PCA、クラスタリングとやってきて、とうとう潜在クラス分析(Latent Class Analysis、LCA)の順番がやってきました。
私は機械学習やディープラーニングのモデルを作成してシステムやサイトに組み込む業務が多かったので、実業務では試したことがなかったのですが、マーケティング会社さんとかだと使う機会がありそうでしょうか。もっと基礎分析のフェーズなどで試しておけば良かったかも知れません。
潜在クラス分析については私が説明するより、「潜在クラス分析とは」で概要をまとめってくださっているのでそちらを参考にした方が分かりやすいです 笑
潜在クラス分析について引用すると下記になります。引用元では量的データも質的データも使えますよと書いてありますが、色々調べてみると「ユーザー属性情報」や「アンケートの5段階評価の結果」など、質的/カテゴリカルデータへの適用が向いているという情報が多かったように思えます。
潜在クラス分析は、数値データ(量的データ)や数値でないデータ(質的データ)を含む様々な種類が混在するデータを統計的にグループ(クラス)分けをしてくれる手法で、属する一つのグループを決めるのではなく、複数のグループに属するあいまいさを認めている手法です。... 観測された事象の分類(クラス分け)を行うクラスター分析的な側面を持ちます。グループ(クラス)への所属を確率的に分類することができます。統計情報に基づく基準でクラス分けを行うことができます。質的データ(※3)・量的データ(※4)の両方を取り扱うことができ、分析に使える変数の自由度が高い手法と言えます。
引用: https://its.tos.co.jp/products/latentgold/about-latentclass
他にも潜在クラス分析についての文献として分かりやすかったのは、計量社会学の講座として寄稿されている「潜在クラスモデル入門」というジャーナルです。
より詳しく専門的な内容ですが、分析例も載っているので分かりやすかったです。
Pythonで実施する方法があまり載っていなかったのですが、調べてみると「StepMix」というライブラリやgithubで公開している「latent-class-analysis」があるようです。
今回はStepMixを使ってみたいと思います。
StepMixで潜在クラス分析を試してみる
本当はカテゴリカルデータが良いかと思いますが、とりあえず数値データしかないAwA2のデータセットで試してみます。
StepMixがサンプルコードをたくさん用意してくれているので、参考にしようと思います。(ほぼ同じことを実行するだけかも知れませんが 笑)
LCA用のデータセットの作成
# 描画用の設定
import seaborn as sns
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)
BASE_DIR="/Users/hinomaruc/Desktop/blog/dataset/AwA2/Animals_with_Attributes2"
import pandas as pd
import numpy as np
import os
from IPython.display import display, HTML
from sklearn.decomposition import PCA
# 動物クラスの情報 (indexの情報として利用)
classes=pd.read_fwf(os.path.join(BASE_DIR,"classes.txt"), header=None)[1].values
# 属性情報名 (columnの情報として利用)
feature_names=pd.read_fwf(os.path.join(BASE_DIR,"predicates.txt"), header=None)[1].values
# 各動物クラスの属性情報 (データの中身)
features = pd.read_fwf(os.path.join(BASE_DIR,"predicate-matrix-continuous.txt"), header=None)
# データフレームの作成
df_animals_attributes = pd.DataFrame(data=features.values,index=classes,columns=feature_names)
# PCA
X = df_animals_attributes.values
pca = PCA(n_components=2)
X_pca = pca.fit(X).transform(X)85変数全てを使って潜在クラス分析を実施
from stepmix.stepmix import StepMix
# continuous latent class modelの作成
lca = StepMix(n_components=3, measurement="continuous", verbose=1, random_state=1234)
# フィット
lca.fit(df_animals_attributes)
================================================================================
MODEL REPORT
================================================================================
============================================================================
Measurement model parameters
============================================================================
model_name gaussian_diag
class_no 0 1 2
param variable
covariances active 497.3704 742.9407 310.6696
agility 564.1669 715.6576 327.3713
arctic 627.3372 857.1449 34.7398
big 1244.3657 729.0694 993.8376
bipedal 544.3001 4.3443 54.2571
・・・省略・・・
vegetation 515.7967 393.5548 604.6731
walks 1015.8455 497.3140 166.5320
water 1291.9431 774.6674 5.0966
weak 129.4761 16.5056 309.0791
white 859.4793 121.9341 795.1576
yellow 0.6720 150.6697 99.2409
means active 39.3294 37.3318 39.5226
agility 40.6219 41.5245 28.4870
arctic 18.2188 20.1491 2.3370
big 48.0262 56.7800 32.1178
bipedal 22.5631 1.1491 3.2717
・・・省略・・・
vegetation 23.4475 16.8264 46.5661
walks 37.4862 47.3773 59.5678
water 32.9825 19.0318 1.5239
weak 11.3413 2.3245 19.3800
white 23.4575 11.9227 36.3604
yellow 0.3462 9.3382 2.8230
============================================================================
Class weights
============================================================================
Class 1 : 0.32
Class 2 : 0.22
Class 3 : 0.46
============================================================================
Fit for 3 latent classes
============================================================================
Estimation method : 1-step
Number of observations : 50
Number of latent classes : 3
Number of estimated parameters: 512
Log-likelihood (LL) : -16147.1614
-2LL : 32294.3227
Average LL : -322.9432
AIC : 33318.32
BIC : 34297.28
CAIC : 34809.28
Sample-Size Adjusted BIC : 34693.15
Entropy : 0.0000
Scaled Relative Entropy : 1.0000
Class weightsが所属割合、meansが各クラスの属性平均値でしょうか。
よくよく見てみるとcontinuousの場合、実際は混合ガウスモデルで動いているようです。
More formally, continuous is an alias for a Gaussian mixture model with diagonal covariance. We in fact estimate one mean and one variance parameter per feature.
引用: https://stepmix.readthedocs.io/en/latest/api.html#stepmix.stepmix.StepMix
一応描画してみます。
LCAの結果を描画
import matplotlib.pyplot as plt
from adjustText import adjust_text
# 描画用に作成クラスタ情報を変数に格納
cluster_assignments = lca.predict(df_animals_attributes)
uniq_cluster_assignments = np.unique(cluster_assignments)
n_clusters=np.size(uniq_cluster_assignments)
# 散布図の作成
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=cluster_assignments, cmap='viridis',s=50)
# クラスタに割り当てた色の情報を格納
colormap = plt.get_cmap('viridis', n_clusters)
cluster_colors = [colormap(i) for i in range(n_clusters)]
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Latent Class Analysis')
# 凡例を追加
legend_labels = [f'Cluster {i}' for i in range(n_clusters)]
legend_handles = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor=cluster_colors[i], markersize=10, label=legend_labels[i]) for i in range(n_clusters)]
plt.legend(handles=legend_handles, title='Cluster Numbers', loc='lower right')
texts = []
# 各プロットにクラス名を追加。ラベル配置調整用にリストにも追加。
for idx,aclass in enumerate(classes):
