データの理解が進んだら次はデータの加工作業に入ります。
具体的にやる事を洗い出してみました。
主な作業としては下記が考えられます。
- 欠損値処理 (missing value processing)
- 外れ値処理 (outlier processing)
- 特徴量エンジニアリング (Feature Engineering)
- 変数選択 (Feature Selection)
- アンバランスデータの処理 (imbalaced data processing)
① 欠損値処理 (missing value processing)
欠損値があると基礎統計量が正しくなかったり、機械学習のモデル作成時に正常に処理されなかったりします。
また欠損値を正しい値で補完してあげると情報量が増え、モデルの精度にいい影響を与えてくれる要因の一つになると考えられます。
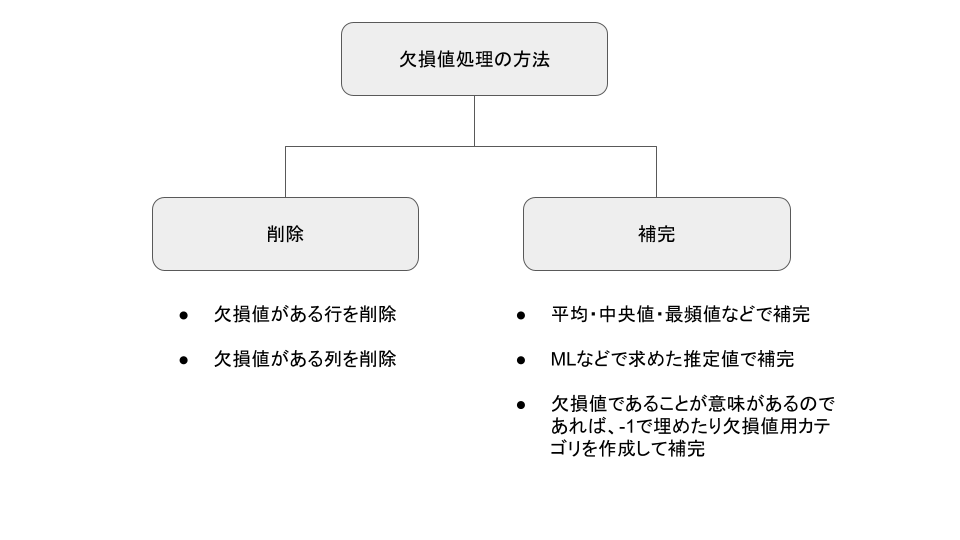
欠損値処理は、下記のような方法が考えられます。
- 行の削除
- 列の削除
- 平均、中央値、最頻値などで補完
- 推定値で補完
- -1や欠損値用のカテゴリで補完
図にすると下記のようになります。
② 外れ値処理 (outlier processing)
外れ値があることによって基礎統計量の結果や機械学習のモデルの精度に悪い影響がある場合があります。
そのため、外れ値を発見し処理することはモデリングパートでとても重要な作業の一つになります。
外れ値処理は、データを除外するか外れ値を考慮したデータ変換をするという方法があるようです。
具体的には下記のような方法が考えられます。
- データの可視化によって外れ値を見つけたら除外
- 1パーセンタイル以下/99パーセンタイル以上の値は除外((Trimmed estimator)もしくは置換 (Winsorizing)
- ロバストZスコアを計算し±3.5から外れる値は除外
- データを丸める (データ置換や区分作成をする)
- 対数を取る
- IQRで標準化(正規化)する
データ量が少なすぎて外れ値に見える場合もあります。
その場合はもっとデータが取得できないか考える必要があるかもしれません。
外れ値処理に関してはアメリカ国立標準技術研究所(NIST)の記事が参考になりました。
外れ値かどうかの検定として、Grubbs' Test、Tietjen-Moore Test、Generalized Extreme Studentized Deviate (ESD) Testという手法があるようなので、試してみようと思います。
Grubbs' Testは1つの外れ値の存在を検定する手法のようです。
検出した外れ値を除外しテストを繰り返すことによって外れ値を除外できるようですが、テストを繰り返す度に分布変更に伴い検知確率も変わってしまうので、複数の外れ値がありそうな場合はTietjen-Moore Testやgeneralized ESD Testを使う方がよいようです。
Grubbs's test detects one outlier at a time. This outlier is expunged from the dataset and the test is iterated until no outliers are detected. However, multiple iterations change the probabilities of detection, and the test should not be used for sample sizes of six or fewer since it frequently tags most of the points as outliers. 引用: https://en.wikipedia.org/wiki/Grubbs's_test
Tietjen-Moore Testはちょうどk個の外れ値を検出するテストです。 k=1の場合はGrubb's testと同じになるようです。
Generalized Extreme Studentized Deviate Testはk個以内の外れ値を検出するテストのようです。
generalized ESD TestはGrubb's Testを検出した値を除外しながらk回繰り返すのと基本的には変わりません。ただしkの値でcritical valueを適切に調整しているのでGrubb's Testそのものを複数回試行するのとは異なるようです。
