前回、MNISTのデータセットを自作の多層パーセプトロンを使ってモデリングをしました。

今回は、畳み込みニューラルネットワーク(CNN)でMNISTの手書き数字の画像を判別できるかやりたいと思います。
CNNの構築にはGoogle社が公開しているTensorFlowというニューラルネットワークを簡単に構築できるツールを使います。
TensorFlow(テンソルフロー、テンサーフロー)とは、Googleが開発しオープンソースで公開している、機械学習に用いるためのソフトウェアライブラリである。... 機械学習や数値解析、ニューラルネットワーク(ディープラーニング)に対応しており、GoogleとDeepMindの各種サービスなどでも広く活用されている。
引用: https://ja.wikipedia.org/wiki/TensorFlow
※ 本記事を寄稿するにあたり、Convolutional Neural Networks with TensorFlow in PythonというUdemyのコースでCNNの概念を学び参考にしています。
※ CNNについては(その1) Pythonでニューラルネットワークを構築しながらディープラーニングを勉強してみるの記事にてまとめたことがありますので興味ある方はご覧ください。
TensorFlowを使用する環境の準備
# 仮想環境作成
python3.8 -m venv venv-tensorflow
source venv-tensorflow/bin/activate
# カーネルのインストール (別のjupyter notebookから呼び出す場合)
(venv-tensorflow) pip install pip -U
(venv-tensorflow) pip install ipykernel
(venv-tensorflow) python3 -m ipykernel install --user --name venv-tensorflow --display-name "venv-tensorflow"
# 必要なライブラリのインストール
(venv-tensorflow) pip install tensorflow
(venv-tensorflow) pip install tensorflow-datasets
(venv-tensorflow) pip install matplotlib
(venv-tensorflow) pip install -U scikit-learn
(venv-tensorflow) pip install pandasMNISTデータの読み込みと検証データの作成
MNISTは60000枚の学習データと10000枚のテストデータなので、検証データがありません。
学習の進捗を確認するのに必要なので、学習データを分割し検証データを作成します。
とりあえず10%分である6000枚を検証データとして割り当てようと思います。
無作為の割り当てるのではなく、数字の構成比を考慮し層別抽出を利用します。
import pandas as pd
df_train = pd.read_csv("https://pjreddie.com/media/files/mnist_train.csv",header=None)
df_test = pd.read_csv("https://pjreddie.com/media/files/mnist_test.csv",header=None)
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
from sklearn.model_selection import train_test_split
df_train_X = df_train.iloc[:,1:]
df_train_y = df_train[0]
X_test = df_test.iloc[:,1:]
y_test = df_test[0]
# 訓練データと検証データに分割する。層別抽出を有効にし、分割したデータセットのラベルの分布が近くなるようにする。
X_train, X_val, y_train, y_val = train_test_split(df_train_X,df_train_y, test_size=0.1, train_size=0.9, random_state=4649, shuffle=True, stratify=df_train_y)(備考) 層別抽出するのにStratifiedShuffleSplitを使っても良いです。慣れている方でOK
# StratifiedShuffleSplitを使うでも出来る
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedShuffleSplit.html
from sklearn.model_selection import StratifiedShuffleSplit
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.1, random_state=0)
sss.get_n_splits(df_train_X, df_train_y)
train_index,val_index = next(sss.split(df_train_X, df_train_y))分割したデータの分布の確認
層別抽出した結果を確認してみます。
"""