texts.append(plt.text(X_pca[idx, 0], X_pca[idx, 1], aclass, fontsize=9, ha='center', va='bottom'))
# ラベル位置の調整 (pip install adjustText 必要)
adjust_text(texts)
# グリッド追加
plt.grid(True)
# 描画
plt.show()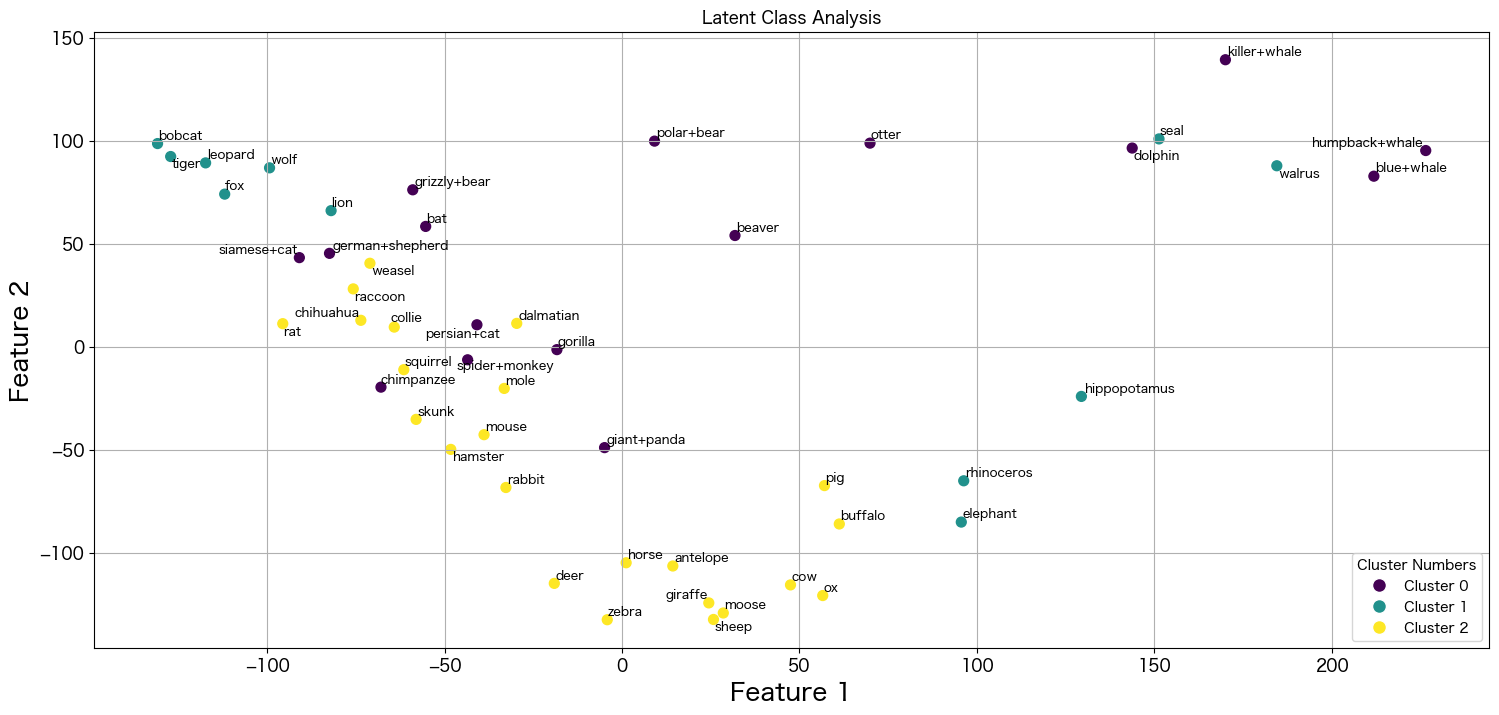
うーん、あんまりきれいに分かれていると言い難いですね。
batとpolar+bearが同じグループに所属しているのは違和感があります。
PCAで2次元に圧縮したデータを使って潜在クラス分析を実施
結果だけ載せておきます。
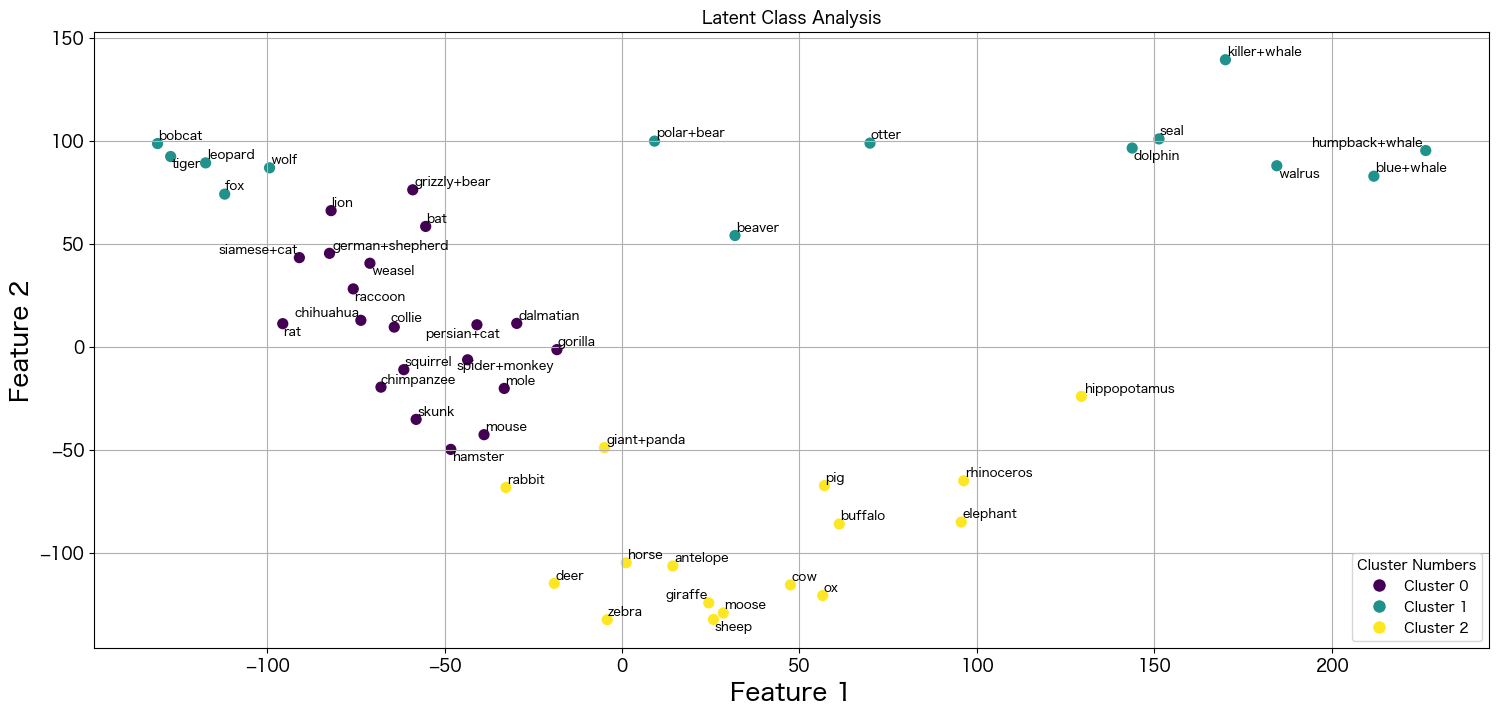
なんとなく海の生物と陸の生物は上手く分かれているようですが、それでもクジラとキツネが同じグループに所属しているのは謎ですね 笑
カテゴリカルデータでStepMixを使い潜在クラス分析を試してみる
AwA2は数値データなのでStepMixでは潜在モデルではなく、混合ガウスモデルが使われてしまいました。
そのためカテゴリのみのデータでも試してみたいと思います。
AwA2の数値の属性情報をすべてカテゴリー化 (例えば0-10は1などに置き換える)しても良かったのですが、せっかくなので潜在モデル分析に向いているアンケートデータを使いたいと思います。
検索していたらKaggleに「Big Five Personality Test」1M Answers to 50 personality items, and technical information というデータセットがありました。
五大性格診断(Big Five Personality Test)はFFMモデルやOCEANモデルとも言われている性格分類を目的としたモデルのようです。本データセットには50個の設問に対する100万件の回答がデータ化され提供されています。設問に使われている言葉がそのまま回答者の性格を説明するものになっているようです。例えば、真面目な人は「計画性がある」と言われることが多く、「だらしない」とは言われにくいという性質を持っているようです。この理論は言葉の関連に基づき、神経心理学的な実験ではなく、一般的な言語記述を使用して人間の性格を5つの広い次元で説明することを提唱しています。
The Big Five personality traits, also known as the five-factor model (FFM) and the OCEAN model, is a taxonomy, or grouping, for personality traits. When factor analysis (a statistical technique) is applied to personality survey data, some words used to describe aspects of personality are often applied to the same person. For example, someone described as conscientious is more likely to be described as "always prepared" rather than "messy". This theory is based therefore on the association between words but not on neuropsychological experiments. This theory uses descriptors of common language and therefore suggests five broad dimensions commonly used to describe the human personality and psyche.
引用: https://www.kaggle.com/datasets/tunguz/big-five-personality-test/data
潜在クラス分析で複数の似た集団がでてくるのではないかと予想しています。五大性格診断だから5つのクラスを作成しようかと思っています。
それではさくっと進めていきます。
五大性格診断のデータセットの中身を確認
データセットの理解から始めます。性格診断の設問は全部50個あるということなので、まとめました。他にも回答者の情報なども含まれていましたが、今回は割愛します。
国や地域別の性格分類などしても面白いかも知れません。
| カラム名 | 設問(英語) | 設問(日本語) |
|---|---|---|
| EXT1 | I am the life of the party. | 私はパーティーの中心人物です。 |
| EXT2 | I don't talk a lot. | 私はあまり話しません。 |
| EXT3 | I feel comfortable around people. | 他の人々と一緒にいると落ち着きます。 |
| EXT4 | I keep in the background. | 私は控えめな性格です。 |
| EXT5 | I start conversations. | 私から会話を始めます。 |
| EXT6 | I have little to say. | 私は静かな性格です。 |
| EXT7 | I talk to a lot of different people at parties. | 私はパーティーでたくさんの異なる人々と話します。 |
| EXT8 | I don't like to draw attention to myself. | 私は自分に注目されるのが好きではありません。 |
| EXT9 | I don't mind being the center of attention. | 私は注目の的であることを気にしません。 |
| EXT10 | I am quiet around strangers. | 私は見知らぬ人の前では静かです。 |
| EST1 | I get stressed out easily. | 私は簡単にストレスを感じます。 |
| EST2 | I am relaxed most of the time. | 私はほとんどいつもリラックスしています。 |
| EST3 | I worry about things. | 私は物事を心配します。 |
| EST4 | I seldom feel blue. | 私はあまり気が滅入ることはありません。 |
| EST5 | I am easily disturbed. | 私は簡単に気が散ります。 |
| EST6 | I get upset easily. | 私は簡単に怒ります。 |
| EST7 | I change my mood a lot. | 私は気分が変わりやすいです。 |
| EST8 | I have frequent mood swings. | 私はよく気分が変わります。 |
| EST9 | I get irritated easily. | 私は簡単にイライラします。 |
| EST10 | I often feel blue. | 私はよく気が滅入ります。 |
| AGR1 | I feel little concern for others. | 他人にあまり関心がありません。 |
| AGR2 | I am interested in people. | 私は人々に関心を持っています。 |
| AGR3 | I insult people. | 私は人をバカにします。 |
| AGR4 | I sympathize with others' feelings. | 私は他人の気持ちに共感します。 |
| AGR5 | I am not interested in other people's problems. | 私は他人の問題に興味がありません。 |
| AGR6 | I have a soft heart. | 私は柔軟な心の持ち主です。 |
| AGR7 | I am not really interested in others. | 私は本当に他人にあまり興味がありません。 |
| AGR8 | I take time out for others. | 私は他人のために時間を割きます。 |
| AGR9 | I feel others' emotions. | 私は他人の感情を感じることができます。 |
| AGR10 | I make people feel at ease. | 私は人々を安心させることができます。 |
| CSN1 | I am always prepared. | 私はいつも準備ができています。 |
| CSN2 | I leave my belongings around. | 私は物を周囲に放置します。 |
| CSN3 | I pay attention to details. | 私は細部に注意を払います。 |
| CSN4 | I make a mess of things. | 私は物事を台無しにします。 |
| CSN5 | I get chores done right away. | 私はすぐに雑用を片付けます。 |
| CSN6 | I often forget to put things back in their proper place. | 私は物を元の場所に戻すのを忘れることがよくあります。 |
| CSN7 | I like order. | 私は秩序が好きです。 |
| CSN8 | I shirk my duties. | 私は職務を怠ります。 |
| CSN9 | I follow a schedule. | 私はスケジュールに従います。 |
| CSN10 | I am exacting in my work. | 私は仕事に厳格です。 |
| OPN1 | I have a rich vocabulary. | 私は豊富な語彙を持っています。 |
| OPN2 | I have difficulty understanding abstract ideas. | 私は抽象的なアイデアを理解するのが難しいです。 |
| OPN3 | I have a vivid imagination. | 私は鮮明な想像力を持っています。 |
| OPN4 | I am not interested in abstract ideas. | 私は抽象的なアイデアに興味がありません。 |
| OPN5 | I have excellent ideas. | 私は優れたアイデアを持っています。 |
| OPN6 | I do not have a good imagination. | 私は想像力が乏しいです。 |
| OPN7 | I am quick to understand things. | 私は物事を理解するのが速いです。 |
| OPN8 | I use difficult words. | 私は難しい言葉を使います。 |
| OPN9 | I spend time reflecting on things. | 私は物事を熟考する時間を過ごします。 |
| OPN10 | I am full of ideas. | 私はアイデアに溢れています。 |
データの読み込み
import pandas as pd
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/IPIP-FFM-data-8Nov2018/data-final.csv",sep="\t",header=0)
df.head()
0 1 2 3 4
EXT1 4.0 3.0 2.0 2.0 3.0
EXT2 1.0 5.0 3.0 2.0 3.0
EXT3 5.0 3.0 4.0 2.0 3.0
EXT4 2.0 4.0 4.0 3.0 3.0
EXT5 5.0 3.0 3.0 4.0 5.0
... ... ... ... ... ...
