これまで表形式でタイタニックのデータの中身を俯瞰してきましたが、今回はグラフで可視化をして確認したいと思います。
グラフにすることによって色の違いや棒グラフの長さの違いなどが表現できることにより情報量が増え、よりデータ理解がしやすくなると思います。
② データの理解
ライブラリのインポートと描画設定
import numpy as np
import pandas as pd
import seaborn as sns
# 描画設定
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)分布確認 (数値データ)
Survived 891 non-null int64
Pclass 891 non-null int64
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
Survivedの分布を確認
sns.histplot(data=df, x="Survived", hue="Pclass",bins=20,stat="percent",multiple="stack",palette=sns.color_palette(n_colors=3))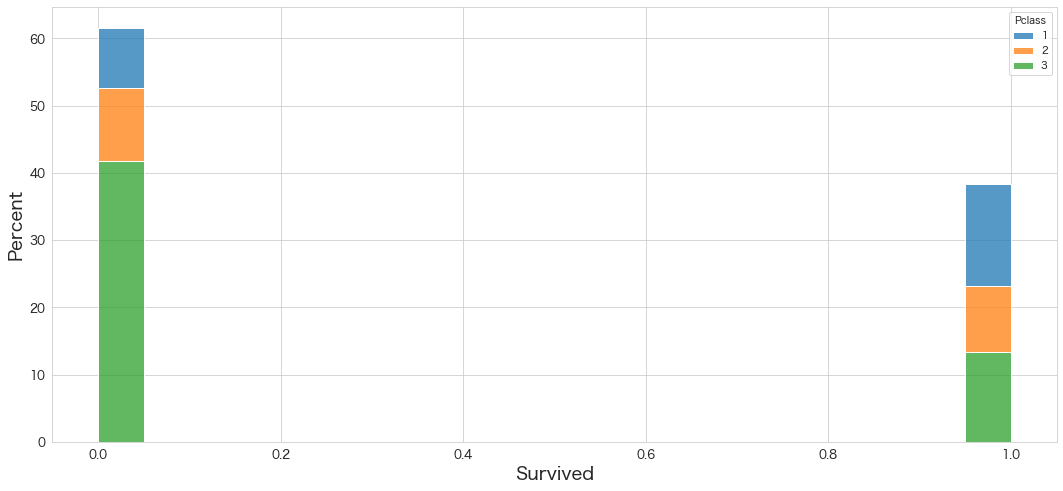
・訓練データの約30%が生存者のようです。
