低音質のデータを高音質にディープラーニングで変換できないかなとふと思い、HiFi-GAN+というモデルで信号の帯域幅拡張をすることにより実現できそうということが分かりました。
HiFi-GANはhigh-fidelity generative adversarial networkの略のようです。日本語に訳すと「原音に再現する敵対的生成ネットワーク」という意味になるようです。
HiFi-GAN+モデルが発表されている論文はこちらからダウンロードできました。
論文の内容を実装してくれたのが、下記githubのレポジトリになります。
音声データについて調べてみた
音声データの分析はやったことがないので分析?前にまずは色々用語や常識から調べてみましたが、勉強になることが多かったです。
GANは生成モデルの一種であり、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換できる。引用: https://www.imagazine.co.jp/gan%EF%BC%9A%E6%95%B5%E5%AF%BE%E7%9A%84%E7%94%9F%E6%88%90%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%A8%E3%81%AF%E4%BD%95%E3%81%8B%E3%80%80%EF%BD%9E%E3%80%8C%E6%95%99%E5%B8%AB/
よく明治時代などの写真に着色した画像を見たことがありますが、GANモデルを使って実現しているんでしょうかね。ディープラーニングの記事を書くにあたりいつか試してみたいと思います。
音声データに限れば、HiFi-GAN+モデルは高音質に存在する音域みたいな信号をGANモデルで生成して原音に近しいレベルに再現してくれるのだろうなという予想がつきました。
This paper proposes a new bandwidth extension (BWE) method that expands 8-16kHz speech signals to 48kHz ... An AB test reveals that our 16-to-48kHz BWE is able to achieve fidelity that is typically indistinguishable from real high-fidelity recordings
引用: https://pixl.cs.princeton.edu/pubs/Su_2021_BEI/ICASSP2021_Su_Wang_BWE.pdf
論文によるとサンプリング周波数が8-16kHzの音声を48kHzに広げることが可能になり、ABテストでは実際に収録された音声と聞き分けることができないという結果になったようです。すごいですね。
音声データに関してはreal soundさんやioPLAZAさんの記事がとても参考になりました。
音声の質を決めるのに「3つ」重要なキーワードがありました。サンプリング周波数、ビット深度、ビットレートです。
サンプリング周波数とは
サンプリング周波数も、音の滑らかさ ... にかかわりますが、重要なのは聞こえる周波数の幅が決まるところです。
44100Hzだと半分の22050Hzまでの音が、再現できる限界になります。... サンプリング周波数も、mp3に圧縮するとき変わりませんので、特に気にすることはない
引用: http://uramachblog.sblo.jp/article/47586607.html
22.05kHzまでがCD音源で再現できる周波数(「ナイキスト周波数」と呼ばれるようです)ですが、人間は20kHzくらいまでしか聞こえないようです。ただし、ハイレゾなど44.1kHzより高い周波数だと空気感など音の雰囲気も変わるようです。
ビット深度とは
量子化ビット数は、音の強弱幅や、音の滑らかさに影響します。
8ビットだとザラザラした音になりますし、24ビットだと空気感を感じるくらい滑らかな音になります。
引用: http://uramachblog.sblo.jp/article/47586607.html
CD音源はサンプリング周波数が44.1kHzでビット深度は16ビットのようです。
ビット深度はPCM音声でのみ意味を持つ。 MP3やAACといった非可逆圧縮の非PCM音声ではビット深度の概念はない。
引用: https://ja.wikipedia.org/wiki/ビット深度_(音響機器)
秒あたりビットレートに関して
bpsとは一秒間のビットレートのことです。要は一秒間にどれだけ容量を使ってるか ... 128kbpsだと、一秒でそのまま128kビット使います。
引用: http://uramachblog.sblo.jp/article/47586607.html
MP3だとよく128kbpsとか196kbpsとか320kbpsとか出てきますね。数値が高いほど表現できる容量も多くなるので音質もよくなります。
CD音源は非圧縮で1411kbpsになるようです。MP3形式などは高音域の情報量を削減するなどして320kbpsなどに圧縮しているようです。196kbps以上はあまり違いがわからないようですが気持ち的にはなるべく大きい値がいいですね 笑
音声データをmp3などに圧縮するとどうなるか
音質面では、16ビット44100Hzと見た目は非圧縮時と同じスペックですが、やはり劣化はしてます。
16ビットにしては滑らかさに欠けますし、サンプリングレート44100Hzだけど20000Hzの成分とかほとんどなくなっていたり、ひそかに色んなところで情報量を削ってるわけですね。
引用: http://uramachblog.sblo.jp/article/47586607.html
数値上はCD音源と同じ44.1kHz・16ビットでも情報量は削られているようです。そのためもしかしたらHiFi-GAN+モデルによって欠損部分が補完され音質が改善するかも知れません。こちら今回試してみたいと思います。