endelapse 6 11 7 7 17
IPC 1 1 1 1 2
country GB MY GB GB KE
lat_appx_lots_of_err 51.5448 3.1698 54.9119 51.75 1.0
long_appx_lots_of_err 0.1991 101.706 -1.3833 -1.25 38.0
横持ちのデータセットになっているようです。縦持ちだと扱いづらいと思っていたので良かったです。
使用するカラムのみにフィルタリングする
性格診断への回答データのみに限定します。
# 今回利用するカラムに限定
questions_cols=[
'EXT1',
'EXT2',
'EXT3',
'EXT4',
'EXT5',
'EXT6',
'EXT7',
'EXT8',
'EXT9',
'EXT10',
'EST1',
'EST2',
'EST3',
'EST4',
'EST5',
'EST6',
'EST7',
'EST8',
'EST9',
'EST10',
'AGR1',
'AGR2',
'AGR3',
'AGR4',
'AGR5',
'AGR6',
'AGR7',
'AGR8',
'AGR9',
'AGR10',
'CSN1',
'CSN2',
'CSN3',
'CSN4',
'CSN5',
'CSN6',
'CSN7',
'CSN8',
'CSN9',
'CSN10',
'OPN1',
'OPN2',
'OPN3',
'OPN4',
'OPN5',
'OPN6',
'OPN7',
'OPN8',
'OPN9',
'OPN10'
]
df_lca = df[questions_cols]
df_lca.info()RangeIndex: 1015341 entries, 0 to 1015340 Data columns (total 50 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 EXT1 1013558 non-null float64 1 EXT2 1013558 non-null float64 2 EXT3 1013558 non-null float64 3 EXT4 1013558 non-null float64 4 EXT5 1013558 non-null float64 5 EXT6 1013558 non-null float64 6 EXT7 1013558 non-null float64 7 EXT8 1013558 non-null float64 8 EXT9 1013558 non-null float64 9 EXT10 1013558 non-null float64 10 EST1 1013558 non-null float64 11 EST2 1013558 non-null float64 12 EST3 1013558 non-null float64 13 EST4 1013558 non-null float64 14 EST5 1013558 non-null float64 15 EST6 1013558 non-null float64 16 EST7 1013558 non-null float64 17 EST8 1013558 non-null float64 18 EST9 1013558 non-null float64 19 EST10 1013558 non-null float64 20 AGR1 1013558 non-null float64 21 AGR2 1013558 non-null float64 22 AGR3 1013558 non-null float64 23 AGR4 1013558 non-null float64 24 AGR5 1013558 non-null float64 25 AGR6 1013558 non-null float64 26 AGR7 1013558 non-null float64 27 AGR8 1013558 non-null float64 28 AGR9 1013558 non-null float64 29 AGR10 1013558 non-null float64 30 CSN1 1013558 non-null float64 31 CSN2 1013558 non-null float64 32 CSN3 1013558 non-null float64 33 CSN4 1013558 non-null float64 34 CSN5 1013558 non-null float64 35 CSN6 1013558 non-null float64 36 CSN7 1013558 non-null float64 37 CSN8 1013558 non-null float64 38 CSN9 1013558 non-null float64 39 CSN10 1013558 non-null float64 40 OPN1 1013558 non-null float64 41 OPN2 1013558 non-null float64 42 OPN3 1013558 non-null float64 43 OPN4 1013558 non-null float64 44 OPN5 1013558 non-null float64 45 OPN6 1013558 non-null float64 46 OPN7 1013558 non-null float64 47 OPN8 1013558 non-null float64 48 OPN9 1013558 non-null float64 49 OPN10 1013558 non-null float64 dtypes: float64(50) memory usage: 387.3 MB
あれ? 1015341 entriesあるのに1013558ということはnullのデータがありそうです。
df_lca[df_lca.isna().any(axis=1)]EXT1 EXT2 EXT3 EXT4 EXT5 EXT6 EXT7 EXT8 EXT9 EXT10 ... OPN1 OPN2 OPN3 OPN4 OPN5 OPN6 OPN7 OPN8 OPN9 OPN10 78795 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 78854 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 78889 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 153202 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 153204 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 282818 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 282844 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 282847 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 282921 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 283042 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 1783 rows × 50 columns
1783行のnullデータがあるようです。
元データを確認してみます。
df.iloc[78795]
EXT1 NaN
EXT2 NaN
EXT3 NaN
EXT4 NaN
EXT5 NaN
...
endelapse 133
IPC 1
country US
lat_appx_lots_of_err 38.0
long_appx_lots_of_err -97.0
Name: 78795, Length: 110, dtype: object
どうやら設問の回答部分のみnullなようです。未回答者がいたということでしょうか?
いらないデータなので除外しようと思います。
df_lca_nonull = df_lca.dropna()
df_lca_nonull.describe(include='all',percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,0.99]).transpose()
count mean std min 10% 20% 30% 40% 50% 60% 70% 80% 90% 95% 99% max
EXT1 1013558.0 2.648067 1.264407 0.0 1.0 1.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0
EXT2 1013558.0 2.773115 1.323943 0.0 1.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
EXT3 1013558.0 3.288349 1.215006 0.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