・非生存者の約40%が3rdクラスの乗客のようです。
Pclassの分布を確認
sns.histplot(data=df, x="Pclass", hue="Pclass",bins=20,stat="percent",multiple="stack",palette=sns.color_palette(n_colors=3))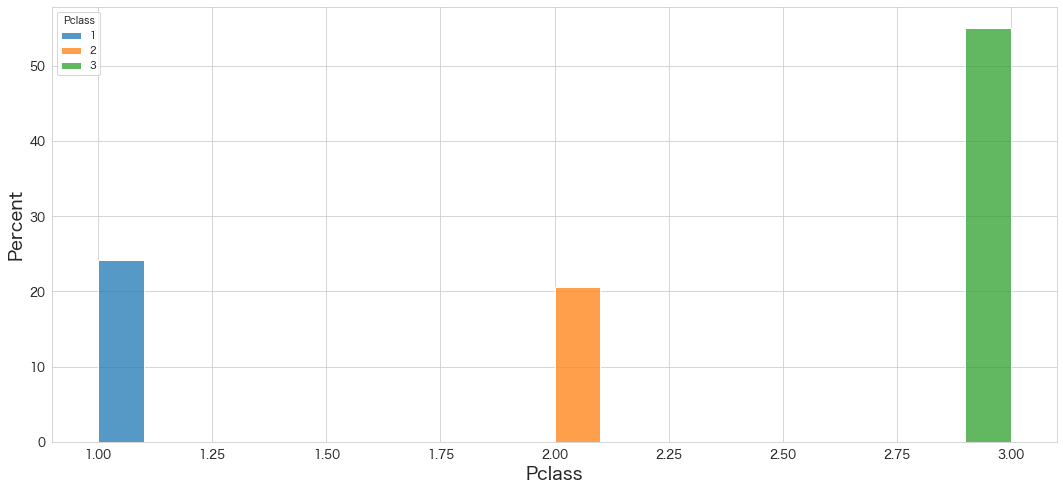
・3rdクラスの乗客が50%超のようです。
Ageの分布を確認
sns.histplot(data=df, x="Age", hue="Pclass",bins=20,stat="percent",multiple="stack",palette=sns.color_palette(n_colors=3))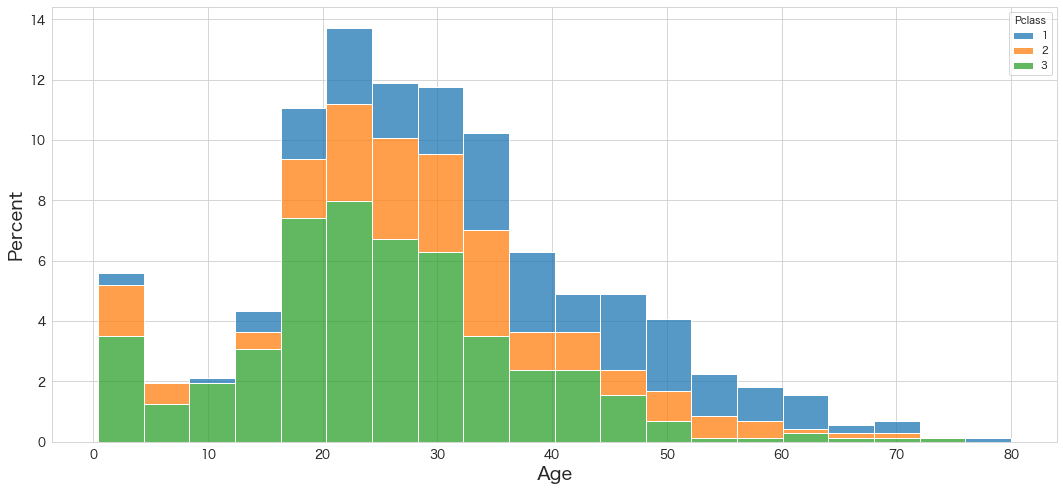
・10代後半から30代後半がボリュームゾーンのようです。
・1stクラスの乗客はあまり乳幼児は連れてきていないのか割合が低め。
・50代以上は3rdクラスの乗客割合は低めで、1stクラスの乗客割合が高め。
SibSpの分布を確認
sns.histplot(data=df, x="SibSp", hue="Pclass",bins=10,stat="percent",multiple="stack",palette=sns.color_palette(n_colors=3))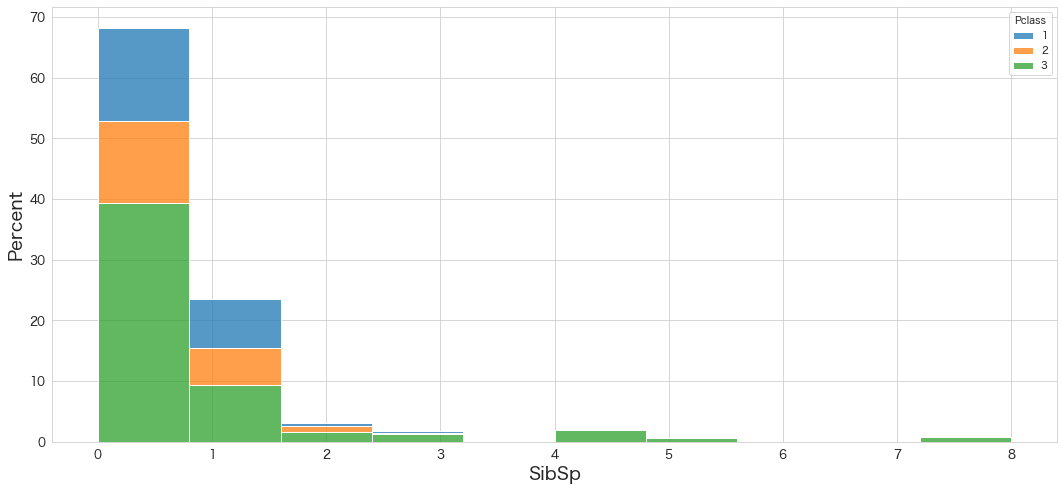
