今日はMNISTというデータセットを使います。MNISTはAT&T Bell LaboratoriesのYann LeCun, Corinna Cortes, and Christopher J.C. Burgesらによって、アメリカ国立標準技術研究所(NIST)が提供していた手書き文字のデータを再編成したデータとのことです。
MNISTデータについて調べてみた
前述から、MNISTデータはNISTデータを再構築したものになっているので、M(odified)NISTの略になっているようです。
修正の経緯などは、Wikipediaの記事「MNIST_database」にも概要が記載されていますが、もっと詳細を知りたい方はMNISTデータセットの作成経緯や方法などが記載されているAT&T Bell Laboratoriesの「LEARNING ALGORITHMS FOR CLASSIFICATION:A COMPARISON ON HANDWRITTEN DIGIT RECOGNITION」というペーパーを読むのがおすすめです。
NISTの手書き文字のデータはテストデータへの当てはまりが悪く、理由として考えられていたのは訓練データはUSの就業者から収集されていて、テストデータは(非協力的な)高校生たちから収集されていたためと書かれています。(Wikipediaにもそう記載がある。非協力的な高校生ばかりではないと思いますが 笑)
the training set consisted of characters written by paid US census workers,while the test set was collected from characters written by uncooperative high school students.引用: NetworksAndCNNClasifiersIntroVapnik95.pdf
ペーパーの中には訓練データとテストデータの代表的なサンプル画像が載せられていました。

個人的には確かにテストデータの中にはひどいものもありますが(特に左下らへんの文字)、上記サンプルだとどっちもどっちという気がしないわけでもないですね 笑
参考までにNISTの手書きデータは、訓練データは「NIST Special Database 3」、テストデータは「NIST Test Data 1」がという呼称で知られていたようです。
the training data was known as NIST Special Database 3, and the test data was known as NIST Test Data 1
引用: NetworksAndCNNClasifiersIntroVapnik95.pdf
「NIST Special Database 3」と「NIST Test Data 1」は「Machine-Assisted Human Classification of Segmented Characters For OCR Testing and Training」のペーパーによるとOCR認識用に作成されたようですね。 数字だけではなく、アルファベットのデータも存在するようです。もしかしたら上記のサンプル画像で数値に見えないのはアルファベットかも知れませんね 笑
The creation of SD3 ... The 30 numeric and alphabetic fields ... on the 2100 forms in SD1 were first isolated and then segmented
引用: https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=900672
The testing sets consist of set of 58,000 digits and 10,000 upper and lower case characters entered on formed by high school students and is distributed as Test Data 1.
引用: https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=900672
このような歴史を理解しつつ、MNISTの手書き数字のデータセットはNISTの手書き数字データのみを元に60,000枚の訓練データと10,000枚のテストデータで再構成され、全ての画像は正規化処理がされることによって現在は多くの分析者にベンチマークとして使われるデータセットになったようです。
MNISTデータの取得方法4選
4選といいつつ、実際は3選かも。
どの方法を使ってもいいですが、一番簡単なのは2番でしょうか。
1. 作成者のYannさんのwebページからの取得 (http://yann.lecun.com/exdb/mnist/)
下記4つのデータセットが公開されています。
・train-images-idx3-ubyte.gz: training set images (9912422 bytes)
・train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
・t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
・t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
ただし、ファイルの中身が0000 0803 0000 ea60 0000 001c 0000 001cのようなバイナリデータになっているのでnumpy.frombufferなどで1次元配列に変換してあげる必要がある。
2. keras.datasetsからの取得
Keras公式のサンプルにて詳細が載っています。
pip install keras
from keras.datasets import mnist
(train_X, train_y), (test_X, test_y) = mnist.load_data()データは指定がなければホームディレクトリの~/.keras/datasets/以下にダウンロードされるようです。
path: データをローカルに持っていない場合 ('~/.keras/datasets/' + path) ,この位置にダウンロードされます.
