今回から時系列データの分析に入りたいと思います。
データはSIGNATE社のデータ分析コンペでダウンロード出来る、アップル引っ越しセンターの引越し実績を利用したいと思います。
アップル引っ越しセンターは下記サイトになります。

IT化によってコスト削減をしお得な料金でサービスを提供することにより、売上実績も右肩上がりの企業のようです。
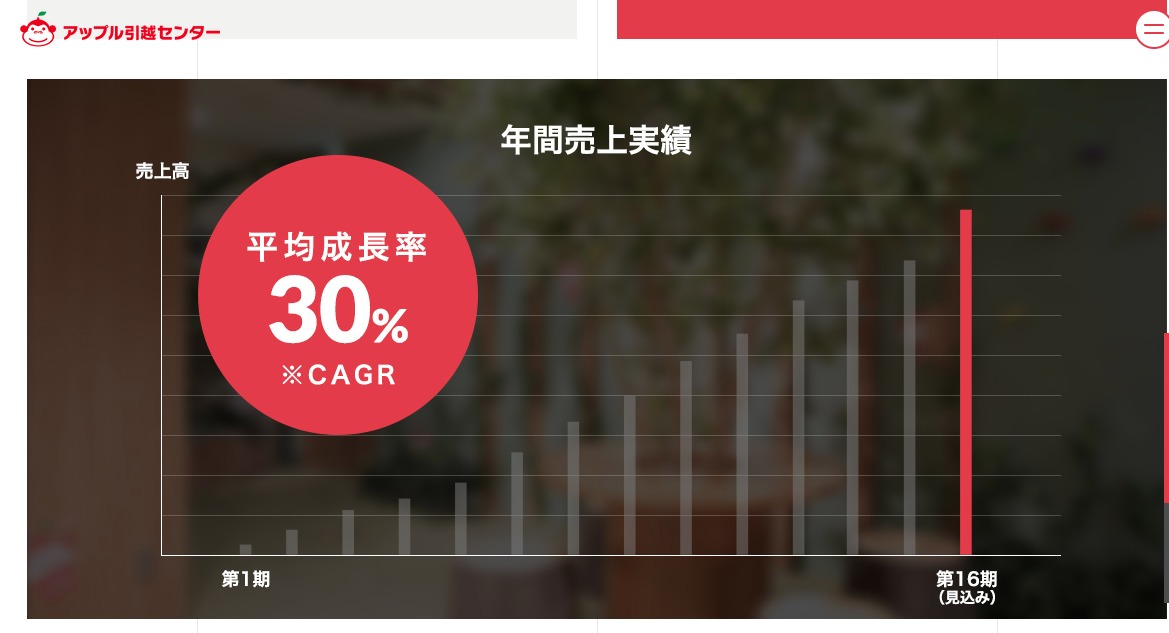
※ アップル引っ越しセンターのウェブサイトより抜粋
時系列分析とは
時系列予測は、既知の過去の事象に基づいて将来のモデルを構築し、将来ありうべきデータポイントを測定前に予測することである。例えば、株式の過去の価格推移から将来の価格を予測することなどが挙げられる。
引用: https://ja.wikipedia.org/wiki/時系列
例えば、仕入れやシフト決めのために次の一週間の売上や入電数を予測する場合に時系列分析をすることが事業会社では多いのではないでしょうか?
また特定の施策を実施した後の効果測定などで、「もし」施策を実施しなかった場合の売上を何かしらの仮定を置いて予測をするということも多々あるかと思います。
分析に携わっている方であれば一度はやる機会はありそうですね。
データマイニングプロセスについて
こんな手順で分析を進めていますという記事になります。

本記事はCRISP-DMの下記の部分を寄稿しています。
- ビジネスの理解
- データの理解
① ビジネスの理解
分析対象の事前知識をつける
コンペのサイトに引っ越し業界に関してコメントがありました。
年間を通して見ると、月別の移動者数(≒引越し者数)は特定の月に大きく偏っています。3月、4月が圧倒的に多く、3月は他の月のおよそ2.5倍、4月はおよそ2倍となっています。引越し会社は、おおよそこの繁忙期に稼ぎ、それ以外をなんとかしのいで年間収支を立てている状況です。これが一因で、繁忙期の引越し料金は高くなります。
参考: https://signate.jp/competitions/269
大学の新入生や会社の新卒など3~4月に引っ越すことが多いのでしょうか?
1年を通して引越し料金の推移を見ていくと、単身者の引越しが最も安いのは10月で、およそ3万円台後半の金額が相場です。
次に安い時期は12月~1月の年末年始で、荷物が少ない人で3.6万円~3.8万円、荷物が多い人で約4万円の料金です。
参考: https://hikkoshizamurai.jp/price/timing/
引越し侍というサイトから引用しました。やはり3~4月は繁忙期のようです。
また10月や年末年始はあまり引っ越す人はいないようです。
私は以前年末に引っ越したことがありました。確かに安かった記憶があります。
② データの理解
データの取得元
SIGNATEのアップル引越し需要予測のコンペデータになります。
分析対象のデータの確認
まずはどんなデータがありそうか変数を確認してみます。
カラム一覧
| カラム | 変数名 | 説明 | 内容 |
|---|---|---|---|
| 0 | datetime | 日時(YYYY-MM-DD) | |
| 1 | y | 引越し数 | 目的変数 |
| 2 | client | 法人が絡む特殊な引越し日フラグ | |
| 3 | close | 休業日 | |
| 4 | price_am | 午前の料金区分 | -1は欠損を表す。5が最も料金が高い |
| 5 | price_pm | 午後の料金区分 | -1は欠損を表す。5が最も料金が高い |
休業日はもちろん引越し数は0になるのではないかと思っています。
料金区分は日毎に決まっているのでしょうか?