・0がほとんどの割合を占めていそう
・Pclass毎に違いはあまりなさそう。
Parchの分布を確認
sns.histplot(data=df, x="Parch", hue="Pclass",bins=10,stat="percent",multiple="stack",palette=sns.color_palette(n_colors=3))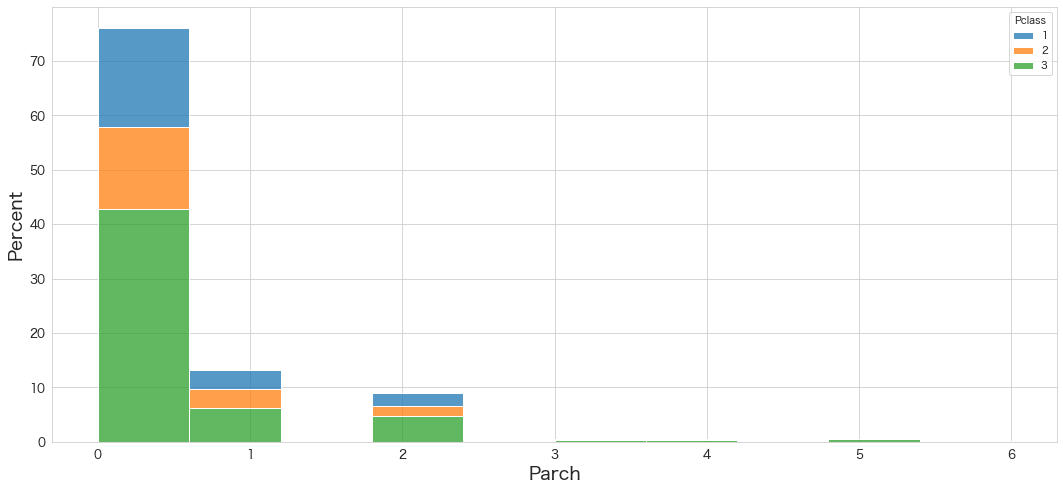
・0がほとんどの割合を占めていそう
・Pclass毎に違いはあまりなさそう。
Fareの分布を確認
sns.histplot(data=df, x="Fare", hue="Pclass",bins=100,stat="percent",multiple="stack",palette=sns.color_palette(n_colors=3))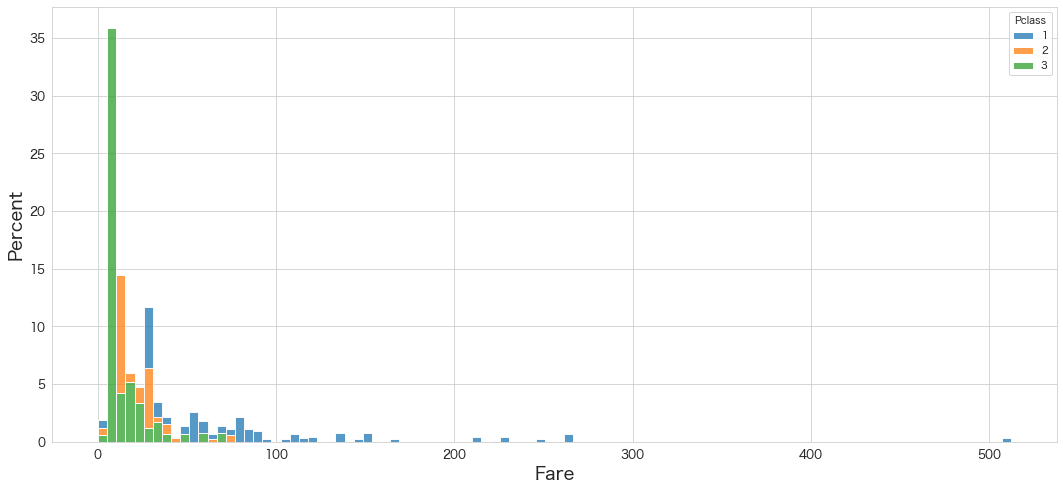
・当然ですが、高額の運賃は1stクラスの乗客が多い
・1stと2ndがほぼ同じ割合いる運賃が存在する。(一部3rdクラスもいる)
-> これは部屋のグレードは同じ?3rdクラスの人は1stクラスの付き添い?もしくは頑張って旅費を貯めた?