EXT4 1013558.0 3.140595 1.237442 0.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
EXT5 1013558.0 3.276960 1.277593 0.0 1.0 2.0 3.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
EXT6 1013558.0 2.401100 1.225721 0.0 1.0 1.0 2.0 2.0 2.0 2.0 3.0 4.0 4.0 5.0 5.0 5.0
EXT7 1013558.0 2.771744 1.400336 0.0 1.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
EXT8 1013558.0 3.414818 1.271915 0.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
EXT9 1013558.0 2.963740 1.346040 0.0 1.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
EXT10 1013558.0 3.556469 1.305232 0.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
EST1 1013558.0 3.285969 1.345600 0.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
EST2 1013558.0 3.165072 1.228272 0.0 2.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
EST3 1013558.0 3.846466 1.163348 0.0 2.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
EST4 1013558.0 2.663756 1.252999 0.0 1.0 2.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0
EST5 1013558.0 2.843086 1.273892 0.0 1.0 2.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
EST6 1013558.0 2.841154 1.326569 0.0 1.0 2.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
EST7 1013558.0 3.050394 1.293009 0.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
EST8 1013558.0 2.683485 1.343042 0.0 1.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
EST9 1013558.0 3.088511 1.297141 0.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
EST10 1013558.0 2.773504 1.323155 0.0 1.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
AGR1 1013558.0 2.255316 1.339971 0.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 4.0 4.0 5.0 5.0 5.0
AGR2 1013558.0 3.831103 1.140587 0.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
AGR3 1013558.0 2.259957 1.277323 0.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 4.0 4.0 5.0 5.0 5.0
AGR4 1013558.0 3.927497 1.127688 0.0 2.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
AGR5 1013558.0 2.270857 1.171207 0.0 1.0 1.0 2.0 2.0 2.0 2.0 3.0 3.0 4.0 5.0 5.0 5.0
AGR6 1013558.0 3.743075 1.222431 0.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
AGR7 1013558.0 2.195806 1.120320 0.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0
AGR8 1013558.0 3.689389 1.095536 0.0 2.0 3.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
AGR9 1013558.0 3.789116 1.166743 0.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
AGR10 1013558.0 3.592351 1.080791 0.0 2.0 3.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
CSN1 1013558.0 3.297999 1.176791 0.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
CSN2 1013558.0 2.930295 1.390062 0.0 1.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
CSN3 1013558.0 3.975280 1.044728 0.0 3.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
CSN4 1013558.0 2.617866 1.251815 0.0 1.0 1.0 2.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0
CSN5 1013558.0 2.625832 1.274595 0.0 1.0 1.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0
CSN6 1013558.0 2.831821 1.416194 0.0 1.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0 5.0 5.0
CSN7 1013558.0 3.698187 1.128066 0.0 2.0 3.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
CSN8 1013558.0 2.465306 1.140957 0.0 1.0 1.0 2.0 2.0 2.0 3.0 3.0 3.0 4.0 4.0 5.0 5.0
CSN9 1013558.0 3.200695 1.276230 0.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
CSN10 1013558.0 3.590596 1.053185 0.0 2.0 3.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
OPN1 1013558.0 3.654636 1.157155 0.0 2.0 3.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
OPN2 1013558.0 2.075933 1.112600 0.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 3.0 4.0 4.0 5.0 5.0
OPN3 1013558.0 4.000068 1.097169 0.0 2.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0 5.0
OPN4 1013558.0 1.999891 1.090239 0.0 1.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 4.0 4.0 5.0 5.0
OPN5 1013558.0 3.792905 0.992386 0.0 3.0 3.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0
OPN6 1013558.0 1.894605 1.104125 0.0 1.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 4.0 4.0 5.0 5.0
OPN7 1013558.0 3.976375 1.008505 0.0 3.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