音声データの準備
モデルに入力する用のオーディオファイルを準備します。
- wavファイルの入手。非圧縮なのでサイズは大きくなりますがCD音質のものを取得します。
- mp3ファイルの作成。wavファイルから低kbpsのmp3ファイルを作成します。(波形データ確認のみ)
- wavファイルのサンプリング周波数を下げたデータを作成
- 秒あたりビットレートが高いmp3ファイル(320kbps)
1番〜4番のオーディオファイル(2番除く)に対して、HiFi-GAN+モデルを適用し音質がどう変化するか主観的に確認してみようと思います。
また可能であれば音声をスペクトル解析で分析してみようと思います。(波形を調べる程度)
音声ファイル(wavファイル)のダウンロード
wavファイルのサンプリング周波数を44.1kHzから8kHzくらいまで下げたものと、192kbpsのmp3ファイルに変換したものを用意しようと思います。
元データはmusic-noteさんの「アイキャッチ1」と「Home」という音源を利用させていただきました。
短く高音が聴こえる音楽でしたのでチョイスしました。その他にも色々かっこいい音楽を公開してくださっていますのでぜひご自分の好みの音楽を選んで見てください。
wavファイルをmp3ファイル(192kbps)へのコンバート
今回はffmpegというツールを使いました。
クロスプラットフォーム対応なので、windows・mac・linuxで使えます。
/Applications/ffmpeg -i "cx.wav" -vn -ac 2 -ar 44100 -ab 196k -acodec libmp3lame -f mp3 "cx_196k.mp3"
ffmpeg version N-107001-g478e1a98a2-tessus Copyright (c) 2000-2022 the FFmpeg developers
built with Apple clang version 11.0.0 (clang-1100.0.33.17)
configuration: --cc=/usr/bin/clang --prefix=/opt/ffmpeg --extra-version=tessus --enable-avisynth --enable-fontconfig --enable-gpl --enable-libaom --enable-libass --enable-libbluray --enable-libdav1d --enable-libfreetype --enable-libgsm --enable-libmodplug --enable-libmp3lame --enable-libmysofa --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenh264 --enable-libopenjpeg --enable-libopus --enable-librubberband --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libtheora --enable-libtwolame --enable-libvidstab --enable-libvmaf --enable-libvo-amrwbenc --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxavs --enable-libxvid --enable-libzimg --enable-libzmq --enable-libzvbi --enable-version3 --pkg-config-flags=--static --disable-ffplay
libavutil 57. 25.100 / 57. 25.100
libavcodec 59. 32.100 / 59. 32.100
libavformat 59. 24.100 / 59. 24.100
libavdevice 59. 6.100 / 59. 6.100
libavfilter 8. 39.100 / 8. 39.100
libswscale 6. 6.100 / 6. 6.100
libswresample 4. 6.100 / 4. 6.100
libpostproc 56. 5.100 / 56. 5.100
Guessed Channel Layout for Input Stream #0.0 : stereo
Input #0, wav, from 'cx.wav':
Duration: 00:00:24.00, bitrate: 1411 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 44100 Hz, stereo, s16, 1411 kb/s
Stream mapping:
Stream #0:0 -> #0:0 (pcm_s16le (native) -> mp3 (libmp3lame))
Press [q] to stop, [?] for help
Output #0, mp3, to 'cx_196k.mp3':
Metadata:
TSSE : Lavf59.24.100
Stream #0:0: Audio: mp3, 44100 Hz, stereo, s16p, 196 kb/s
Metadata:
encoder : Lavc59.32.100 libmp3lame
size= 564kB time=00:00:24.00 bitrate= 192.4kbits/s speed=12.8x
video:0kB audio:563kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.116335%
