今回はランダムフォーレスト(random forest)になります。
旧ブログでも割とアクセスがあった手法になります。

大学の授業や会社での勉強などでとりあえず使ってみたいという方は上から順に実行すれば動くはずですのでぜひお試しください。
旧ブログではボストンの住宅価格のデータセットでしたが、エイムズの住宅価格のデータセットだとどういう結果になるのか楽しみです。
ボストンの住宅価格で試したときはオーバーフィットしてしまったのでクロスバリデーションや変数選択をきちんとしてモデリングした方がいいのかも知れません。
オーバーフィットを防ぐ方法は8 Simple Techniques to Prevent Overfittingの記事に詳しくまとまっています。下記抜粋しました。
- Hold-out
- Cross-validation
- Data augmentation
- Feature selection
- L1 / L2 regularization
- Remove layers / number of units per layer
- Dropout
- Early stopping
・Hold-outは訓練データを80%を学習用、20%をテスト用に分割してモデリングする手法のようです。タイタニックのデータセットのときはHold-out手法でやっていましたね。確かに全データ利用するより精度がよかった場合もあった気がします。
・Cross-validationは前回の記事でサポートベクター回帰(SVR)のハイパーパラメータチューニングでグリッドサーチするときにk-分割交差検証を使いましたね。(k=5を指定した)
・Data augmentationは物体検知などで訓練画像を回転したりノイズを加えたりしてデータ量を増やす手法です (imgaugというライブラリを使うと簡単に出来ます)。画像以外の話だと分類問題などでターゲットなる数(タイタニックでいうところの生存者数など)があまりにも少ない場合は水増ししたりする場合があるかと思います。
・Feature selectionは重回帰分析のときに相関係数ベースでやりましたが、参考記事だと変数減少法を紹介してくれていますね。他にもステップワイズ法とかよくデータマイニングツール(SPSS Modelerとか)でも実装されていたので使っていました。
・L1 / L2 regularizationはロジスティック回帰のときに出てきましたね。
・Remove layersはニューラルネットワークとかディープラーニングを利用するときの話ですかね?
・DropoutとEarly stoppingもニューラルネットワークの場合を想定しているようですが、random forestでは変数を選択した上で弱分類器をいくつも作成しているのでDropoutみたいなものだというコメントがありました。
One simplest example of dropout being used in other algorithms is random forest: At each step of random forest, you randomly select only several of the features to split your trees, this is totally equivalent to randomly dropping out some of the features as in neural network.
引用:https://stats.stackexchange.com/questions/261758/is-there-something-analogous-to-dropout-for-classification-problems
またこちらの記事ではearly stoppingをアンサンブル木モデル用に実装されているようなのでRandom Forestでも適用可能かと思います。
それでは前置きが長くなってしまいましたが、Random Forestをやってみたいと思います。過学習対策は上記8つのうちどれかを実施するかグリッドサーチ以外のハイパーパラメーターチューニングの方法を試してみようと思います。
評価指標
住宅IdごとのSalePrice(販売価格)を予測するコンペです。
評価指標は予測SalePriceと実測SalePriceの対数を取ったRoot-Mean-Squared-Error(RMSE)の値のようです。

ランダムフォーレスト分析
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
(その3-2) エイムズの住宅価格のデータセットのデータ加工①
(その3-3) エイムズの住宅価格のデータセットのデータ加工②
学習用データとスコア付与用データの読み込み
import pandas as pd
import numpy as np
# エイムズの住宅価格のデータセットの訓練データとテストデータを読み込む
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/ames_train.csv")
df_test = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/ames_test.csv")df.head()