OPN8 1013558.0 3.182453 1.255374 0.0 1.0 2.0 2.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0
OPN9 1013558.0 4.122993 1.041216 0.0 3.0 3.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0 5.0
OPN10 1013558.0 3.958441 1.034491 0.0 3.0 3.0 4.0 4.0 4.0 4.0 5.0 5.0 5.0 5.0 5.0 5.0
潜在クラス分析を実施
データ量が多いからか20分ほどかかりました 笑
n_componentsは五大性格診断に倣い、「5」にしています。
from stepmix.stepmix import StepMix
# 潜在クラス分析を実施
lca = StepMix(n_components=5, measurement="categorical", verbose=1, random_state=1234)
# フィット
lca.fit(df_lca_nonull)
================================================================================
MODEL REPORT
================================================================================
============================================================================
Measurement model parameters
============================================================================
model_name categorical
class_no 0 1 2 3 4
param variable
pis AGR10_0 0.9644 0.0035 0.0069 0.0038 0.0040
AGR10_1 0.0041 0.0615 0.1058 0.0066 0.0039
AGR10_2 0.0057 0.2045 0.0455 0.0336 0.0738
AGR10_3 0.0116 0.3714 0.2362 0.1510 0.4159
AGR10_4 0.0079 0.2537 0.1131 0.4308 0.4399
AGR10_5 0.0063 0.1055 0.4924 0.3742 0.0626
AGR1_0 0.6104 0.0020 0.0035 0.0018 0.0024
AGR1_1 0.0947 0.3138 0.4467 0.5561 0.2773
AGR1_2 0.0758 0.2639 0.0661 0.2247 0.3590
AGR1_3 0.0808 0.1604 0.1291 0.0678 0.1558
AGR1_4 0.0575 0.1812 0.0750 0.0846 0.1577
AGR1_5 0.0809 0.0786 0.2797 0.0649 0.0479
AGR2_0 0.6992 0.0056 0.0081 0.0058 0.0062
AGR2_1 0.0239 0.0600 0.1227 0.0057 0.0051
AGR2_2 0.0319 0.1909 0.0534 0.0212 0.0683
AGR2_3 0.0796 0.2476 0.1837 0.0648 0.2521
AGR2_4 0.0837 0.3153 0.1058 0.3176 0.5188
AGR2_5 0.0817 0.1807 0.5263 0.5848 0.1496
AGR3_0 0.7715 0.0013 0.0025 0.0014 0.0017
AGR3_1 0.0861 0.3335 0.5159 0.4437 0.3047
AGR3_2 0.0394 0.2131 0.0732 0.2393 0.3238
AGR3_3 0.0535 0.1767 0.1459 0.1446 0.2108
AGR3_4 0.0306 0.2027 0.0854 0.1297 0.1397
AGR3_5 0.0189 0.0727 0.1770 0.0413 0.0193
AGR4_0 0.8283 0.0034 0.0060 0.0036 0.0040
AGR4_1 0.0135 0.0503 0.1282 0.0153 0.0058
AGR4_2 0.0131 0.1390 0.0482 0.0496 0.0686
AGR4_3 0.0409 0.1664 0.1268 0.0825 0.1937
AGR4_4 0.0522 0.3292 0.0824 0.3326 0.5444
AGR4_5 0.0520 0.3117 0.6084 0.5164 0.1834
AGR5_0 0.8799 0.0021 0.0038 0.0026 0.0026
AGR5_1 0.0302 0.1983 0.4990 0.4556 0.1240
AGR5_2 0.0306 0.3313 0.0856 0.3530 0.5009
AGR5_3 0.0333 0.1951 0.1663 0.1035 0.2463
AGR5_4 0.0138 0.1932 0.0571 0.0639 0.1132
AGR5_5 0.0122 0.0799 0.1882 0.0214 0.0130
AGR6_0 0.9244 0.0055 0.0088 0.0060 0.0062
AGR6_1 0.0056 0.0666 0.1509 0.0410 0.0153
AGR6_2 0.0062 0.1348 0.0401 0.0889 0.1069
AGR6_3 0.0202 0.1761 0.1314 0.1462 0.2456
AGR6_4 0.0166 0.3096 0.0707 0.3177 0.4529
AGR6_5 0.0269 0.3074 0.5981 0.4001 0.1731
AGR7_0 0.9614 0.0015 0.0032 0.0021 0.0019
AGR7_1 0.0085 0.1622 0.5170 0.5466 0.1110
AGR7_2 0.0086 0.3182 0.0839 0.3456 0.5474
AGR7_3 0.0098 0.2271 0.1780 0.0651 0.2551
AGR7_4 0.0073 0.2260 0.0582 0.0337 0.0813
AGR7_5 0.0045 0.0649 0.1597 0.0068 0.0034
AGR8_0 0.9755 0.0039 0.0071 0.0037 0.0037
AGR8_1 0.0027 0.0470 0.1273 0.0109 0.0042
AGR8_2 0.0041 0.1872 0.0570 0.0580 0.0865
AGR8_3 0.0076 0.2405 0.1812 0.1236 0.2955
AGR8_4 0.0050 0.3510 0.1084 0.4441 0.5280
AGR8_5 0.0052 0.1705 0.5190 0.3596 0.0821
AGR9_0 0.9646 0.0013 0.0029 0.0018 0.0018
AGR9_1 0.0032 0.0799 0.1375 0.0219 0.0099
AGR9_2 0.0052 0.1616 0.0428 0.0641 0.0995
AGR9_3 0.0099 0.1624 0.1220 0.0963 0.2343
AGR9_4 0.0065 0.3351 0.0885 0.3657 0.5324
AGR9_5 0.0105 0.2595 0.6063 0.4502 0.1222
CSN10_0 0.9584 0.0035 0.0073 0.0041 0.0045
CSN10_1 0.0044 0.0326 0.0963 0.0157 0.0052
CSN10_2 0.0052 0.1304 0.0436 0.0852 0.0896
CSN10_3 0.0111 0.3104 0.2537 0.2363 0.4266
CSN10_4 0.0102 0.3319 0.1095 0.3995 0.4122
CSN10_5 0.0108 0.1912 0.4896 0.2591 0.0618
CSN1_0 0.6382 0.0080 0.0127 0.0092 0.0094
CSN1_1 0.0404 0.0970 0.1677 0.0427 0.0198
CSN1_2 0.0540 0.2251 0.0767 0.1505 0.1702
CSN1_3 0.1115 0.2441 0.2478 0.2273 0.3341
CSN1_4 0.0843 0.3086 0.1520 0.3957 0.3909
CSN1_5 0.0715 0.1173 0.3431 0.1747 0.0754
CSN2_0 0.7197 0.0032 0.0051 0.0028 0.0030
CSN2_1 0.0597 0.1808 0.4102 0.2075 0.1340
CSN2_2 0.0542 0.1936 0.0652 0.2032 0.2791
CSN2_3 0.0768 0.1620 0.1557 0.1750 0.2441