引用: https://keras.io/ja/datasets/#mnist
3. 「ゼロから作るDeep Learning」で公開されているMNISTデータ取得処理を使う
oreilly-japanのgithubで公開されています。ソースコードを見ると、データの取得元は1番のhttp://yann.lecun.com/exdb/mnist/ から取得しているようです。
mnist.pyの中のload_mnist functionを使えば取得から変換までしてくれます。
4. https://pjreddie.com/projects/mnist-in-csv/ からMNISTのCSVをダウンロードして利用
「ニューラルネットワーク自作入門」でMNISTデータセットを扱う演習のときに使うデータ。
こちらも元データはyann.lecun.comで公開されているデータになっており、CSVに変換済みのデータセットを公開してくれています。
変換方法もサイトに載っているので親切ですね。
ちなみに、pjreddle.comのMNISTデータセットから10件と100件をサンプリングしたデータをmakeyourownneuralnetworkのgithubで公開してくれているのでちょっとした動作確認で使うのに適しています。
データの読み込み
本記事では「ニューラルネットワーク自作入門」という本を参考にしているので、pjreddle.comのデータを使って分析していこうと思います。
import pandas as pd
df_train = pd.read_csv("https://pjreddie.com/media/files/mnist_train.csv",header=None)
df_test = pd.read_csv("https://pjreddie.com/media/files/mnist_test.csv",header=None)30秒くらいかかりますが、読み込まれます。headerはありません。
1列目がラベルデータになっていて、2列目以降が画像のピクセル値になっています。ラベルデータとは画像に対応する正解の数値になります。0だったら画像は0を表現していて、8だったら画像は8を表しているという意味になります。
28ピクセルx28ピクセルの画像データなので、列数は全部で785列あります(ラベル+ピクセル数(28*28=784))。
少しデータの中身を見てみましょう
df_train.head()
0 1 2 3 4 5 6 7 8 9 ... 775 776 777 778 779 780 781 782 783 784
0 5 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
2 4 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
3 1 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
4 9 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
5 rows × 785 columns
df_test.head()
0 1 2 3 4 5 6 7 8 9 ... 775 776 777 778 779 780 781 782 783 784
0 7 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
1 2 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
2 1 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
4 4 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
数字がたくさんですね。ちなみに、1行が1つの画像の情報を表しています。
# 訓練データの1枚目のピクセル値 (「5」を表現しているはず)
df_train.iloc[0:1,1:]
1 2 3 4 5 6 7 8 9 10 ... 775 776 777 778 779 780 781 782 783 784
0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
# 描画テスト (28x28のnumpyデータに変換)
draw_test = df_train.iloc[0:1,1:].copy(deep=True)
draw_test_np = draw_test.to_numpy().reshape(28,28)
draw_test_np
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3,
18, 18, 18, 126, 136, 175, 26, 166, 255, 247, 127, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 30, 36, 94, 154, 170,
253, 253, 253, 253, 253, 225, 172, 253, 242, 195, 64, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 49, 238, 253, 253, 253, 253,
253, 253, 253, 253, 251, 93, 82, 82, 56, 39, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 18, 219, 253, 253, 253, 253,
253, 198, 182, 247, 241, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 80, 156, 107, 253, 253,
205, 11, 0, 43, 154, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 14, 1, 154, 253,
90, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 139, 253,
190, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 11, 190,
253, 70, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 35,
241, 225, 160, 108, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
81, 240, 253, 253, 119, 25, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 45, 186, 253, 253, 150, 27, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 16, 93, 252, 253, 187, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 249, 253, 249, 64, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 46, 130, 183, 253, 253, 207, 2, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 39,
148, 229, 253, 253, 253, 250, 182, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 114, 221,
253, 253, 253, 253, 201, 78, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 23, 66, 213, 253, 253,
253, 253, 198, 81, 2, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 18, 171, 219, 253, 253, 253, 253,
195, 80, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 55, 172, 226, 253, 253, 253, 253, 244, 133,
11, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 136, 253, 253, 253, 212, 135, 132, 16, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]])
# 描画
import matplotlib.pyplot
matplotlib.pyplot.imshow(draw_test_np, cmap='Greys')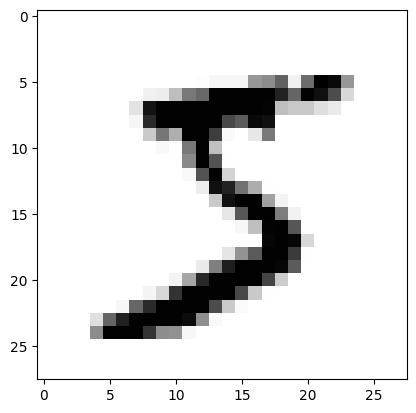
件数とラベルの分布くらい確認しておく
データセットの件数とラベルの分布くらい確認しておこうと思います。訓練データは6万枚、テストデータは1万枚あるはずです。
df_train.info()
print("---")
df_test.info()class 'pandas.core.frame.DataFrame'> RangeIndex: 60000 entries, 0 to 59999 Columns: 785 entries, 0 to 784 dtypes: int64(785) memory usage: 359.3 MB --- class 'pandas.core.frame.DataFrame'> RangeIndex: 10000 entries, 0 to 9999 Columns: 785 entries, 0 to 784 dtypes: int64(785) memory usage: 59.9 MB