Id LotFrontage LotArea LotShape Utilities LandSlope OverallQual OverallCond MasVnrArea ExterCond ... SaleType_New SaleType_Oth SaleType_WD SaleCondition_Abnorml SaleCondition_AdjLand SaleCondition_Alloca SaleCondition_Family SaleCondition_Normal SaleCondition_Partial SalePrice 0 1 65.0 8450 3.0 3.0 2.0 7 5 196.0 2.0 ... 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 208500 1 2 80.0 9600 3.0 3.0 2.0 6 8 0.0 2.0 ... 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 181500 2 3 68.0 11250 2.0 3.0 2.0 7 5 162.0 2.0 ... 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 223500 3 4 60.0 9550 2.0 3.0 2.0 7 5 0.0 2.0 ... 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 140000 4 5 84.0 14260 2.0 3.0 2.0 8 5 350.0 2.0 ... 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 250000 5 rows × 335 columns
# 描画設定
from IPython.display import HTML
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)ランダムフォーレストに使用する変数を選ぶ
とりあえず全て突っ込んでみます
ランダムフォーレストで学習を実施 (デフォルト設定)
# 説明変数と目的変数を指定
# 学習データ
X_train = df.drop(["Id","SalePrice"],axis=1)
Y_train = df["SalePrice"] # 販売価格
# テストデータ
X_test = df_test.drop(["Id"],axis=1)# https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
from sklearn.ensemble import RandomForestRegressor
# モデル作成
regr = RandomForestRegressor(random_state=1414)
# フィット
regr.fit(X_train,Y_train)
# モデルパラメータ一覧
regr.get_params()
{'bootstrap': True,
'ccp_alpha': 0.0,
'criterion': 'squared_error',
'max_depth': None,
'max_features': 1.0,
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 100,
'n_jobs': None,
'oob_score': False,
'random_state': 1414,
'verbose': 0,
'warm_start': False}
# 訓練データに対して精度を確認
regr.score(X_train,Y_train)0.9824621850303301
テストデータの精度が分からないのですが、訓練データに対して当てはまりが良すぎる気もします。オーバーフィットしている可能性があります。
### モデルを適用し、SalePriceの予測をする
df_test["SalePrice"] = regr.predict(X_test)df_test[["Id","SalePrice"]]
Id SalePrice 0 1461 125463.59 1 1462 165890.20 2 1463 181404.59 3 1464 181079.84 4 1465 193371.04 ... ... ... 1454 2915 86776.00 1455 2916 85120.02 1456 2917 163315.40 1457 2918 122183.96 1458 2919 230860.49 1459 rows × 2 columns
# SalePriceの分布を確認
sns.histplot(df_test["SalePrice"],bins=20)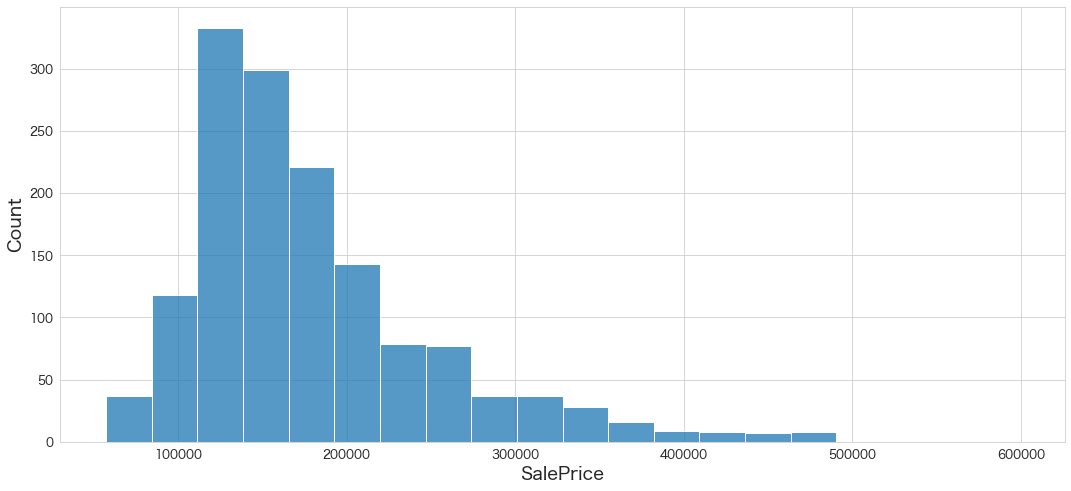
予測できていそうです。
Kaggleにスコア付与結果をアップロード
df_test[["Id","SalePrice"]].to_csv("ames_submission.csv",index=False)!/Users/hinomaruc/Desktop/blog/my-venv/bin/kaggle competitions submit -c house-prices-advanced-regression-techniques -f ames_submission.csv -m "#6 random forest normal"100%|██████████████████████████████████████| 21.0k/21.0k [00:03<00:00, 5.83kB/s] Successfully submitted to House Prices - Advanced Regression Techniques #6 random forest normal Score: 0.14680
多項式回帰を抜いて暫定1位となりました。意外にもいい結果になりました。
使用ライブラリのバージョン
pandas Version: 1.4.3
numpy Version: 1.22.4
scikit-learn Version: 1.1.1
seaborn Version: 0.11.2
matplotlib Version: 3.5.2
まとめ
デフォルトのままでもそれなりの精度が出ました。
次回はパート2として、ベイズ最適化(Bayesian Optimization)によるランダムフォーレストのパラメーターチューニングをしてみたいと思います。
グリッドサーチでも良かったのですが、もう一歩レベルアップしたかったので頑張ります。