CSN2_4 0.0482 0.2673 0.0744 0.2475 0.2759
CSN2_5 0.0413 0.1932 0.2893 0.1640 0.0640
CSN3_0 0.7845 0.0021 0.0038 0.0025 0.0026
CSN3_1 0.0169 0.0217 0.0666 0.0141 0.0056
CSN3_2 0.0187 0.0900 0.0391 0.0716 0.0715
CSN3_3 0.0495 0.1495 0.1374 0.1237 0.2228
CSN3_4 0.0620 0.3753 0.1013 0.3567 0.5062
CSN3_5 0.0683 0.3613 0.6517 0.4314 0.1913
CSN4_0 0.8393 0.0030 0.0046 0.0028 0.0029
CSN4_1 0.0389 0.1384 0.4167 0.3020 0.1129
CSN4_2 0.0277 0.2373 0.0789 0.3102 0.4039
CSN4_3 0.0537 0.2229 0.1821 0.1857 0.2979
CSN4_4 0.0241 0.2684 0.0791 0.1513 0.1668
CSN4_5 0.0162 0.1301 0.2386 0.0478 0.0156
CSN5_0 0.9023 0.0030 0.0074 0.0033 0.0037
CSN5_1 0.0158 0.3235 0.3091 0.1867 0.1124
CSN5_2 0.0209 0.2997 0.0803 0.2610 0.3368
CSN5_3 0.0305 0.1775 0.2194 0.2258 0.3134
CSN5_4 0.0189 0.1388 0.0879 0.2147 0.1957
CSN5_5 0.0116 0.0574 0.2958 0.1085 0.0379
CSN6_0 0.9412 0.0019 0.0042 0.0024 0.0023
CSN6_1 0.0112 0.1848 0.4130 0.2724 0.1291
CSN6_2 0.0109 0.2141 0.0603 0.2428 0.3381
CSN6_3 0.0169 0.1366 0.1338 0.1397 0.2232
CSN6_4 0.0110 0.2438 0.0629 0.2023 0.2477
CSN6_5 0.0088 0.2187 0.3258 0.1404 0.0596
CSN7_0 0.9638 0.0026 0.0050 0.0029 0.0028
CSN7_1 0.0055 0.0436 0.1384 0.0345 0.0133
CSN7_2 0.0047 0.1090 0.0433 0.1008 0.0907
CSN7_3 0.0083 0.2050 0.1840 0.2044 0.2861
CSN7_4 0.0089 0.3663 0.0919 0.3757 0.4664
CSN7_5 0.0087 0.2735 0.5374 0.2817 0.1407
CSN8_0 0.9805 0.0030 0.0072 0.0034 0.0036
CSN8_1 0.0036 0.1699 0.4140 0.3349 0.1181
CSN8_2 0.0035 0.2459 0.0722 0.2887 0.3581
CSN8_3 0.0070 0.3077 0.2924 0.2447 0.4014
CSN8_4 0.0036 0.2043 0.0636 0.1049 0.1110
CSN8_5 0.0019 0.0691 0.1505 0.0234 0.0078
CSN9_0 0.9694 0.0025 0.0055 0.0033 0.0029
CSN9_1 0.0043 0.1642 0.2264 0.0839 0.0378
CSN9_2 0.0059 0.2373 0.0657 0.1822 0.2033
CSN9_3 0.0082 0.1969 0.1790 0.2076 0.3023
CSN9_4 0.0052 0.2636 0.0958 0.3288 0.3753
CSN9_5 0.0070 0.1355 0.4275 0.1942 0.0784
EST10_0 0.9545 0.0023 0.0061 0.0024 0.0027
EST10_1 0.0101 0.0891 0.3564 0.3430 0.1037
EST10_2 0.0086 0.1529 0.0703 0.3025 0.3719
EST10_3 0.0118 0.1841 0.2106 0.1679 0.3073
EST10_4 0.0059 0.3307 0.0809 0.1390 0.1969
EST10_5 0.0091 0.2409 0.2757 0.0451 0.0175
EST1_0 0.6521 0.0045 0.0074 0.0043 0.0048
EST1_1 0.0554 0.0664 0.2485 0.1759 0.0531
EST1_2 0.0563 0.1262 0.0681 0.2407 0.2188
EST1_3 0.0961 0.1351 0.1592 0.2075 0.2800
EST1_4 0.0647 0.2977 0.0919 0.2417 0.3331
EST1_5 0.0753 0.3702 0.4248 0.1298 0.1102
EST2_0 0.7362 0.0058 0.0083 0.0064 0.0059
EST2_1 0.0317 0.1479 0.2377 0.0368 0.0183
EST2_2 0.0462 0.3119 0.1054 0.1774 0.2028
EST2_3 0.0806 0.2157 0.2202 0.2404 0.3421
EST2_4 0.0539 0.2142 0.0893 0.3331 0.3552
EST2_5 0.0514 0.1046 0.3391 0.2059 0.0758
EST3_0 0.7929 0.0019 0.0030 0.0016 0.0021
EST3_1 0.0165 0.0234 0.1276 0.0624 0.0110
EST3_2 0.0207 0.0670 0.0488 0.1538 0.1031
EST3_3 0.0547 0.0793 0.1330 0.1642 0.2035
EST3_4 0.0537 0.3151 0.0871 0.3557 0.5076
EST3_5 0.0615 0.5133 0.6005 0.2623 0.1727
EST4_0 0.8565 0.0059 0.0119 0.0062 0.0064
EST4_1 0.0251 0.3083 0.3462 0.1351 0.0639
EST4_2 0.0278 0.3186 0.0920 0.2698 0.3487
EST4_3 0.0469 0.1758 0.2460 0.2300 0.3517
EST4_4 0.0218 0.1294 0.0691 0.2235 0.2010
EST4_5 0.0219 0.0621 0.2349 0.1353 0.0283
EST5_0 0.9025 0.0018 0.0035 0.0019 0.0020
EST5_1 0.0166 0.1334 0.3251 0.2315 0.0648
EST5_2 0.0203 0.2071 0.0704 0.3222 0.3335
EST5_3 0.0250 0.1861 0.1729 0.1984 0.3155
EST5_4 0.0203 0.3142 0.0923 0.1894 0.2533
EST5_5 0.0153 0.1575 0.3359 0.0567 0.0309
EST6_0 0.9453 0.0062 0.0089 0.0065 0.0062
EST6_1 0.0107 0.1207 0.3242 0.2639 0.0853
EST6_2 0.0123 0.1910 0.0613 0.3020 0.3376
EST6_3 0.0159 0.1690 0.1619 0.1878 0.2999
EST6_4 0.0085 0.3037 0.0873 0.1844 0.2411
EST6_5 0.0073 0.2094 0.3563 0.0554 0.0299
EST7_0 0.9628 0.0018 0.0035 0.0018 0.0019
EST7_1 0.0043 0.0815 0.2771 0.1906 0.0469
EST7_2 0.0060 0.1841 0.0560 0.3005 0.2984
EST7_3 0.0110 0.1818 0.1679 0.2092 0.3299
EST7_4 0.0065 0.3094 0.0736 0.2073 0.2781
EST7_5 0.0094 0.2414 0.4219 0.0906 0.0448
EST8_0 0.9778 0.0024 0.0052 0.0029 0.0030
EST8_1 0.0054 0.1568 0.3571 0.3521 0.1319
EST8_2 0.0037 0.2016 0.0535 0.2797 0.3739
EST8_3 0.0065 0.1762 0.1632 0.1599 0.2737
EST8_4 0.0041 0.2754 0.0760 0.1517 0.1950
EST8_5 0.0025 0.1876 0.3450 0.0538 0.0224
EST9_0 0.9654 0.0016 0.0037 0.0018 0.0022