特定のカラムの分布を確認する
引数: pandas.core.series.Series
"""
def get_distribution(dataframe1d):
record_num = dataframe1d.value_counts().sum()
distribution = dataframe1d.value_counts().sort_index()
distribution_pct = distribution / record_num
distribution_tbl = pd.concat([distribution, distribution_pct], axis=1)
distribution_tbl.columns = ["ラベル数","ラベル割合"]
return distribution_tbl
print("訓練",get_distribution(y_train))
print("検証",get_distribution(y_val))訓練 ラベル数 ラベル割合 0 5331 0.098722 1 6068 0.112370 2 5362 0.099296 3 5518 0.102185 4 5258 0.097370 5 4879 0.090352 6 5326 0.098630 7 5638 0.104407 8 5266 0.097519 9 5354 0.099148 検証 ラベル数 ラベル割合 0 592 0.098667 1 674 0.112333 2 596 0.099333 3 613 0.102167 4 584 0.097333 5 542 0.090333 6 592 0.098667 7 627 0.104500 8 585 0.097500 9 595 0.099167
概ね同じような構成比になっているので、きちんと層別に抽出できているようです。
CNNモデルをTensorFlowで作成する
TensorFlowを使って、CNNモデルを構築していきます。
TensorFlowデータセットの作成
まずは、説明変数と目的変数をまとめたTensorFlowの「データセット」をpandasから作成します。
import tensorflow as tf
# 画像データとラベルを紐付け、一つにまとめたデータセットを作成
tf_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
tf_val = tf.data.Dataset.from_tensor_slices((X_val, y_val))
tf_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))print("train",len(tf_train))
print("val",len(tf_val))
print("test",len(tf_test))train 54000 val 6000 test 10000
想定通りの件数です。
(オプション) データセットではなく、TensorFlowオブジェクトを作成する方法
TensorFlowのオブジェクトを作成しsklearnチックにやる方法もあるが、記述量が多くなるし正規化する時のmap_fnメソッド利用時に動作が若干重かったので断念した。
# https://www.tensorflow.org/tutorials/load_data/pandas_dataframe?hl=ja
X_train_tf = tf.convert_to_tensor(X_train)
y_train_tf = tf.convert_to_tensor(y_train)
X_val_tf = tf.convert_to_tensor(X_val)
y_val_tf = tf.convert_to_tensor(y_val)
X_test_tf = tf.convert_to_tensor(df_test_X)
y_test_tf = tf.convert_to_tensor(df_test_y)
# 正規化
# https://www.tensorflow.org/api_docs/python/tf/map_fn#specifying_fns_output_signature
X_train_tf = tf.map_fn(fn=lambda t: tf.cast(t,tf.float32) / 255.0, elems=X_val_tf,fn_output_signature=tf.float32)
X_val_tf = tf.map_fn(fn=lambda t: tf.cast(t,tf.float32) / 255.0, elems=X_val_tf,fn_output_signature=tf.float32)
X_test_tf = tf.map_fn(fn=lambda t: tf.cast(t,tf.float32) / 255.0, elems=X_test_tf,fn_output_signature=tf.float32)データの前処理
CNNに渡す画像ピクセルデータを加工します。CNNでは最初に畳み込みレイヤーで28x28の形でデータを処理するので、1x784の形から28x28の形にnumpy配列を変形してあげます。
# 前処理
# map関数に渡す処理
def preprocessing(pixels, label):