・3rdがメインの料金帯が存在していそう。35%ほど占めている。映画のジャック役のディカプリオはこの料金帯に宿泊したのかも知れません 笑
・0運賃も存在しているが、1st、2nd、3rdクラスそれぞれ同じくらいの割合が存在しているので乳幼児は無料とかなのかも知れません。
分布確認 (カテゴリデータ)
Sex 891 non-null object
Embarked 889 non-null object
Sexの分布の確認
import seaborn as sns
sns.countplot(x="Sex",data=df)
# or sns.histplot(x="Sex",data=df,hue="Sex") でも似たようなグラフが描画できる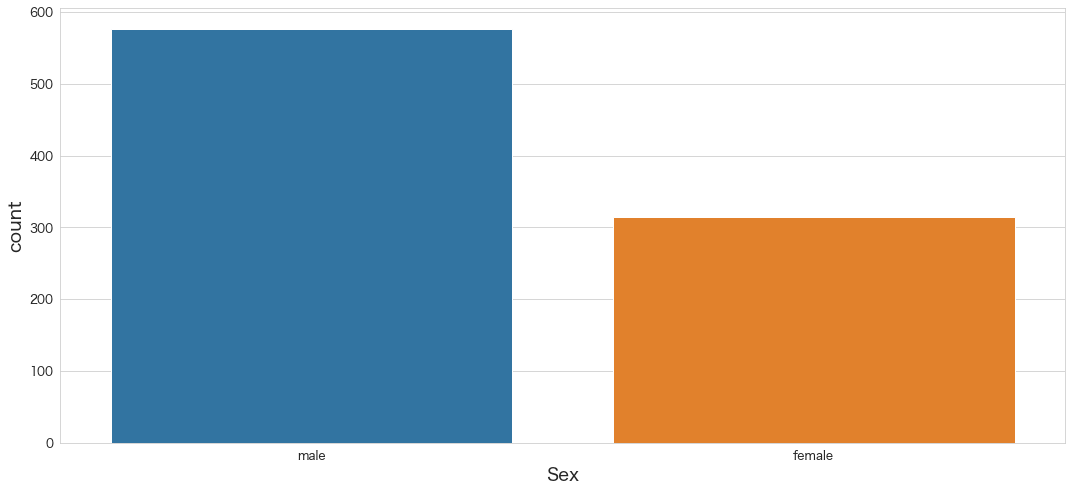
・男性の方が多い
# パーセンテージ表記
sns.histplot(x="Sex",data=df,stat="percent",hue="Sex")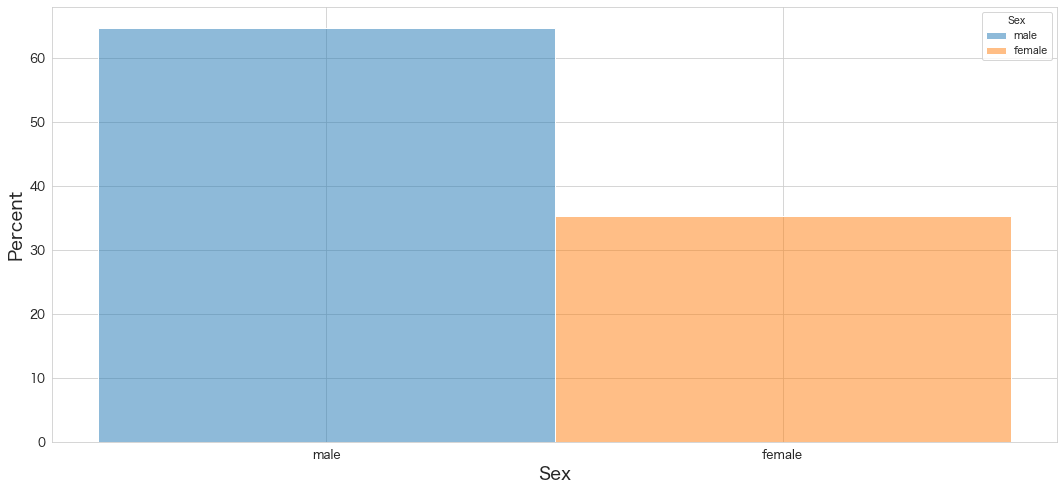
・男性の割合が60%強
Embarkedの分布の確認
sns.countplot(x="Embarked",data=df)
# or sns.histplot(x="Embarked",data=df,hue="Embarked") でも似たようなグラフが描画できる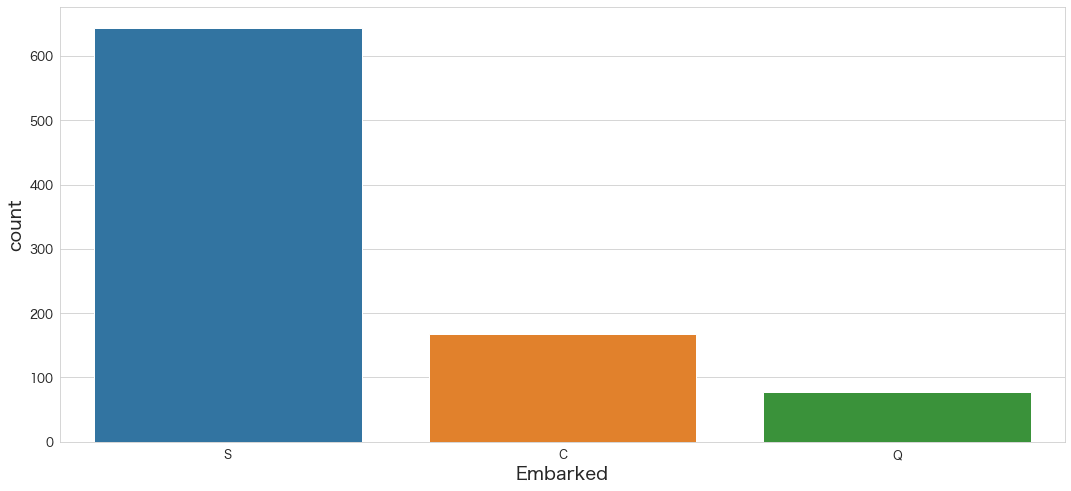
・Southampton > Cherbourg > Queenstown の順に多い
タイタニックはNew Yorkに向かう前に、Southampton → Cherbourg → Queenstown(現在Cobh)という順番で停泊
と以前書きましたが、停泊順と同じようです。
# パーセンテージ表記
sns.histplot(x="Embarked",data=df,stat="percent",hue="Embarked")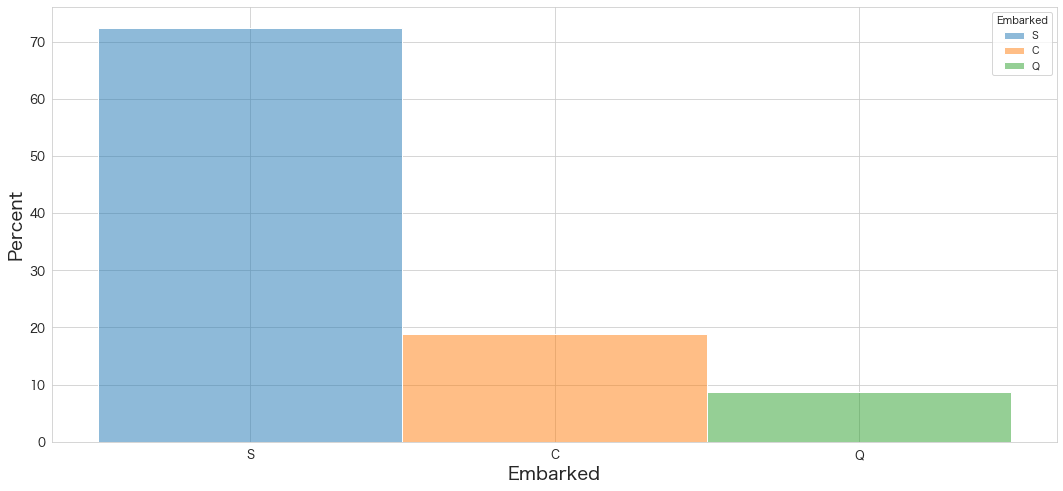