EST9_1 0.0076 0.0747 0.2670 0.2047 0.0496
EST9_2 0.0063 0.1542 0.0623 0.2965 0.2848
EST9_3 0.0086 0.1543 0.1576 0.1944 0.3004
EST9_4 0.0056 0.3641 0.1016 0.2302 0.3180
EST9_5 0.0064 0.2511 0.4078 0.0724 0.0450
EXT10_0 0.9569 0.0023 0.0033 0.0015 0.0017
EXT10_1 0.0060 0.0100 0.1940 0.1578 0.0097
EXT10_2 0.0059 0.0350 0.0661 0.3267 0.1361
EXT10_3 0.0118 0.0723 0.1682 0.2317 0.2745
EXT10_4 0.0097 0.2568 0.0844 0.2007 0.4160
EXT10_5 0.0097 0.6236 0.4840 0.0816 0.1620
EXT1_0 0.5575 0.0008 0.0026 0.0012 0.0012
EXT1_1 0.1181 0.5028 0.3575 0.0602 0.1388
EXT1_2 0.0606 0.2555 0.0625 0.1237 0.2680
EXT1_3 0.1379 0.1671 0.2679 0.3126 0.3859
EXT1_4 0.0512 0.0617 0.0980 0.3601 0.1751
EXT1_5 0.0746 0.0121 0.2115 0.1422 0.0310
EXT2_0 0.6751 0.0033 0.0045 0.0025 0.0029
EXT2_1 0.0688 0.0487 0.3638 0.4200 0.0842
EXT2_2 0.0605 0.1399 0.0879 0.3225 0.2906
EXT2_3 0.0926 0.2365 0.2144 0.1613 0.3456
EXT2_4 0.0543 0.3014 0.0789 0.0767 0.2336
EXT2_5 0.0487 0.2702 0.2507 0.0171 0.0431
EXT3_0 0.7613 0.0021 0.0045 0.0023 0.0030
EXT3_1 0.0229 0.1760 0.1829 0.0055 0.0059
EXT3_2 0.0314 0.4217 0.0970 0.0389 0.1476
EXT3_3 0.0728 0.2735 0.2461 0.1439 0.3987
EXT3_4 0.0535 0.1093 0.1021 0.4105 0.3911
EXT3_5 0.0581 0.0174 0.3674 0.3988 0.0537
EXT4_0 0.8191 0.0031 0.0056 0.0027 0.0031
EXT4_1 0.0236 0.0101 0.2248 0.2232 0.0156
EXT4_2 0.0295 0.0648 0.0797 0.3848 0.2103
EXT4_3 0.0615 0.1810 0.2618 0.2483 0.4149
EXT4_4 0.0375 0.3903 0.0882 0.1196 0.3240
EXT4_5 0.0288 0.3507 0.3399 0.0214 0.0321
EXT5_0 0.8694 0.0050 0.0089 0.0059 0.0056
EXT5_1 0.0167 0.2349 0.1909 0.0045 0.0182
EXT5_2 0.0188 0.3539 0.0663 0.0375 0.1859
EXT5_3 0.0357 0.2362 0.2100 0.1169 0.3607
EXT5_4 0.0308 0.1458 0.1143 0.4230 0.3877
EXT5_5 0.0286 0.0240 0.4096 0.4122 0.0420
EXT6_0 0.9150 0.0018 0.0039 0.0018 0.0020
EXT6_1 0.0172 0.1311 0.4633 0.5032 0.0671
EXT6_2 0.0197 0.2671 0.0913 0.3802 0.4524
EXT6_3 0.0218 0.1961 0.1834 0.0788 0.3044
EXT6_4 0.0146 0.2580 0.0584 0.0302 0.1612
EXT6_5 0.0117 0.1459 0.1997 0.0059 0.0129
EXT7_0 0.9565 0.0035 0.0059 0.0036 0.0039
EXT7_1 0.0094 0.5223 0.3609 0.0386 0.0971
EXT7_2 0.0071 0.2789 0.0691 0.1299 0.3346
EXT7_3 0.0114 0.1092 0.1787 0.1848 0.2946
EXT7_4 0.0094 0.0660 0.0691 0.3337 0.2309
EXT7_5 0.0063 0.0201 0.3164 0.3093 0.0388
EXT8_0 0.9719 0.0021 0.0040 0.0015 0.0018
EXT8_1 0.0043 0.0355 0.2141 0.1224 0.0191
EXT8_2 0.0035 0.0813 0.0724 0.3112 0.1630
EXT8_3 0.0085 0.1250 0.1935 0.2629 0.3104
EXT8_4 0.0061 0.2960 0.0676 0.2096 0.3956
EXT8_5 0.0057 0.4601 0.4484 0.0923 0.1101
EXT9_0 0.9703 0.0022 0.0049 0.0022 0.0022
EXT9_1 0.0056 0.3484 0.3170 0.0436 0.0694
EXT9_2 0.0045 0.3032 0.0699 0.1235 0.2937
EXT9_3 0.0077 0.1539 0.1826 0.1882 0.3129
EXT9_4 0.0059 0.1367 0.0765 0.3602 0.2821
EXT9_5 0.0059 0.0555 0.3491 0.2823 0.0397
OPN10_0 0.9275 0.0021 0.0029 0.0016 0.0022
OPN10_1 0.0074 0.0248 0.0630 0.0027 0.0042
OPN10_2 0.0068 0.1034 0.0341 0.0234 0.0748
OPN10_3 0.0195 0.2014 0.1832 0.1078 0.3399
OPN10_4 0.0126 0.3162 0.1013 0.3435 0.4549
OPN10_5 0.0262 0.3521 0.6155 0.5210 0.1239
OPN1_0 0.6698 0.0052 0.0094 0.0062 0.0059
OPN1_1 0.0404 0.0448 0.1413 0.0215 0.0270
OPN1_2 0.0514 0.1064 0.0672 0.0693 0.1438
OPN1_3 0.1147 0.2177 0.2667 0.1889 0.3379
OPN1_4 0.0676 0.3396 0.1390 0.3477 0.3710
OPN1_5 0.0562 0.2864 0.3765 0.3665 0.1144
OPN2_0 0.7530 0.0026 0.0043 0.0020 0.0025
OPN2_1 0.0584 0.3859 0.5043 0.5134 0.1689
OPN2_2 0.0531 0.2980 0.0883 0.2964 0.4394
OPN2_3 0.0752 0.1655 0.2098 0.1152 0.2678
OPN2_4 0.0360 0.1099 0.0598 0.0578 0.1081
OPN2_5 0.0244 0.0381 0.1334 0.0152 0.0133
OPN3_0 0.8119 0.0029 0.0059 0.0044 0.0038
OPN3_1 0.0118 0.0266 0.0773 0.0129 0.0102
OPN3_2 0.0181 0.0811 0.0344 0.0543 0.0960
OPN3_3 0.0548 0.1378 0.1619 0.1215 0.2681
OPN3_4 0.0510 0.2867 0.0833 0.2997 0.4377
OPN3_5 0.0524 0.4648 0.6372 0.5072 0.1842
OPN4_0 0.8662 0.0023 0.0052 0.0025 0.0026
OPN4_1 0.0373 0.4415 0.5491 0.5339 0.1887
OPN4_2 0.0299 0.2775 0.0721 0.2726 0.4384
OPN4_3 0.0401 0.1678 0.2099 0.1204 0.2704
OPN4_4 0.0141 0.0782 0.0388 0.0511 0.0882
OPN4_5 0.0124 0.0327 0.1249 0.0195 0.0116
OPN5_0 0.9105 0.0032 0.0055 0.0035 0.0034
OPN5_1 0.0055 0.0260 0.0606 0.0026 0.0031
OPN5_2 0.0061 0.1060 0.0330 0.0194 0.0623
OPN5_3 0.0307 0.2835 0.2360 0.1507 0.3992