pixels = tf.cast(pixels, tf.float32) # int -> floatへキャスト
pixels = pixels / 255.0 * 0.99 + 0.01 # 正規化
pixels = tf.reshape(pixels,[28,28,1]) #シェイプの変更
return pixels, label
tf_train = tf_train.map(preprocessing)
tf_val= tf_val.map(preprocessing)
tf_test= tf_test.map(preprocessing)
# ---lambda式を使う、下記の記載方法でも同じ結果になる。好みで使い分ける---
# tf_train = tf_train.map(lambda a, b: (tf.cast(a,tf.float32) / 255.0, b)) # 正規化
# tf_train = tf_train.map(lambda a, b: (tf.reshape(a,[28,28,1]), b)) # シェイプの変更for x, y in tf_train.take(1):
print("x.shape =",x.shape)
print("y =",y)
print("x =",x)x.shape = (28, 28, 1) y = tf.Tensor(6, shape=(), dtype=int64) x = tf.Tensor( [[[0.01 ] [0.01 ] [0.01 ] ・・・省略・・・ [0.02552941] [0.49529412] [0.98835295] ・・・省略・・・ [0.01 ] [0.01 ] [0.01 ]]], shape=(28, 28, 1), dtype=float32)
きちんと前処理されています。
(オプション) MNISTのデータを準備する方法として、tensorflow_datasetsを使う
tensorflow_datasetsを使えば、最初からTensorFlowデータセットに28x28の形で画像データが格納されているので、datasetsへの変更やシェイプの変更という作業必要ありません。
import tensorflow_datasets as tfds
mnist_dataset, mnist_info = tfds.load(name='mnist', with_info=True, as_supervised=True)学習・検証・テストデータへのバッチサイズの設定
バッチサイズとは1回のイテレーションで重み更新する時に使われる学習データセットの(今回だと)枚数になります。
ハイパーパラメータとなっており、全ての訓練画像をバッチサイズの数で分割し、1セットずつ学習しながら重みを更新していきます。
今回の例では訓練データに「128」のバッチサイズを設定すると、54000枚/128枚=422回イテレーションが実施されます。
この422回のイテレーションが1エポックという単位になり、次のエポックでは学習データがシャッフルされた上でまた128分割され、1セットずつ学習が行われます。
ここらへんの情報はカーブジェン社の「DeepLearning (上級編)」という記事で「バッチサイズ」・「イテレーション」・「エポック数」といった用語についてとても詳しく説明されていて分かりやすかったです。
何エポック学習したらいいのかもハイパーパラメーターになっていますが、TensorBoardといったツールで検証データへの当てはまり具合を確認しながら最適化したり、もうこれ以上学習が改善しそうにない(val_lossが減少傾向にない)場合、途中で中断する手法(early_stopping)などが使われます。
私はとりあえずエポック数を多く設定しておいて、TensorBoardでval_lossを確認して一番低い値と二番目に低い値になっているepoch数のモデルを選択し、テストデータセットへの精度がいい方を選択するということを繰り返し行っています。(自己流なのでアカデミック的に正しいかは不明です 笑)
また、検証データとテストデータのバッチサイズは今回は6000と10000を設定します。(つまり分割しない)
※ あまりデータ量が多すぎる場合だと学習に時間がかかるので、検証データも訓練データと同じようにバッチサイズを設定した方が良い場合があるかも知れません。
テストデータはMNISTの場合はそこまで気にしなくて良さそうですが、実業務では私はなるべく色々なパターンで確認したい派です。(例えば時間帯や天候などなるべく画像の種類や条件を豊富にして確認する)
BATCH_SIZE = 128
tf_train = tf_train.batch(BATCH_SIZE)
tf_val = tf_val.batch(len(tf_val))
tf_test = tf_test.batch(len(tf_test))
# バッチサイズ=128の確認
for x, y in tf_train.take(1):
print("x.shape =",x.shape)
print("y =",y)
