YOLOv8で画像や動画内の特定のエリアのみを物体検知の対象とする方法を試してみたいと思います。
実業務だとやることが多いのではないでしょうか?今回はYouTube動画の「Object Detection 101 Course - Including 4xProjects | Computer Visionを参考にしました。
やり方としては事前に検知したい領域を白色、検知したくない領域を黒色に塗った画像を用意して物体検知する前にマスク画像として元画像にオーバーラップしてあげるだけのようです。
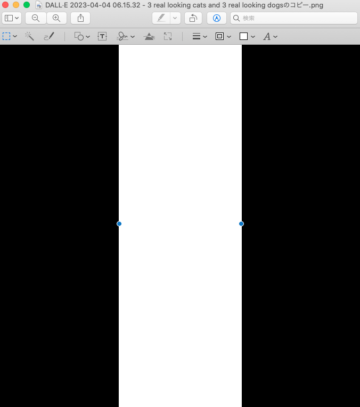
物体検知用の画像は分かりやすい猫と犬が並んだ下記画像を使います。真ん中の猫ちゃんのみ検知の対象とするように、猫の領域を白色、その他の領域を黒色の画像を事前に準備します。(元画像と同じ大きさの画像で作成します。)
※ 私がDALL-Eで作成した画像なので、ダウンロードしてご自由にお使いください。
YouTube動画だとCanvasというウェブサービスを使っていましたが、Macで普通にPreview.appを使って作成することが出来ました。

前回の記事は下記になります。本記事で検知結果の描画に同じようなコードを使っているので見ておくと少し分かりやすくなるかも知れません。
https://www.hinomaruc.com/displaying-results-of-object-detection-with-yolov8/
まずは元画像に対して物体検知を実行する
まずは通常バージョンです。特に領域の指定はしないで物体検知をしてみます。
from ultralytics import YOLO
from PIL import Image
import cv2
import matplotlib.pyplot as plt
# 事前学習済みのモデルを読み込み(detectionモデルを使用)
model = YOLO('yolov8n.pt')
# 画像の読み込み
img = cv2.imread("/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.15.32 - 3 real looking cats and 3 real looking dogs.png")
# predictモードを実行
results = model.predict(source=img,
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True)
# Reusltsオブジェクトのplotメソッドでndarrayを取得
res_plotted = results[0].plot()
# matplotlibなどはRGBで表現、opencvはBGRで表現。matplotlibで描画するためRGBに変換する
res_plotted_rgb = cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB)
# matplotlibで描画
plt.imshow(res_plotted_rgb)
plt.axis('off')
plt.show()0: 640x640 2 cats, 4 dogs, 512.0ms
Speed: 3.4ms preprocess, 512.0ms inference, 2.2ms postprocess per image at shape (1, 3, 640, 640)

猫と犬がきちんと検知できているようですね。毎回両端の犬のエリアには犬しかいないと仮定します。
そうすると真ん中のエリアだけ物体検知の対象エリアとすればいいので処理効率も向上しますね。
あと今気づきましたが、元画像は1024x1024なのにpredict時の画像サイズが640x640になっていますね。predictするときにresizeしてくれているのかも知れません。事前学習済みのモデル(yolov8n.pt)を使っていますが、640pxの画像を使用しているためかも知れません。
真ん中の領域だけ物体検知対象とする
事前にmask.pngを作成しておきます。(冒頭で紹介した「図: オーバーラップ用画像 mask.png (白色の領域だけ物体検知対象とする)」の画像です。)
# マスク画像の読み込み
mask = cv2.imread("/Users/hinomaruc/Desktop/blog/dataset/aidetection/mask.png")
# mask.pngの白いエリアを物体検知対象とする。
imgRegion = cv2.bitwise_and(img,mask)
# predictモードを実行
results = model.predict(source=imgRegion,
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True)0: 640x640 2 cats, 408.3ms
Speed: 5.7ms preprocess, 408.3ms inference, 1.8ms postprocess per image at shape (1, 3, 640, 640)

ちゃんと真ん中の猫ちゃんのみ物体検知の対象となりました。(犬の領域は黒く塗りつぶされています)
検知結果も「0: 640x640 2 cats, 408.3ms」だけになりました。
これだけもいいのですが、ちょっと見栄えが悪いですね 笑
バウンディングボックスは元の画像に対して配置したいこともあるかも知れません。
バウンディングは元の画像に対して配置する
from ultralytics import YOLO
from PIL import Image, ImageDraw, ImageFont
import cv2
import matplotlib.pyplot as plt
# 事前学習済みのモデルを読み込み(detectionモデルを使用)
model = YOLO('yolov8n.pt')
# 画像の読み込み
img = cv2.imread("/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.15.32 - 3 real looking cats and 3 real looking dogs.png")
# マスク画像の読み込み
mask = cv2.imread("/Users/hinomaruc/Desktop/blog/dataset/aidetection/mask.png")
# mask.pngの白いエリアを物体検知対象とする。
imgRegion = cv2.bitwise_and(img,mask)
# predictモードを実行
results = model.predict(source=imgRegion,
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True)
# Resultsオブジェクトから描画に必要な情報を取得
coordinate_bbox = results[0].boxes.xyxy #bbox
classes=results[0].boxes.cls # 検出クラス
classes_map = results[0].names # クラス番号と名称
confs=results[0].boxes.conf # 確信度
# 元画像をPILに変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_pil = Image.fromarray(img)
# 元画像に対してお絵かきする。描画コンテントの取得
draw = ImageDraw.Draw(img_pil)
# フォントの設定。Macだと/System/Library/Fontsに色々あるのでここから選んだ。
font = ImageFont.truetype('ヒラギノ丸ゴ ProN W4', 30)
# バウンディングボックスの描画
i=1
for bbox, cls, conf in zip(coordinate_bbox, classes, confs):
# bboxの位置情報 (xyxy形式)
x1, y1, x2, y2 = map(int, bbox)
# bboxの描画
draw.rectangle([x1, y1, x2, y2], outline="red", width=5)
# クラス名と確信度の加工
cls_text = classes_map.get(int(cls))
conf_text = str(round(float(conf),2))
# 検出クラス名と確信度の描画
draw.text((x1, y1 - 30), cls_text+"#"+str(i)+" "+ conf_text, fill="black",font=font)
i += 1
# ndarrayに変換
img_np = np.array(img_pil)
# 描画
plt.imshow(img_np)
plt.axis('off')
plt.show()0: 640x640 2 cats, 402.9ms
Speed: 3.4ms preprocess, 402.9ms inference, 1.8ms postprocess per image at shape (1, 3, 640, 640)

美しいですね。元画像に対して、真ん中の領域のみ物体検知をすることが出来ました。
まとめ
特定のエリアや領域だけ物体検知をしたいということはよくあるのではないでしょうか?
今回参考にしたYouTube動画では道路やエスカレーターの動画を使って領域を絞った物体検知をしていました。
かなり勉強になったので、色々プログラミング・機械学習・AIなどで参考になるリンク集みたいなのを作ってもいいのかなと思いました。(無料/有料問わず)
次はIoUやmAPなどモデルの精度を確認する記事を書きたいなと思っています。個人的にはAIモデルを作成する上で作成したモデルを比較することが多いので一番まとめておきたいパートになります。
今回、特定エリアや領域のみで物体検知をすることが出来たので、特定領域の精度を確認するなんてところもやってみたいなと考えています。