OPN5_4 0.0199 0.3629 0.1311 0.4481 0.4637
OPN5_5 0.0273 0.2184 0.5338 0.3757 0.0683
OPN6_0 0.9535 0.0035 0.0059 0.0038 0.0035
OPN6_1 0.0158 0.4569 0.6816 0.6196 0.2168
OPN6_2 0.0100 0.2909 0.0571 0.2434 0.4843
OPN6_3 0.0102 0.1122 0.1145 0.0603 0.1867
OPN6_4 0.0060 0.0930 0.0315 0.0467 0.0962
OPN6_5 0.0046 0.0435 0.1094 0.0262 0.0126
OPN7_0 0.9701 0.0033 0.0068 0.0043 0.0037
OPN7_1 0.0030 0.0179 0.0671 0.0046 0.0038
OPN7_2 0.0031 0.0847 0.0390 0.0309 0.0595
OPN7_3 0.0106 0.1767 0.1850 0.0999 0.2655
OPN7_4 0.0073 0.3844 0.1237 0.3908 0.5281
OPN7_5 0.0059 0.3330 0.5784 0.4694 0.1393
OPN8_0 0.9716 0.0041 0.0057 0.0029 0.0033
OPN8_1 0.0070 0.0917 0.2983 0.0808 0.0625
OPN8_2 0.0046 0.1875 0.0779 0.1646 0.2867
OPN8_3 0.0090 0.2129 0.2147 0.2223 0.3317
OPN8_4 0.0052 0.3182 0.1032 0.3189 0.2811
OPN8_5 0.0026 0.1856 0.3002 0.2105 0.0347
OPN9_0 0.9678 0.0026 0.0061 0.0033 0.0032
OPN9_1 0.0044 0.0163 0.0782 0.0132 0.0075
OPN9_2 0.0032 0.0507 0.0330 0.0532 0.0740
OPN9_3 0.0078 0.0818 0.1433 0.0988 0.1977
OPN9_4 0.0072 0.2856 0.0892 0.3438 0.4949
OPN9_5 0.0096 0.5629 0.6501 0.4877 0.2228
============================================================================
Class weights
============================================================================
Class 1 : 0.00
Class 2 : 0.30
Class 3 : 0.11
Class 4 : 0.31
Class 5 : 0.28
============================================================================
Fit for 5 latent classes
============================================================================
Estimation method : 1-step
Number of observations : 1013558
Number of latent classes : 5
Number of estimated parameters: 1254
Log-likelihood (LL) : -70661699.2234
-2LL : 141323398.4468
Average LL : -69.7165
AIC : 141325906.45
BIC : 141340739.98
CAIC : 141341993.98
Sample-Size Adjusted BIC : 141354096.25
Entropy : 131930.9574
Scaled Relative Entropy : 0.9191
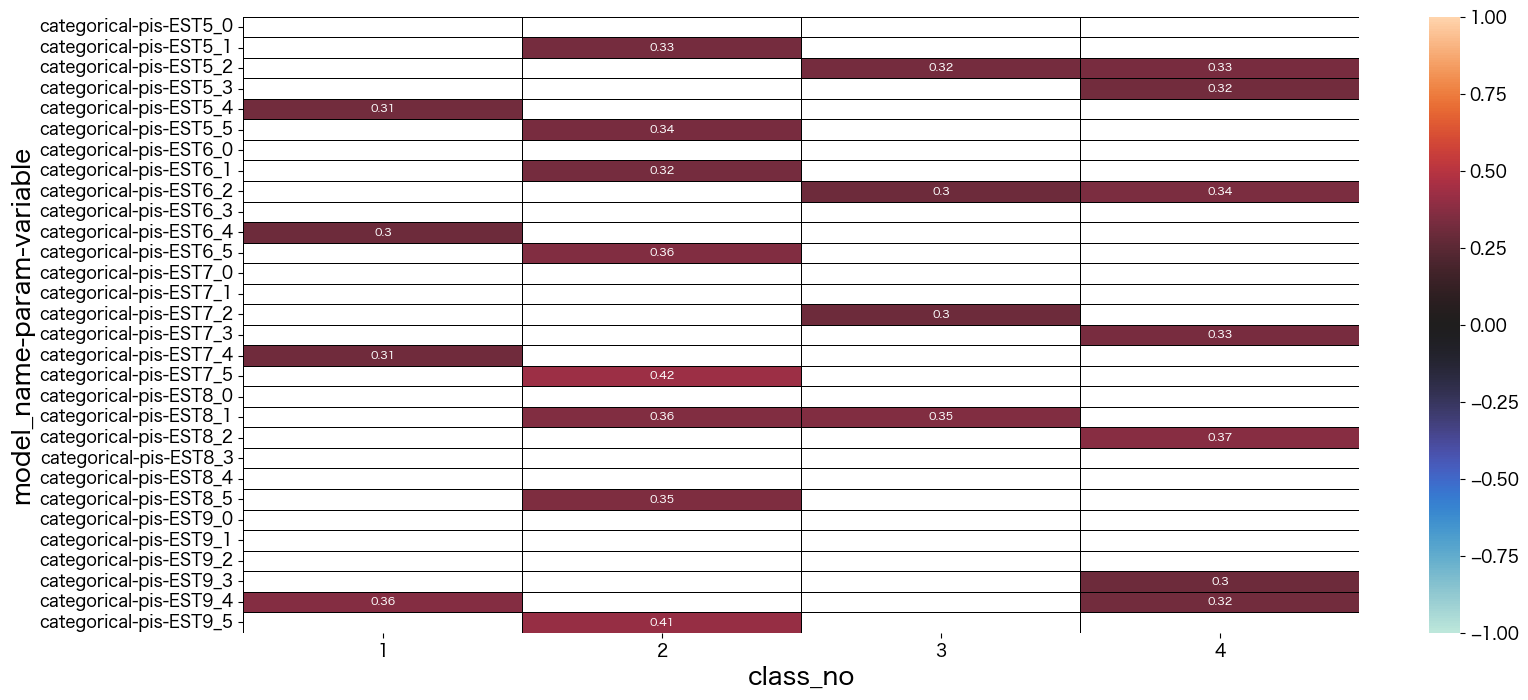
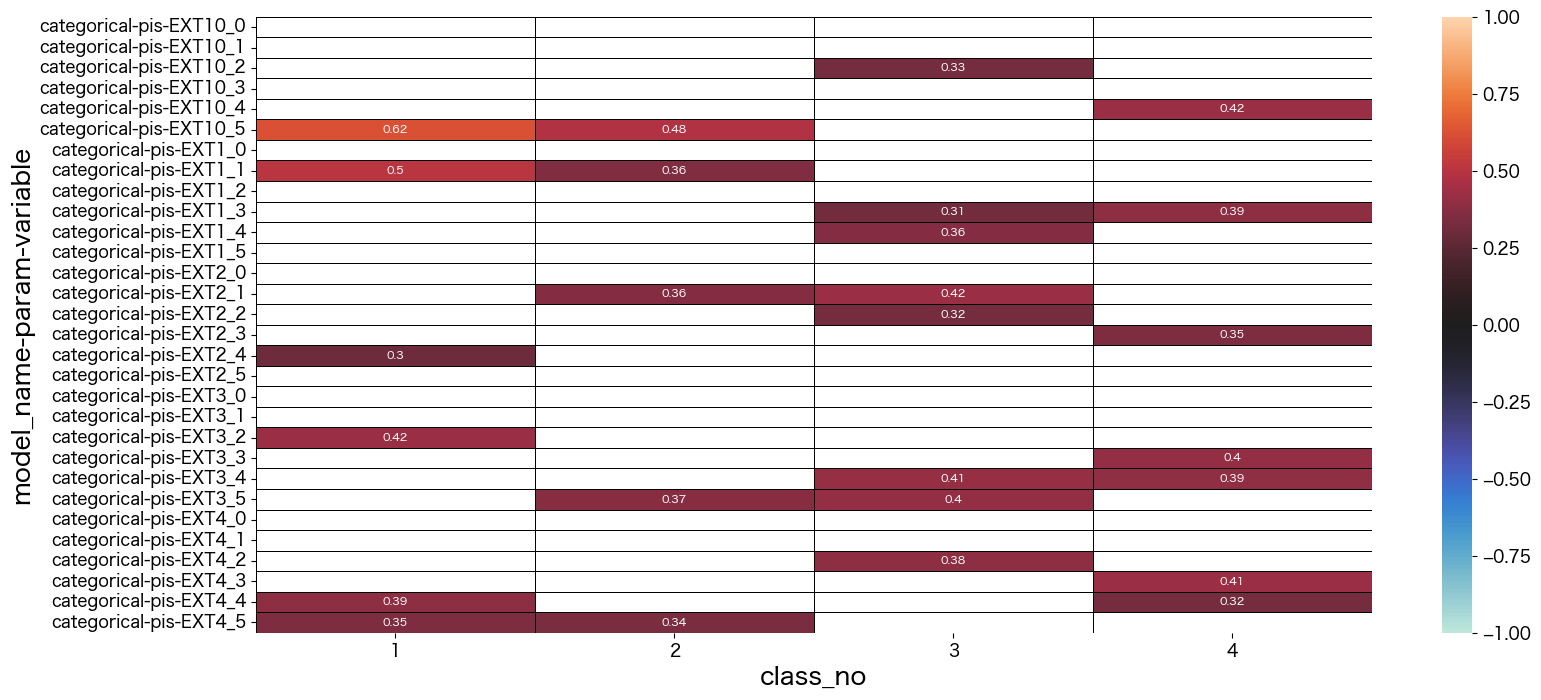
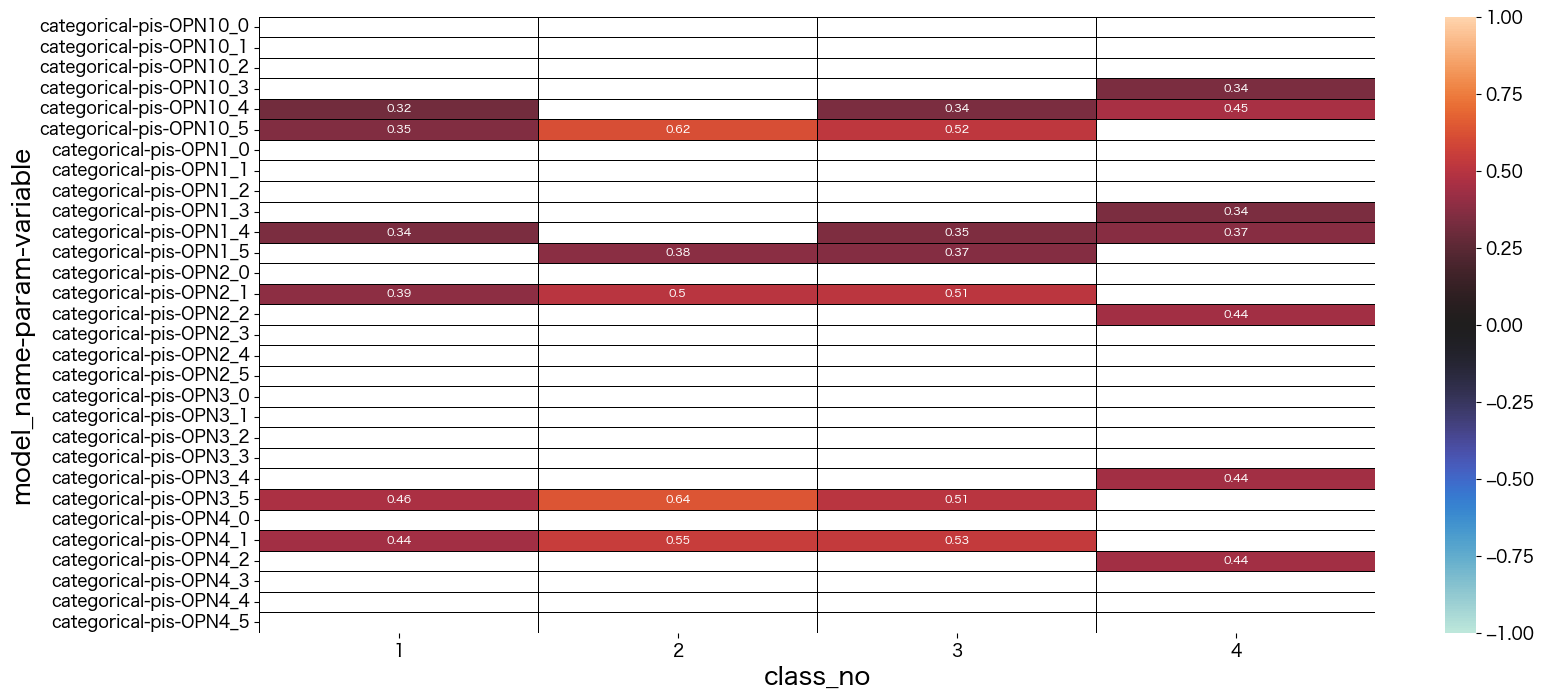
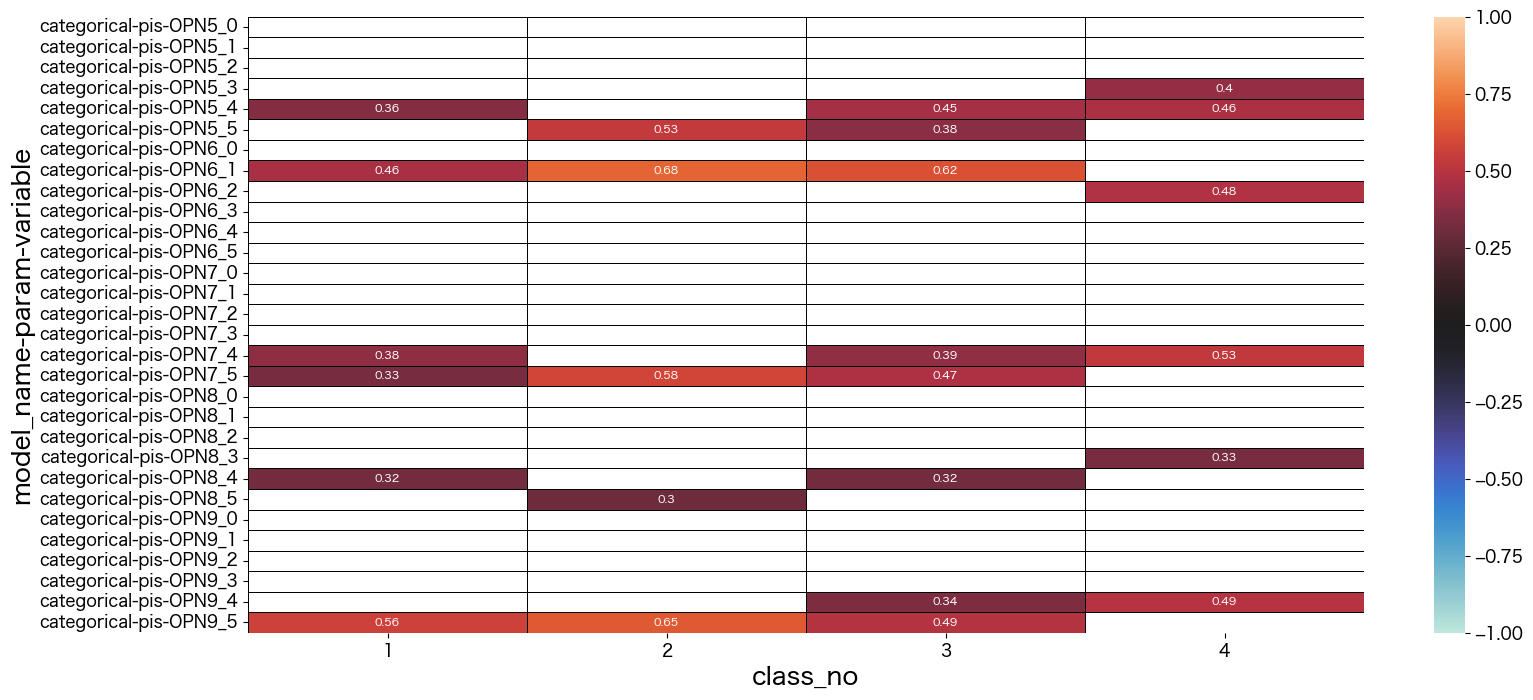
結果は 設問50問 x 5段階評価(1:disagree -> 5:agree) を行、潜在クラス数を列として出力されているようです。
5段階評価なのに0という回答もあるようです。これはnullとはまた違った未回答ということでしょうか、、
データクレンジングのときに除外しても良さそうでしたね。
今回はお試しなので一旦このまま進めます。
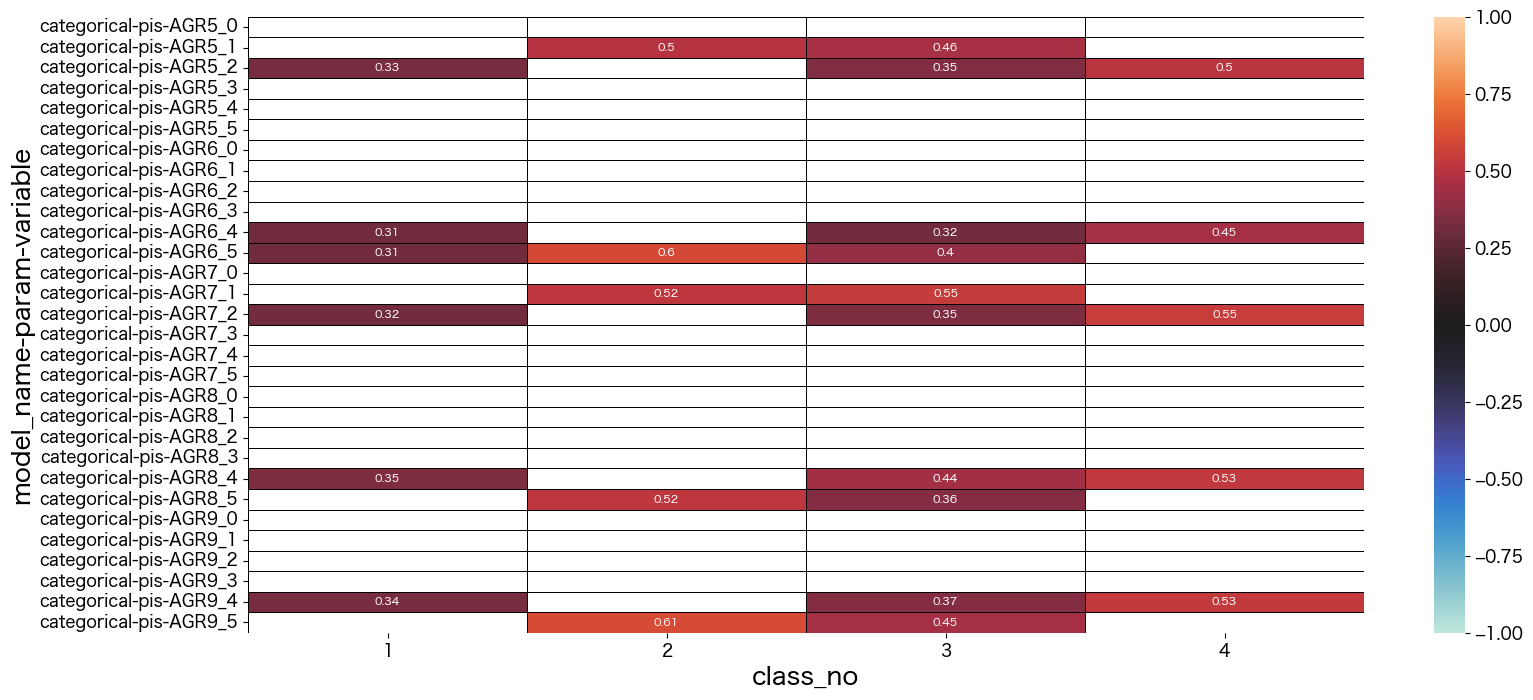
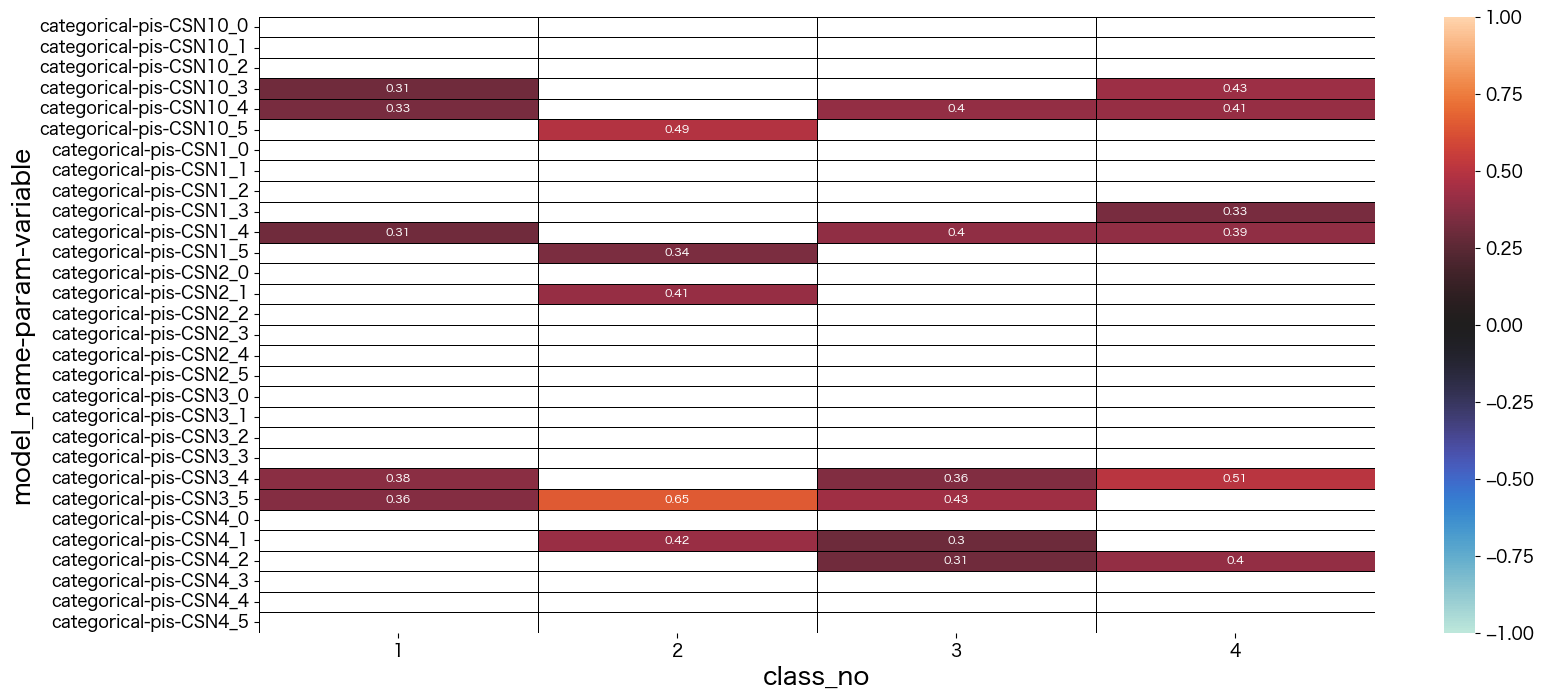
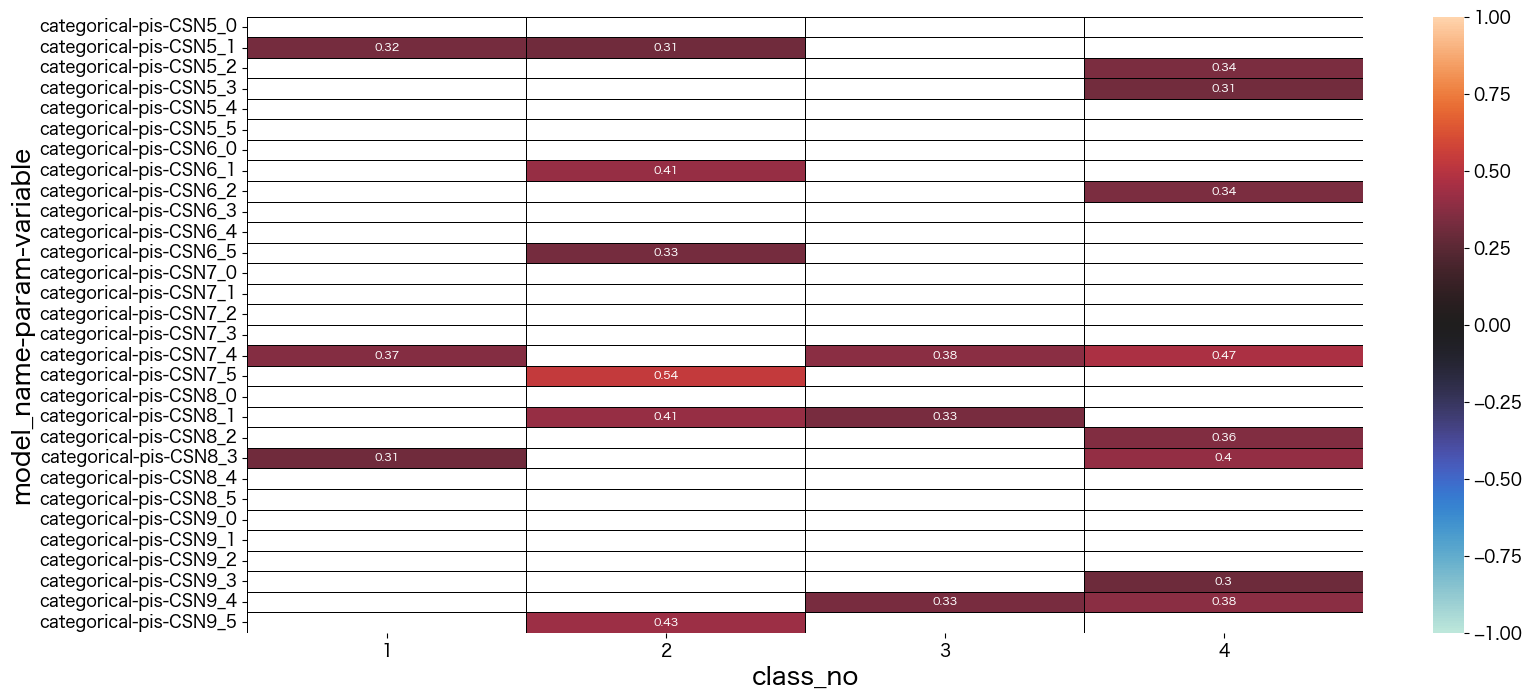
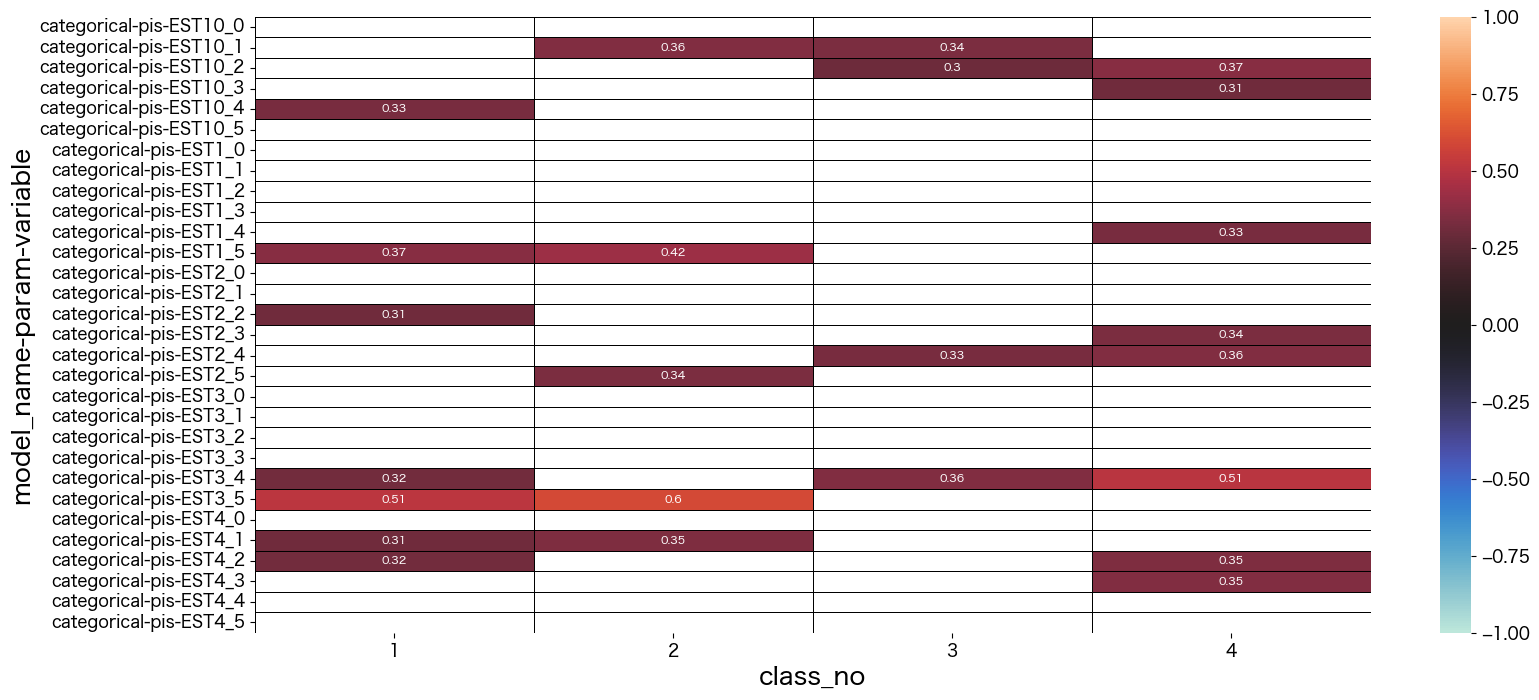
潜在クラス分析した結果の考察
最終的に結果を見て、それぞれのクラスに名前をつけました。
- class_no0 未回答なので不明タイプ (0.004%)
- class_no1 引っ込み思案タイプ (29.5%)
- class_no2 社交的で真面目タイプ (11.1%)
- class_no3 社交的でマイペースタイプ (30.6%)
- class_no4 どちらかと言えば社交的なタイプ (28.3%)
基本的に1や5を選択しているのを特徴と捉えて名前づけしています。
class_no4は極端な付け方をしていない(2~4をつけることが多い)タイプでした。優柔不断な側面があるのかも知れません。
class_no2とclass_no3は社交的な部分は似ていますが、class_no2の方が神経質っぽい印象を持ちました。
class_no1は他のタイプとは真逆っぽい回答をしているようです。
lca.get_cw_df()class_no 0 1 2 3 4 param class_weights 0.004372 0.295141 0.110953 0.305599 0.283936
lca.get_mm_df()
class_no 0 1 2 3 4
model_name param variable
categorical pis AGR10_0 0.96 0.00 0.01 0.00 0.00
AGR10_1 0.00 0.06 0.11 0.01 0.00
AGR10_2 0.01 0.20 0.05 0.03 0.07
AGR10_3 0.01 0.37 0.24 0.15 0.42
AGR10_4 0.01 0.25 0.11 0.43 0.44
... ... ... ... ... ...
OPN9_1 0.00 0.02 0.08 0.01 0.01
OPN9_2 0.00 0.05 0.03 0.05 0.07
OPN9_3 0.01 0.08 0.14 0.10 0.20
OPN9_4 0.01 0.29 0.09 0.34 0.49
OPN9_5 0.01 0.56 0.65 0.49 0.22
mm = lca.get_mm_df()
data = mm.iloc[0:30,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[30:60,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[60:90,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[90:120,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[120:150,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[150:180,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[180:210,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[210:240,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[240:270,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()
data = mm.iloc[270:300,1:]
sns.heatmap(data, vmax=1, vmin=-1, center=0, mask = abs(data) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})
plt.show()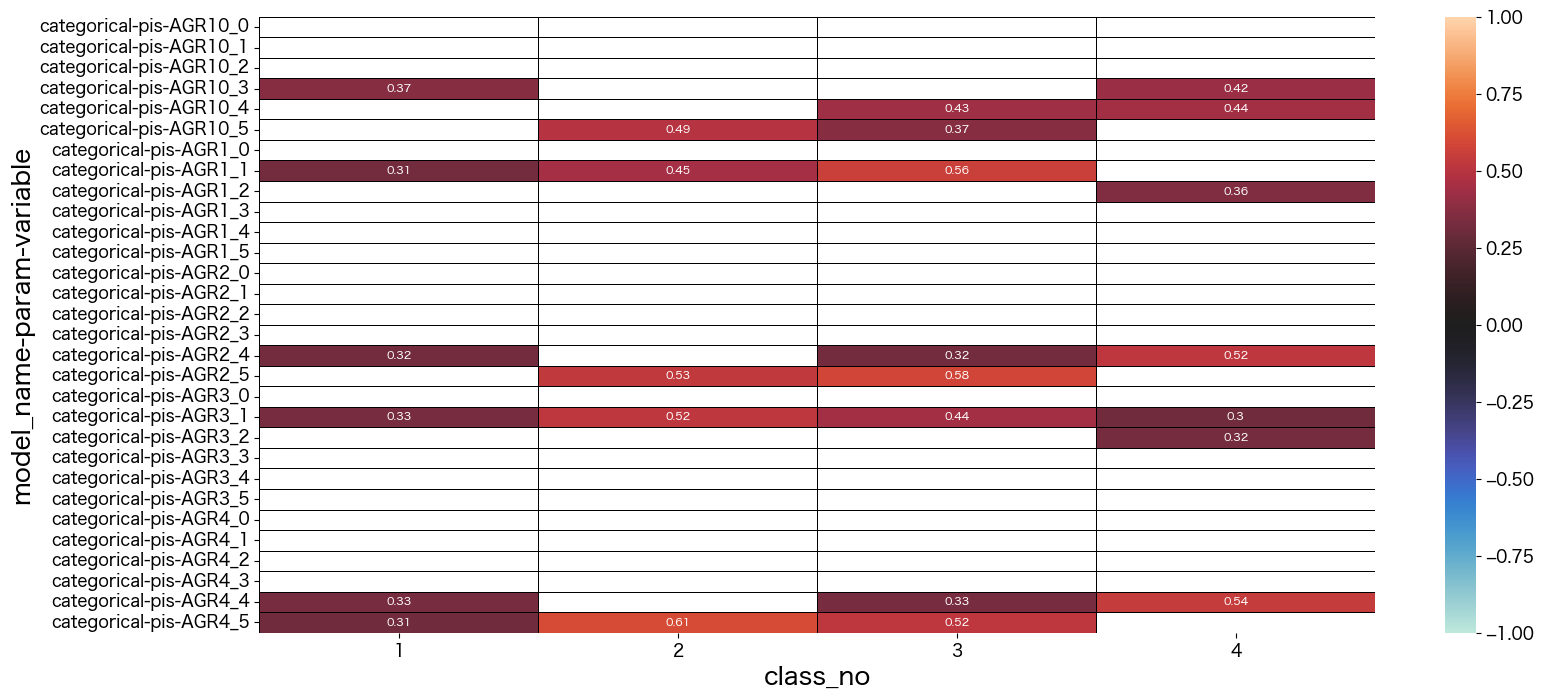

まとめ
ここまでクラスタリング、PCA、潜在クラス分析を実施しました。
どれも使いどころを見極めて実施すると分析の幅も広がりそうですね。