print("x =",x)x.shape = (128, 28, 28, 1) y = tf.Tensor( [6 8 5 3 0 6 3 9 8 7 7 9 0 8 9 2 0 5 2 9 2 7 1 7 0 3 6 6 1 4 5 7 6 3 9 2 1 8 8 8 9 6 0 7 6 5 5 3 6 8 7 9 7 9 3 9 4 8 6 0 3 8 3 3 6 0 1 7 7 9 2 4 9 6 7 5 5 1 5 2 4 7 5 2 0 9 2 2 7 5 1 6 4 6 6 2 1 2 2 5 6 8 1 8 9 4 1 0 1 4 8 7 2 8 0 0 9 8 1 7 7 9 7 8 0 9 9 9], shape=(128,), dtype=int64) x = tf.Tensor( [[[[0.01] [0.01] [0.01] ・・・省略・・・ [0.01] [0.01] [0.01]]]], shape=(128, 28, 28, 1), dtype=float32)
x.shapeが(28, 28, 1)から(128, 28, 28, 1)に変化しましたね。バッチサイズが設定されたようです。
CNNモデルの作成
冒頭でも記載しましたが、「Convolutional Neural Networks with TensorFlow in Python」を参考にしています。
# CNNモデルのアーキテクチャ
# CONV -> MAXPOOL -> CONV -> MAXPOOL -> FLATTEN -> DENSE
# https://www.tensorflow.org/tutorials/images/data_augmentation?hl=ja#リサイズとリスケール
model = tf.keras.Sequential([
# tf.keras.layers.layers.Resizing(28, 28), # ここに画像の前処理を入れても良い
# tf.keras.layers.layers.Rescaling(1./255), # ここに画像の前処理を入れても良い
tf.keras.layers.Conv2D(50, 5, activation='relu', input_shape=(28, 28, 1)), # 50 kernels, 5x5 kernel
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.Conv2D(50, 3, activation='relu'), # 50 kernels, 3x3 kernel
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10) # softmax関数はここでは適用しない。
# モデルのサマリーを確認
model.summary(line_length = 75)Model: "sequential" ___________________________________________________________________________ Layer (type) Output Shape Param # =========================================================================== conv2d (Conv2D) (None, 24, 24, 50) 1300 max_pooling2d (MaxPooling2D) (None, 12, 12, 50) 0 conv2d_1 (Conv2D) (None, 10, 10, 50) 22550 max_pooling2d_1 (MaxPooling2D) (None, 5, 5, 50) 0 flatten (Flatten) (None, 1250) 0 dense (Dense) (None, 10) 12510 =========================================================================== Total params: 36,360 Trainable params: 36,360 Non-trainable params: 0 ___________________________________________________________________________
出力のシェイプを表示してくれるので分かりやすいですね。カーネルの数を50としたり、カーネル/フィルタを5x5や3x3にしていますがこちらは決まりはなくハイパーパラメータになっているので色々変更してみると面白いかも知れません。
※ Denseレイヤーでsoftmax関数を適用していませんが、どうやら損失計算をするときに結果が不安定になりやすいためのようです。そのため損失関数の中でsoftmax関数を取り入れるのが良いそうです。
オプティマイザーと損失関数の選択
損失関数としてSparseCategoricalCrossentropyを使います。
Computes the crossentropy loss between the labels and predictions.
引用:https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy
真のラベルの確率分布と予測のラベルの確率分布の誤差を最小化していくという感じでしょうか。
分かりにくいかも知れませんが下記の例だと、5という真のラベルを学習していくのに5か6かどっちか分からないというよりは5の確率が高くなるように学習していくというイメージを持ちました。
(0 # 1の確率
,0 # 2の確率
,0 # 3の確率
,0 # 4の確率
,1 # 5の確率
,0 # 6の確率
,0 # 7の確率