60000 entriesと10000 entriesなので、それぞれ6万件と1万件あります。想定通りです。
ただ、メモリ使用量が意外と多いですね。360MBも訓練データで使っています。データ量が数GBある場合はラベルだけ読み込むなどやり方を考えておいた方がいいかもですね。
"""
特定のカラムの分布を確認する
引数: pandas.core.series.Series
"""
def get_distribution(dataframe1d):
record_num = dataframe1d.value_counts().sum()
distribution = dataframe1d.value_counts().sort_index()
distribution_pct = distribution / record_num
distribution_tbl = pd.concat([distribution, distribution_pct], axis=1)
distribution_tbl.columns = ["ラベル数","ラベル割合"]
return distribution_tbl
# 訓練データの分布を確認
print(get_distribution(df_train[0]))
# テストデータの分布を確認
print(get_distribution(df_test[0]))ラベル数 ラベル割合 0 5923 0.098717 1 6742 0.112367 2 5958 0.099300 3 6131 0.102183 4 5842 0.097367 5 5421 0.090350 6 5918 0.098633 7 6265 0.104417 8 5851 0.097517 9 5949 0.099150 ラベル数 ラベル割合 0 980 0.0980 1 1135 0.1135 2 1032 0.1032 3 1010 0.1010 4 982 0.0982 5 892 0.0892 6 958 0.0958 7 1028 0.1028 8 974 0.0974 9 1009 0.1009
概ね二つデータセットの分布は同じくらいの構成比を持っているようです。
多層パーセプトロンでMNISTデータの手書き数字の認識に挑戦する
MNISTデータセットについての理解と中身の確認でかなりの文量になってしまいましたが、「ニューラルネットワーク自作入門」のコードを利用し、MNISTのデータを多層パーセプトロンに投入して数字の予測をしてみようと思います。
過去記事「(その2) Pythonでニューラルネットワークを構築しながらディープラーニングを勉強してみる」に多層パーセプトロンの説明もありますのでご参考になればと思います。
下記githubにアップされているコードを参考にしています。
データやクラスの定義
import pandas as pd
df_train = pd.read_csv("https://pjreddie.com/media/files/mnist_train.csv",header=None)
df_test = pd.read_csv("https://pjreddie.com/media/files/mnist_test.csv",header=None)import numpy as np
import scipy.special # シグモイド関数を呼び出すのに利用
import matplotlib.pyplot
"""
ニューラルネットワーククラス
__init__
train: 正解データとの誤差を縮小しながら重みを更新していく
query: 現在の重みから各アウトプットの予測確率を出力する
"""
class neuralNetwork:
# ニューラルネットワークの初期化
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# それぞれのノードの数を設定
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# 重みの初期化
self.wih = np.random.normal(0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes))
# 学習率の設定
self.lr = learningrate
# 活性化関数の設定。今回はシグモイド回数
self.activation_function = lambda x: scipy.special.expit(x)
pass
# 学習するためのファンクション
def train(self, inputs_list, targets_list):
# インデータ、正解データ
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
# 順方向伝搬
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
# 誤差逆伝播
output_errors = targets - final_outputs
hidden_errors = np.dot(self.who.T, output_errors)
self.who += self.lr * np.dot((output_errors * final_outputs * (1.0 - final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), np.transpose(inputs))
pass
# 現在の重みでアウトプットを出す
def query(self, inputs_list):
inputs = np.array(inputs_list, ndmin=2).T
# 順方向伝搬
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs学習してみる
input_nodes = 784 # 28ピクセル x 28ピクセルのデータ
hidden_nodes = 200 # 隠れ層のノードは任意の値
output_nodes = 10 # 0 ~ 9のうちどの数字である確率が高いかをアウトプットとしている
# 学習率
learning_rate = 0.1
# ニューラルネットワークのインスタンスを作成
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)# 何回訓練を繰り返すか
epochs = 5
# インプットデータ
train_records = df_train.to_numpy()
for e in range(epochs):
for record in train_records:
# 画像のピクセル値を正規化
inputs = record[1:] / 255.0 * 0.99 + 0.01
# 正解データの作成 (0 ~ 9までそれぞれを0.01の値で初期化)
targets = np.zeros(output_nodes) + 0.01
# 画像が表す数字の箇所を0.99に変更 (画像が5だったら、5番目を0.99の確率にする)
targets[int(record[0])] = 0.99
# 学習開始
n.train(inputs, targets)
pass
pass私の環境だと大体5分くらいかかりました。
精度確認
# 予測した数字情報を格納する
predicts = []
# インプットデータ
test_records = df_test.to_numpy()
# ラベル予測値をpredictsに格納する
for record in test_records:
# 最初の列が画像が表している数字情報
correct_label = int(record[0])
# ピクセル値の正規化
inputs = record[1:] / 255.0 * 0.99 + 0.01
# ニューラルネットワークモデルを適用
outputs = n.query(inputs)
# 一番確率が高いインデックス(今回だと数字)を格納
predicts.append(np.argmax(outputs))
# 正誤表の作成
actual_predicts_table = pd.concat([df_test[0],pd.DataFrame(predicts)], axis=1)
actual_predicts_table.columns = ["actual","predicts"]
actual_predicts_table["iscorrect"] = np.where(actual_predicts_table["actual"] == actual_predicts_table["predicts"], 1, 0)
# 正解率の算出
print ("performance = ", actual_predicts_table.iscorrect.sum() / len(actual_predicts_table))performance = 0.972
正解率は97.2%のようです。かなり高いですね。画像データをインプットデータとして利用出来たことに感動しました。
不正解データの確認
どんな数字を当てることが出来なかったのが気になりますね?確認してみましょう
actual_predicts_table[actual_predicts_table["iscorrect"] == 0]
actual predicts iscorrect
115 4 9 0
217 6 5 0
233 8 7 0
247 4 6 0
259 6 0 0
... ... ... ...