・Southamptonの港から乗った乗客が約70%強 (訓練データを確認した場合)
セグメント毎の分布を確認する。(Facetgridによる描画)
seabornではセグメント毎にグラフを簡単に描画することが出来ます。
relplot、catplot、displotでFacetgridによる描画が可能になっています。
グラフの種類もkindオプションで設定できるので、データに合う表現方法を試行錯誤して描画することも可能になります。
・relplot kind="scatter(default)" or "line"
・catplot kind="strip(default)" or "boxen" or "bar" or "count" and so on
・displot kind="hist(default)" or "kde" or "ecdf"
Pclass毎の生存・非生存の人数を確認
# Pclass毎の生存・非生存の人数を確認
sns.catplot(x="Survived", col="Pclass",col_wrap=3,data=df,kind="count")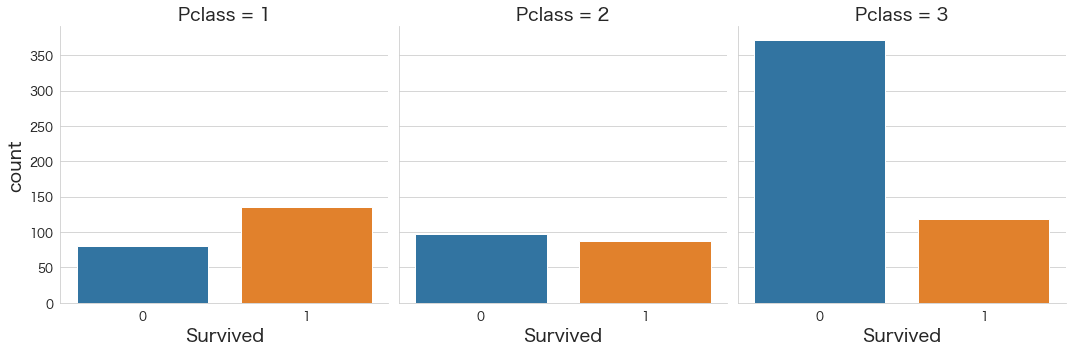
・3rdの非生存者数は多い
・各Pclass毎の生存者数の実数はそこまで差はないように見える
性別毎の生存・非生存の人数を確認
# 性別毎の生存・非生存の人数を確認
sns.catplot(x="Survived", col="Sex",col_wrap=2,data=df,kind="count")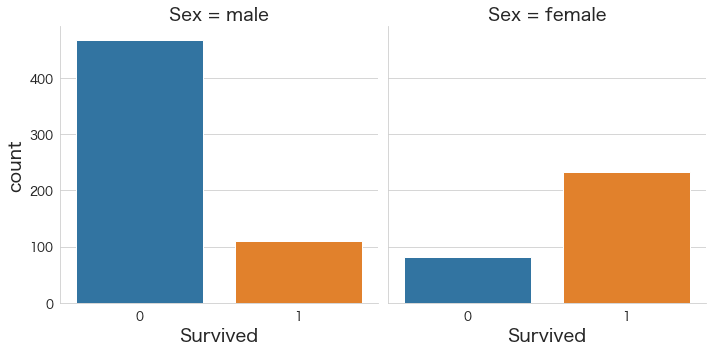
・女性の方が生存者数が多い
生存有無ごとの年齢分布の確認
# 生存有無ごとの年齢分布の確認
sns.displot(df, x="Age", col="Survived"