,0 # 8の確率
,0 # 9の確率
)
が真のラベルの確率分布だとすると、
(0 # 1の確率
,0 # 2の確率
,0 # 3の確率
,0 # 4の確率
,0.5 # 5の確率
,0.5 # 6の確率
,0 # 7の確率
,0 # 8の確率
,0 # 9の確率
)
よりも
(0 # 1の確率
,0 # 2の確率
,0 # 3の確率
,0 # 4の確率
,0.9 # 5の確率
,0.1 # 6の確率
,0 # 7の確率
,0 # 8の確率
,0 # 9の確率
)
交差エントロピー(cross entropy)をきちんと理解しないとイメージが掴めないので、分かりやすい簡単な例を「交差エントロピー誤差をわかりやすく説明してみる」で勉強させていただきました。
# https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy'])from_logits=Trueを有効にすることでsoftmaxを損失関数の中に取り入れてくれるようです。
オプティマイザーとはどう損失の最小値を求めていくか決めるアルゴリズムになります。
adamを使っていますが、他にも色々種類がありSGDやRMSpropなどがあります。
コールバックにearly stoppingを設定する
オーバーフィッティングを防ぐため、early stoppingという手法を取り入れます。
val_lossをモニターして、2回連続で上昇(つまり悪化)してしまったら学習を途中でストップすることが出来ます。
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor = 'val_loss',
mode = 'auto',
min_delta = 0,
patience = 2,
verbose = 0,
restore_best_weights = True
)MNISTデータの学習開始
epochsは5回に設定しています。前回の多層パーセプトロンと同じ。
# https://www.tensorflow.org/api_docs/python/tf/keras/Model#fit
model.fit(
tf_train,
epochs = 5,
callbacks = [early_stopping],
validation_data = tf_val,
verbose = 1
)Epoch 1/5 422/422 [==============================] - 49s 113ms/step - loss: 0.2662 - accuracy: 0.9248 - val_loss: 0.0908 - val_accuracy: 0.9733 Epoch 2/5 422/422 [==============================] - 50s 118ms/step - loss: 0.0697 - accuracy: 0.9793 - val_loss: 0.0651 - val_accuracy: 0.9797 Epoch 3/5 422/422 [==============================] - 47s 112ms/step - loss: 0.0511 - accuracy: 0.9842 - val_loss: 0.0564 - val_accuracy: 0.9823 Epoch 4/5 422/422 [==============================] - 47s 112ms/step - loss: 0.0415 - accuracy: 0.9880 - val_loss: 0.0519 - val_accuracy: 0.9842 Epoch 5/5 422/422 [==============================] - 47s 112ms/step - loss: 0.0350 - accuracy: 0.9898 - val_loss: 0.0483 - val_accuracy: 0.9858
イテレーションが422回、Epochが5回です。early_stoppingは今回はval_lossが減少し続けていたので適用されなかったようです。
epochsの回数を増やすと適用されることが確認できると思います。
CNNモデルの精度確認
作成したモデルの精度を確認します。
test_loss, test_accuracy = model.evaluate(tf_test)1/1 [==============================] - 3s 3s/step - loss: 0.0333 - accuracy: 0.9890
print(f'Testの精度は{round(test_accuracy*100,2)}%',)Testの精度は98.9%
accuracy: 0.9890と出ましたので、98.9%の精度になりました。多層パーセプトロンでは97.2%の精度でしたので、それより1ポイント以上高い結果になりました。
ラベルの予測
精度は分かりましたが、モデルの改善方法を探るためどの画像に対する予測が間違っていたかなどを確認したいと思います。
predictions = model.predict(tf_test)
predictions
array([[ -7.8892856 , -3.239093 , 0.7123865 , ..., 15.766534 ,
-4.2460704 , -0.3682075 ],