The generalized ESD test makes approriate adjustments for the critical values based on the number of outliers being tested for that the sequential application of Grubbs test does not. 引用: https://www.itl.nist.gov/div898/handbook/eda/section3/eda35h3.htm
③ 特徴量エンジニアリング (Feature Engineering)
既存の変数を元に新しい特徴を持つ変数を抽出もしくは作成する作業です。
機械学習の精度向上に貢献すると考えられます。
例えば、複数の変数を組み合わせて新しい変数を作成したり、特定の長いログから意味ある文字列を抽出するといった作業になります。
目的変数の予測に寄与するであろう仮説を立てて作成することが多いので、事業ドメインの知識が必要になることが多いです。
以前、とある分析をしたときは、「土日祝の前の日フラグ」という変数を作成したら予測精度に微量に貢献してくれたことがありました。
④ 変数選択 (Feature Selection)
利用する変数を絞る作業です。
目的変数を予測するのに重要ではなさそうな指標を除外することによって計算量を減らしたり、多重共線性を防ぎ安定したモデルを作成するため相関が高い一方の変数は除外するといったことをします。
例えば、赤池情報量規準などを用いて一定の基準値を定めて利用変数の足切りをするといった方法があります。
多重共線性が存在することによる問題点は福山平成大学の福井教授の資料やいちばんやさしい、医療統計さんの記事が分かりやすかったです。
⑤ アンバランスデータの処理 (imbalaced data processing)
分類問題の場合に処理が必要になる場合があります。
例えばバイナリー問題で0か1かを当てるモデルを作成したい場合、0と1の比率が99:1の割合になっているとします。
このようにターゲットが偏っている場合、機械学習では0の特徴を多く学習し、1の特徴をあまり学習できないという状況になります。
このまま予測すると全て0と予測された場合でも正解率(Accuracy)が99%ほどになり一見精度が良いモデルができたと思われます。
しかし再現率(Recall)を見てみると、1を予測することが出来ず再現率が低いという使えないモデルになってしまう可能性があります。
正解率 = (TP + TN ) / (TP + FP + TN + FN)
再現率 = TP / (TP + FN)
アンバランスデータの処理は下記のような方法が考えられます。
- 0のレコードを減らす (Downsampling)
- 1のレコードを増やす (Upsampling)
- 1のレコードをコピーして増やす
- SMOTEという手法を使って増やす
- データの重み付け (Upweighting)
- 学習時に少ないデータ群の重要度を高くする
- 異常値検知などの手法を試す (anomaly detection)
まとめ
ここまでモデリングのためのデータ加工について書いてきましたが、除外するしないなどは色々な意見があると思います。
今回記事化するにあたり新しい知識なども増えました。今後の分析業務に役立てていきたいと思います。
最近は画像分析に業務がシフト気味なので、画像や動画分析系の記事も勉強して投稿して行こうと思っています。
参考
https://www.kaggle.com/code/parulpandey/a-guide-to-handling-missing-values-in-python
https://uribo.github.io/practical-ds/03/handling-missing-data.html
https://towardsdatascience.com/5-techniques-to-work-with-imbalanced-data-in-machine-learning-80836d45d30c
https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
https://www.kaggle.com/code/ramanchandra/handling-imbalanced-datasets/notebook
