前回、KNNで76.5%の精度でした。
今回はロジスティック回帰CVを使って予測してみようと思います。
(その4-2) タイタニックの乗客の生存有無をロジスティック回帰分析で予測してみたと似ていますが今回はロジスティック回帰CVを使ってみます。
クロスバリデーションによってモデルの精度を向上させるパラメーターを探索できるようです。
For the grid of Cs values and l1_ratios values, the best hyperparameter is selected by the cross-validator
参考: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegressionCV.html
Cの値とl1_ratiosのパラメータ値を探索できるようです。
Cは正則化の具合を表し、l1_ratiosはL1正則化とL2正則化の比率の調整が可能なようです。(0がL2正則化100%、1がL1正則化100%ということのようです。)
それではやってみましょう。
評価指標
タイタニックのデータセットは生存有無を正確に予測できた乗客の割合(Accuracy)を評価指標としています。
ロジスティック回帰CV
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
学習データと評価データの読み込み
import pandas as pd
import numpy as np
# タイタニックデータセットの学習用データと評価用データの読み込み
df_train = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_train.csv")
df_eval = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_eval.csv")概要確認
# 概要確認
df_train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 891 non-null object
12 FamilyCnt 891 non-null int64
13 SameTicketCnt 891 non-null int64
14 Pclass_str_1 891 non-null float64
15 Pclass_str_2 891 non-null float64
16 Pclass_str_3 891 non-null float64
17 Sex_female 891 non-null float64
18 Sex_male 891 non-null float64
19 Embarked_C 891 non-null float64
20 Embarked_Q 891 non-null float64
21 Embarked_S 891 non-null float64
dtypes: float64(10), int64(7), object(5)
memory usage: 153.3+ KB
# 概要確認
df_eval.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 418 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 418 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
11 Pclass_str_1 418 non-null float64
12 Pclass_str_2 418 non-null float64
13 Pclass_str_3 418 non-null float64
14 Sex_female 418 non-null float64
15 Sex_male 418 non-null float64
16 Embarked_C 418 non-null float64
17 Embarked_Q 418 non-null float64
18 Embarked_S 418 non-null float64
19 FamilyCnt 418 non-null int64
20 SameTicketCnt 418 non-null int64
dtypes: float64(10), int64(6), object(5)
memory usage: 68.7+ KB
# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)モデル作成
# https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegressionCV.html
from sklearn.linear_model import LogisticRegressionCV
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Cは正則化の度合いを表し、Csは最適なパラメータを探すためintを指定するとint分のCの値を作成してくれる。
pipeline = make_pipeline(StandardScaler(), LogisticRegressionCV(Cs=1000,cv=5,random_state=0))Cs=10がデフォルト値でそのまま実行しても結果が変わらなかったため、Csを1000にしてみました。
CVは一旦デフォルト値である5のままで設定しています。
# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(df_train, test_size=0.20,random_state=100)
# 説明変数
FEATURE_COLS=[
'Age'
, 'Fare'
, 'SameTicketCnt'
, 'Pclass_str_1'
, 'Pclass_str_3'
, 'Sex_female'
, 'Embarked_Q'
, 'Embarked_S'
]
X_train = x_train[FEATURE_COLS] # 説明変数 (train)
Y_train = x_train["Survived"] # 目的変数 (train)
X_test = x_test[FEATURE_COLS] # 説明変数 (test)
Y_test = x_test["Survived"] # 目的変数 (test)# fitする
fit_pipeline = pipeline.fit(X_train,Y_train)モデルの精度の確認
# 訓練データへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
fit_pipeline.score(X_train,Y_train)0.8146067415730337
# テストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
fit_pipeline.score(X_test,Y_test)
0.7988826815642458
オーバーフィットはしていなさそうです。
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
print(confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(fit_pipeline,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[95 9]