[ -2.2116098 , 4.528805 , 12.404316 , ..., -9.328034 ,
-0.8243198 , -14.474107 ],
[ -4.5307107 , 8.618059 , -2.1331122 , ..., -0.07124466,
-0.31579003, -2.4724116 ],
...,
[-10.233074 , -4.1696186 , -10.457555 , ..., -2.277219 ,
-0.4434953 , 0.05158324],
[ -4.0968466 , -12.384731 , -12.089455 , ..., -11.869525 ,
4.23404 , -9.862622 ],
[ -3.850579 , -7.330572 , -2.9499702 , ..., -14.045711 ,
-2.8259714 , -13.857165 ]], dtype=float32)
len(predictions2)10000
import matplotlib.pyplot as plt
import numpy as np
f = lambda x: tf.nn.softmax(x)
predictions2 = np.apply_along_axis(f, 1, predictions)
predictions2
array([[5.3260379e-11, 5.5712959e-09, 2.8977584e-07, ..., 9.9999046e-01,
2.0353190e-09, 9.8348131e-08],
[4.4897044e-07, 3.7978851e-04, 9.9961519e-01, ..., 3.6441264e-10,
1.7976690e-06, 2.1216971e-12],
[1.9459319e-06, 9.9900216e-01, 2.1398895e-05, ..., 1.6820877e-04,
1.3171769e-04, 1.5241761e-05],
...,
[2.6266080e-11, 1.1290691e-08, 2.0984766e-11, ..., 7.4916748e-08,
4.6876539e-07, 7.6906957e-07],
[1.0846916e-07, 2.7285009e-11, 3.6657285e-11, ..., 4.5674534e-11,
4.5015707e-04, 3.3983000e-10],
[1.3440248e-09, 4.1406181e-11, 3.3077718e-09, ..., 5.0201556e-14,
3.7444523e-09, 6.0617960e-14]], dtype=float32)
predictions2[0]
array([5.3260379e-11, 5.5712959e-09, 2.8977584e-07, 9.1932143e-06,
3.7749076e-13, 1.5832068e-10, 1.1634337e-17, 9.9999046e-01,
2.0353190e-09, 9.8348131e-08], dtype=float32)
7番目が0.999なので、画像は「7」である確率が99.9%で一番高いという意味になります。
import matplotlib.pyplot as plt
to_plot = X_test.iloc[0].to_numpy().reshape(28,28)
plt.imshow(to_plot, cmap='Greys')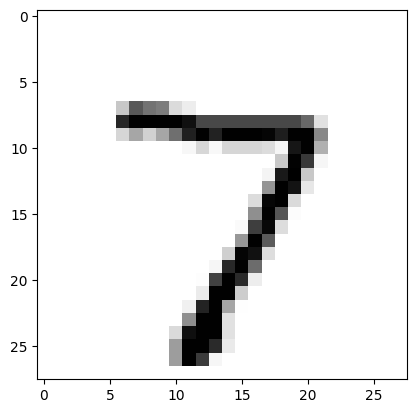
7でした 笑 当たってました。
f = lambda x: np.argmax(x)
predictions3 = np.apply_along_axis(f, 1, predictions2)
predictions3array([7, 2, 1, ..., 4, 5, 6])
手書き数字画像の予測リストが出来ました。正解データと比べてみます。
正誤表の作成
# 正誤表の作成
actual_predicts_table = pd.concat([y_test,pd.DataFrame(predictions3)], axis=1)
actual_predicts_table.columns = ["actual","predicts"]
actual_predicts_table["iscorrect"] = np.where(actual_predicts_table["actual"] == actual_predicts_table["predicts"], 1, 0)
# 正解率の算出
print ("performance = ", actual_predicts_table.iscorrect.sum() / len(actual_predicts_table))performance = 0.989
精度は当然98.9%です。
不正解だった画像の確認
actual_predicts_table[actual_predicts_table["iscorrect"] == 0]
actual predicts iscorrect
290 8 4 0
326 2 1 0
340 5 3 0
449 3 5 0
582 8 2 0
... ... ... ...