データセットの読み込みと基礎統計量の確認
import pandas as pd
# 訓練データと予測付与用データの読み込み
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/applehikkoshi/train.csv",parse_dates=['datetime'])
df_test = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/applehikkoshi/test.csv",parse_dates=['datetime'])# infoメソッドでデータフレームの中身を確認
df.info()RangeIndex: 2101 entries, 0 to 2100 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 datetime 2101 non-null datetime64[ns] 1 y 2101 non-null int64 2 client 2101 non-null int64 3 close 2101 non-null int64 4 price_am 2101 non-null int64 5 price_pm 2101 non-null int64 dtypes: datetime64[ns](1), int64(5) memory usage: 98.6 KB
・datetimeはdatetime64として認識されているようです。
・欠損値はなさそうです。
# infoメソッドでデータフレームの中身を確認
df_test.info()RangeIndex: 365 entries, 0 to 364 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 datetime 365 non-null datetime64[ns] 1 client 365 non-null int64 2 close 365 non-null int64 3 price_am 365 non-null int64 4 price_pm 365 non-null int64 dtypes: datetime64[ns](1), int64(4) memory usage: 14.4 KB
・datetimeはdatetime64として認識されているようです。
・こちらも欠損値はなさそうです。
# 上から5件を確認
df.head()
datetime y client close price_am price_pm 0 2010-07-01 17 0 0 -1 -1 1 2010-07-02 18 0 0 -1 -1 2 2010-07-03 20 0 0 -1 -1 3 2010-07-04 20 0 0 -1 -1 4 2010-07-05 14 0 0 -1 -1
price_amとprice_pmはさっそく欠損値になっているようです。後ほどパーセンタイルを確認してどれくらい欠損割合があるか確認しようと思います。
# 上位5件を確認
df_test.head()
datetime client close price_am price_pm 0 2016-04-01 1 0 3 2 1 2016-04-02 0 0 5 5 2 2016-04-03 1 0 2 2 3 2016-04-04 1 0 1 1 4 2016-04-05 0 0 1 1
# 変数の統計量を確認
df.describe(include='all',percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,0.99],datetime_is_numeric=True).transpose()
count mean min 10% 20% 30% 40% 50% 60% 70% 80% 90% 95% 99% max std datetime 2101 2013-05-16 00:00:00.000000256 2010-07-01 00:00:00 2011-01-27 00:00:00 2011-08-25 00:00:00 2012-03-22 00:00:00 2012-10-18 00:00:00 2013-05-16 00:00:00 2013-12-12 00:00:00 2014-07-10 00:00:00 2015-02-05 00:00:00 2015-09-03 00:00:00 2015-12-17 00:00:00 2016-03-10 00:00:00 2016-03-31 00:00:00 NaN y 2101.0 34.096621 0.0 14.0 19.0 23.0 28.0 32.0 37.0 42.0 47.0 56.0 65.0 88.0 109.0 17.476234 client 2101.0 0.098049 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 0.297451 close 2101.0 0.012851 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 0.112658 price_am 2101.0 0.614469 -1.0 -1.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 2.0 3.0 5.0 5.0 1.12794 price_pm 2101.0 0.390766 -1.0 -1.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 2.0 4.0 5.0 0.975456
・price_amとprice_pmの約10%が欠損(-1)になっているようです。5も上位1%あるかないかくらいのようです。
・2010-07-01 ~ 2016-03-31までの期間が学習データのようです。
# 変数の統計量を確認
df_test.describe(include='all',percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,0.99],datetime_is_numeric=True).transpose()
count mean min 10% 20% 30% 40% 50% 60% 70% 80% 90% 95% 99% max std datetime 365 2016-09-30 00:00:00 2016-04-01 00:00:00 2016-05-07 09:36:00 2016-06-12 19:12:00 2016-07-19 04:48:00 2016-08-24 14:24:00 2016-09-30 00:00:00 2016-11-05 09:36:00 2016-12-11 19:12:00 2017-01-17 04:48:00 2017-02-22 14:24:00 2017-03-12 19:12:00 2017-03-27 08:38:24 2017-03-31 00:00:00 NaN client 365.0 0.452055 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.498379 close 365.0 0.013699 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 0.116396 price_am 365.0 0.794521 -1.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 2.0 2.0 4.36 5.0 1.00218 price_pm 365.0 0.586301 -1.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 2.0 2.0 4.0 5.0 0.958667
・予測付与用データのprice_amとprice_pmにも欠損(-1)があるようです。
・2016-04-01 ~ 2017-03-31までの期間が予測期間のようです。
どのような分析ができそうか
・引っ越し数の需要予測
・引っ越し数の要因分析
まとめ
とても分かりやすいデータかと思います。
日本の祝日なども時系列分析では重要なファクターになってくると思うので、国内のデータセットはとてもありがたいです。
実業務だと時間が足りなくて試せなかったことも色々調査しながらモデリングを進めていきたいと思います。
基本的にはKaggleのTime Seriesのレクチャーを参考にしてアップル引越しセンターのデータセットを分析していきたいと思います。
その他としては、
・ 状態空間モデル
・ Prophet
・ AutoML
・ Deep Learning (DeepAR、Temporal Fusion Transformerなど)
などを試してみたいなと考えています。(勉強しながらだから、時間かかるかな)
参考
・https://pytorch-forecasting.readthedocs.io/en/stable/tutorials/stallion.html
・https://ai.googleblog.com/2021/12/interpretable-deep-learning-for-time.html