-01 1.3868D-01 -2.6803D-01 3.7883D-01 -7.0413D-01 1.2292D+00
-2.7997D-02 -1.9567D-01 -7.1526D-01
F = 313.81239604323093
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
# テストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
model_normalized.score(X_train_normalized,Y_train)
0.8103932584269663
pipelineを使った場合と変わりないようです。
# テストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
model_normalized.score(X_test_normalized,Y_test)
0.7988826815642458
こちらもpipelineを使った場合と変わりないようです。
coef = pd.DataFrame()
coef["features"] = X_train.columns
coef["coef"] = model_normalized.coef_[0]
coef["coef_pct"] = np.abs(coef["coef"]) / np.abs(coef["coef"]).sum()
coef.sort_values(by="coef_pct",ascending=False)
features coef coef_pct 5 Sex_female 1.229169 0.353867 4 Pclass_str_3 -0.704128 0.202712 0 Age -0.531025 0.152877 3 Pclass_str_1 0.378831 0.109062 2 SameTicketCnt -0.268033 0.077164 7 Embarked_S -0.195670 0.056332 1 Fare 0.138682 0.039925 6 Embarked_Q -0.027997 0.008060
pipelineの結果と変わりありません。
標準化なし、標準化あり(pipeline)、標準化あり(StandardScalerのみ)の結果比較
# confusion matrix
from sklearn.metrics import confusion_matrix
print("#1:正規化なしver\n",confusion_matrix(Y_test,model.predict(X_test)))
print("#2:正規化あり+pipeline\n",confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
print("#3:正規化あり\n",confusion_matrix(Y_test,model_normalized.predict(X_test_normalized)))
#1:正規化なしver
[[90 14]
[22 53]]
#2:正規化あり+pipeline
[[90 14]
[22 53]]
#3:正規化あり
[[90 14]
[22 53]]
テストデータへの結果は変わりません。
# 学習データへの当てはまりを確認
print("#1:正規化なしver\n",model.score(X_train,Y_train))
print("#2:正規化あり+pipeline\n",fit_pipeline.score(X_train,Y_train))
print("#3:正規化あり\n",model_normalized.score(X_train_normalized,Y_train))
#1:正規化なしver
0.8117977528089888
#2:正規化あり+pipeline
0.8103932584269663
#3:正規化あり
0.8103932584269663
オーバフィットが軽減できているようです。
kaggleへアップロードする用のデータへの当てはまりは若干よくなるかもしれません。
# テストデータへの当てはまりを確認
print("#1:正規化なしver\n",model.score(X_test,Y_test))
print("#2:正規化あり+pipeline\n",fit_pipeline.score(X_test,Y_test))
print("#3:正規化あり\n",model_normalized.score(X_test_normalized,Y_test))
#1:正規化なしver
0.7988826815642458
#2:正規化あり+pipeline
0.7988826815642458
#3:正規化あり
0.7988826815642458
テストデータに対する精度は変わりませんでした。
Kaggleへ標準化verのモデルをアップロード
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #002. logistic regression (normalized)"100%|████████████████████████████████████████| 2.77k/2.77k [00:04<00:00, 591B/s] Successfully submitted to Titanic - Machine Learning from Disaster
model #002. logistic regression (normalized) 0.76076
なんと良くなりました。
標準化しなかった場合が、0.75837だったので少しよくなったようです。
まとめ
ロジスティック回帰の結果は標準化した場合で76%でした。
前回より精度が上がりました。
本当は変数の組み合わせやオプションの組み合わせを変更して色々試してみたいところです。
一通りの手法を試してみたらやってみたいと思います。
追記
ロジスティック回帰のパラメーターの最適化をクロスバリデーションで実施し、精度が若干向上しました。