[27 48]]
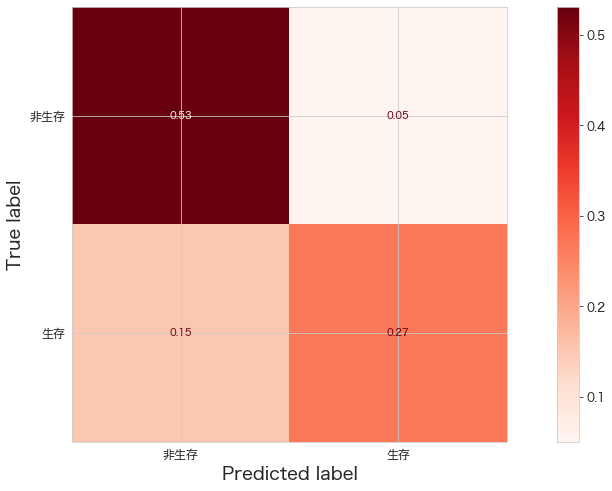
前回のロジスティック回帰の結果と比較してみます。
[[90 14]
[22 53]]
TN(非生存と予測し、非生存であった)の精度が若干向上したようです。逆にTPが下がってしまったようです。
オーバーフィットがなくなった影響でしょうか?Kaggleにアップロードすると結果はどうなるんでしょうね。
モデルのパラメータなどの確認
# pipelineのパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('standardscaler', StandardScaler()),
('logisticregressioncv',
LogisticRegressionCV(Cs=1000, cv=5, random_state=0))],
'verbose': False,
'standardscaler': StandardScaler(),
'logisticregressioncv': LogisticRegressionCV(Cs=1000, cv=5, random_state=0),
'standardscaler__copy': True,
'standardscaler__with_mean': True,
'standardscaler__with_std': True,
'logisticregressioncv__Cs': 1000,
'logisticregressioncv__class_weight': None,
'logisticregressioncv__cv': 5,
'logisticregressioncv__dual': False,
'logisticregressioncv__fit_intercept': True,
'logisticregressioncv__intercept_scaling': 1.0,
'logisticregressioncv__l1_ratios': None,
'logisticregressioncv__max_iter': 100,
'logisticregressioncv__multi_class': 'auto',
'logisticregressioncv__n_jobs': None,
'logisticregressioncv__penalty': 'l2',
'logisticregressioncv__random_state': 0,
'logisticregressioncv__refit': True,
'logisticregressioncv__scoring': None,
'logisticregressioncv__solver': 'lbfgs',
'logisticregressioncv__tol': 0.0001,
'logisticregressioncv__verbose': 0}
stepsの内容がlogisticregressioncvになっていますね。
# pipelineだと係数(model.coef_)が確認できないので、pipelineからモデル部分を取り出す
model_pipeline = fit_pipeline.named_steps["logisticregressioncv"] # or pipeline.steps[1][1]# モデル部分のパラメーターを確認。
model_pipeline.get_params()
{'Cs': 1000,
'class_weight': None,
'cv': 5,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1.0,
'l1_ratios': None,
'max_iter': 100,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': 0,
'refit': True,
'scoring': None,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 0}
# Array of C that maps to the best scores across every class
model_pipeline.C_
array([0.01061759])
1000個試したうち、Cの値は0.01061759が最適だったようです。
# 説明変数の係数を確認
coef = pd.DataFrame()
coef["features"] = fit_pipeline.feature_names_in_
coef["coef"] = model_pipeline.coef_[0]
coef["coef_pct"] = np.abs(coef["coef"]) / np.abs(coef["coef"]).sum()
coef.sort_values(by="coef_pct",ascending=False)
features coef coef_pct 5 Sex_female 0.672601 0.386159 4 Pclass_str_3 -0.342294 0.196520 3 Pclass_str_1 0.208327 0.119606 0 Age -0.185331 0.106404 1 Fare 0.149770 0.085987 7 Embarked_S -0.123741 0.071043 2 SameTicketCnt -0.054496 0.031288 6 Embarked_Q -0.005213 0.002993
寄与度の順番も変わりました。
Sex_female > Pclass_str_3 > Pclass_str_1 の順に寄与度が高くなったようです。
以前だとPclass_str_1よりAgeの方が寄与度が高かったです。
Kaggleへ標準化verのモデルをアップロード
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #005. logistic regressioncv (normalized) Cs=1000 CV=5"100%|████████████████████████████████████████| 2.77k/2.77k [00:05<00:00, 565B/s] Successfully submitted to Titanic - Machine Learning from Disaster
model #005. logistic regressioncv (normalized) Cs=1000 CV=5 0.76794
上がりました!
前回のロジスティック回帰の結果が0.76076、KNNの結果が0.76555なので暫定1位の精度です。
まとめ
クロスバリデーションでパラメータの調整をすることによって精度が上がることを確認できた。
またテストデータとして20%割り当てているが、非生存者を当てる精度があがっていた。
Kaggle側の評価用データでも、もしかしたら非生存者の方が多く0を1とする割合が減ったため精度が若干向上した可能性があります。
いままで1をどれくらい当てれるのかを気にしていましたが、コンペなどの精度を競う場合は正解ラベルが多い方を確率高く予測できた方がいいのかもしれません。