9922 4 9 0
9941 5 6 0
9944 3 8 0
9970 5 3 0
9982 5 6 0
import matplotlib.pyplot
to_plot = df_test.iloc[115,1:].to_numpy().reshape(28,28)
matplotlib.pyplot.imshow(to_plot, cmap='Greys')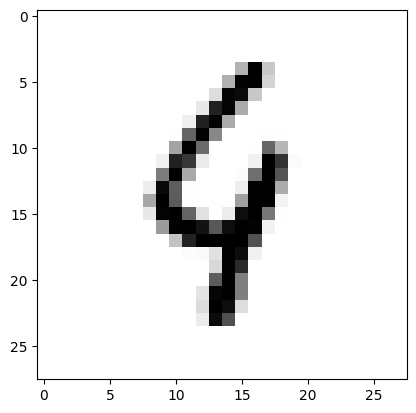
確かに人によっては9に見えなくもないですね。
もう一つくらい見てみましょう。
import matplotlib.pyplot
to_plot = df_test.iloc[233,1:].to_numpy().reshape(28,28)
matplotlib.pyplot.imshow(to_plot, cmap='Greys')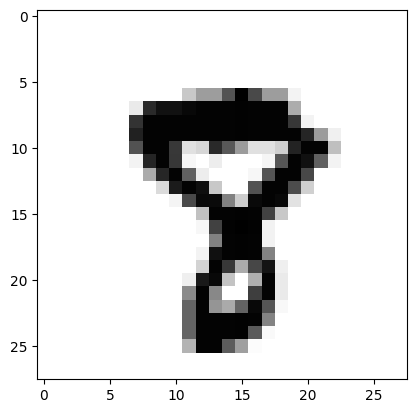
予測は7でしたが、実際は8です。人間の目から見ても8だと思います。モデル改善の余地があるかも知れません。
ラベルごとの不正解率の確認
全体の精度としては97.2%と出ましたが、予測するにあたりラベルごとに得意不得意はあるのでしょうか?
もし特定のラベルだけ精度が低い場合は、そのラベルだけ質のよいデータが足りていない可能性もあります。
label_accuracy = actual_predicts_table[["actual","iscorrect"]].groupby('actual').agg(['sum', 'count'])
label_accuracy["sum/count"] = label_accuracy.iloc[0:,0:1].values / label_accuracy.iloc[0:,1:2].values
label_accuracy
iscorrect sum/count
sum count
actual
0 971 980 0.990816
1 1124 1135 0.990308
2 1001 1032 0.969961
3 990 1010 0.980198
4 953 982 0.970468
5 854 892 0.957399
6 929 958 0.969729
7 982 1028 0.955253
8 938 974 0.963039
9 978 1009 0.969277
0と1は99%の精度ですね。5や7は95%の精度になっているようです。
おそらく、5は6と間違えやすいではないという予測が出来ます。
7は先ほど少し確認した程度だと8と間違えていましたね。
気になるので、7は何と誤認識されやすいのか見てみたいと思います。
# 7なのに他の数字と予測したものを抽出
wrong_seven = actual_predicts_table.loc[(actual_predicts_table.actual == 7) & (actual_predicts_table.iscorrect == 0)]
# 何の数字と間違えたのかカウント
wrong_seven["predicts"].value_counts()9 17 2 12 1 8 3 3 8 3 0 2 4 1
7は9や2と間違えやすいようです。確かにこれなら納得です。
まとめ
多層パーセプトロンで画像データを学習し画像に表示されている数字の予測をすることが出来ました。
一文字だけであれば記号などでも応用可能かも知れないですね。今まで画像だから自動化できないと思っていたタスクには有効だと思われます。
次はCNNを試してみたいですね。