,multiple="stack" #積み上げ棒で確認
,hue="Pclass"
,palette=sns.color_palette(n_colors=3)
#,stat="percent" #割合で見たい場合
)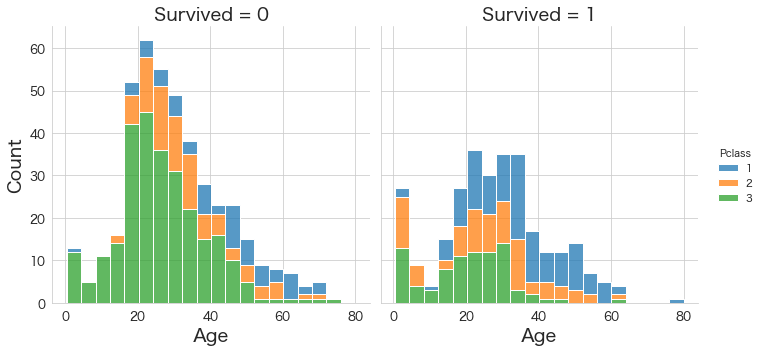
・乳幼児と思われる年代の生存者数は多いように見える。
・非生存の乳幼児も存在するが、救命ボートに乗れなかった赤ちゃんももしかしたらいるのかも知れない。
(映画の中では人が船の中で水流に飲み込まれているシーンも存在する。)
各主要ライブラリの利用バージョンを確認
import seaborn
import matplotlib
import pandas
import numpy
print("seaborn:",seaborn.__version__)
print("matplotlib:",matplotlib.__version__)
print("pandas:",pandas.__version__)
print("numpy:",numpy.__version__)
seaborn: 0.11.2
matplotlib: 3.5.1
pandas: 1.3.5
numpy: 1.22.1
まとめ
最初、旧ブログと同じように相関係数を求めたりグラフ化したりしましたが、今回のデータセットには合わず表現に失敗しました 笑
分類問題と回帰問題でデータの確認方法を分ける必要があるなと感じました。
次回からは、データの確認を一旦終わりにして、モデルを作成していこうと思います。
作成したモデルをKaggleにアップするというステップも踏んでいこうかなと思っています。
年齢、部屋の位置、性別、社会経済状況レベルは生存有無に効いてきそうだなという感覚はデータを確認することで持つことができたと思います。
この変数がXという値ならば生存だという確固たる変数は発見出来ませんでしたが、色々試していきたいと思います。