9729 5 6 0
9770 5 0 0
9792 4 9 0
9811 2 8 0
9893 2 3 0
to_plot = X_test.iloc[290].to_numpy().reshape(28,28)
plt.imshow(to_plot, cmap='Greys')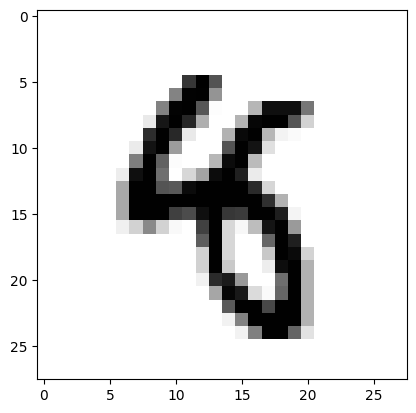
これは人間には8に見ますね。
to_plot = X_test.iloc[326].to_numpy().reshape(28,28)
plt.imshow(to_plot, cmap='Greys')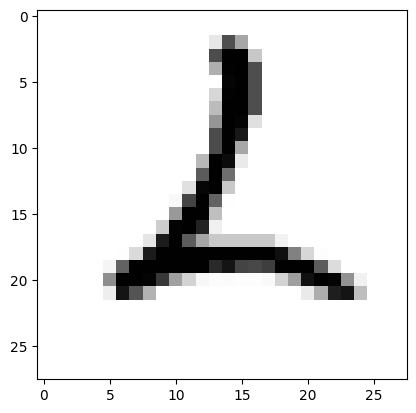
これも人間には2に見えますね。
ラベルごとの正答率を確認
label_accuracy = actual_predicts_table[["actual","iscorrect"]].groupby('actual').agg(['sum', 'count'])
label_accuracy["sum/count"] = label_accuracy.iloc[0:,0:1].values / label_accuracy.iloc[0:,1:2].values
label_accuracy
iscorrect sum/count
sum count
actual
0 975 980 0.994898
1 1132 1135 0.997357
2 1021 1032 0.989341
3 1007 1010 0.997030
4 973 982 0.990835
5 877 892 0.983184
6 947 958 0.988518
7 1011 1028 0.983463
8 959 974 0.984600
9 988 1009 0.979187
ばらつきはないようですが、「9」の認識率が若干弱いようです。
正解は9なのに予測を間違えた画像を確認する
# 9なのに他の数字と予測したものを抽出
wrong_nine = actual_predicts_table.loc[(actual_predicts_table.actual == 9) & (actual_predicts_table.iscorrect == 0)]
# 何の数字と間違えたのかカウント
wrong_nine["predicts"].value_counts()5 5 4 4 3 4 8 2 1 2 7 2 2 1 6 1 Name: predicts, dtype: int64
9は5や4と間違えてしまっているようです。
actual_predicts_table.loc[(actual_predicts_table.actual == 9) & (actual_predicts_table.predicts == 5)]
actual predicts iscorrect
1247 9 5 0
1709 9 5 0
2939 9 5 0
6091 9 5 0
6172 9 5 0
#subplot(row,column,pos)
to_plots=[
1247
, 1709
, 2939
, 6091
, 6172
]
for idx,number in enumerate(to_plots):
to_plot = X_test.iloc[number].to_numpy().reshape(28,28)
plt.subplot(2,3,idx+1)
plt.axis('off')
plt.imshow(to_plot, cmap='Greys')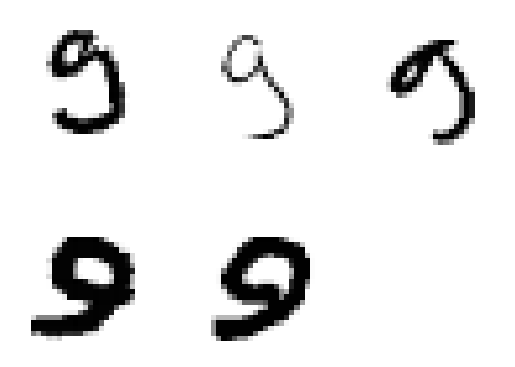
どうやら手書きなので数字が斜めになっているような画像を誤認識しているようです。
これだとData Augumentationといった手法を使って学習し直したり、テスト画像で数字が斜めになっている画像を真っ直ぐになるように加工するなどしたら認識するようになるかも知れません。
まとめ
長くなってしまいましたが、CNNでMNISTデータセットを学習してみました。
精度は多層パーセプトロンよりもよくなるという結果なので苦労したかいがありました 笑
ニューラルネットワークについて徐々に理解が深まってきました。
CNNの次はRCNNですかね?また勉強して以前の記事をアップデートしようと思います。
ライブラリのバージョン
tensorflow 2.11.0
matplotlib 3.7.1
sklearn 1.2.1
pandas 1.5.3