ls -lth | grep cx-rw-r--r--@ 1 hinomaruc staff 564K 10 15 23:13 cx_196k.mp3 -rw-r--r--@ 1 hinomaruc staff 4.0M 10 15 22:50 cx.wav
サイズが4.0Mから564Kに減りました (約1/8のサイズ)
試しに両方のファイルの音声を聴いてみましたが、私の耳では違いが分かりませんでした 笑
色々試してみた結果、違いが明確に分かったのがmp3ファイル(64kbps)でした 泣
音の透明度が違うように思います。
音質を悪くしたwavファイルの作成
ダウンサンプリングというらしいです。
サンプリング周波数を44.1kHzから8kHzに下げてみます。
librosaという音声解析のライブラリを使います。
python3 -m pip install librosa ・・・省略・・・ Successfully installed appdirs-1.4.4 importlib-metadata-5.0.0 joblib-1.2.0 librosa-0.9.2 llvmlite-0.39.1 numba-0.56.3 pooch-1.6.0 resampy-0.4.2 scikit-learn-1.1.2 scipy-1.9.2 threadpoolctl-3.1.0 zipp-3.9.0
import librosa
import soundfile as sf
# cx.wavファイルを読み込む(波形データとサンプルレートをyとsr変数に格納する)
# mono=Falseにしないとステレオではなく、モノラルになってしまう。
y, sr = librosa.load('/Users/hinomaruc/Desktop/blog/dataset/audio/cx.wav', sr=44100, mono=False)
# ダウンサンプリング 44.1kHz to 8kHz
y_8k = librosa.resample(y, orig_sr=sr, target_sr=8000)
# ダウンサンプリングした音声データを8kHzで出力する
# 出力するときにyを転置しないとエラーになる(ステレオで出力するため)。モノラルでは転置は必要ない
sf.write('/Users/hinomaruc/Desktop/blog/dataset/audio/cx_8khz.wav', y_8k.T, 8000)data, samplerate = sf.read('/Users/hinomaruc/Desktop/blog/dataset/audio/cx_8khz.wav')
print(samplerate)8000
きちんとダウンサンプリングされていそうです。
WindowsのエクスプローラーやMacのFinderでファイルを右クリックして詳細情報にもサンプリング周波数の記載があると思います。(Macは確認済み)
ここでリサンプリングしたデータがきちんとステレオになっているか確認してください。私は音質がガクッと下がったのではまりました。
44.1kHzと8kHzの音声を聴き比べてみましたが、かなり違いました。
8kHzになると音がもやっとして不明瞭になる印象を持ちました。
スペクトル解析で音声データを可視化する
librosaを使って音声データを可視化することが出来ます。
また音声データ確認用に、jupyter notebook上で音楽を聴くwidgetを使っています。
こんなのです。→ 
ブログでは画像なので再生ボタンを押しても音楽は流れませんでご注意ください 笑 (実際にコードをjupyter上で実行してください。)
import numpy as np
import matplotlib.pyplot as plt
import librosa
import librosa.display# 描画設定
from matplotlib import ticker
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)cx.wavの確認
# 参考: https://librosa.org/doc/main/auto_examples/plot_display.html
y, sr = librosa.load('/Users/hinomaruc/Desktop/blog/dataset/audio/cx.wav',sr=41100, mono=False)
print(sr)
# 音声をiPython.widgetで聴いて確認する
from IPython.display import Audio
Audio(data=y, rate=sr)41100
# ステレオなので、LとR両方を可視化してみた。どちらかでいいかも
for i in [0,1]:
D = librosa.stft(y[i]) # Short Term Fourie Transform of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max) # mapping the magnitudes to a decibel scale
fig, ax = plt.subplots()
img = librosa.display.specshow(S_db, x_axis='time', y_axis='log', ax=ax, sr=44100)
ax.set(title='Using a logarithmic frequency axis (' + str(i) + ')')
ax.label_outer()
ax.set_yticks([0, 64, 128, 256, 512, 1024,2048,4096,8192,16384,32768])
fig.colorbar(img, ax=ax, format="%+2.f dB")
plt.show()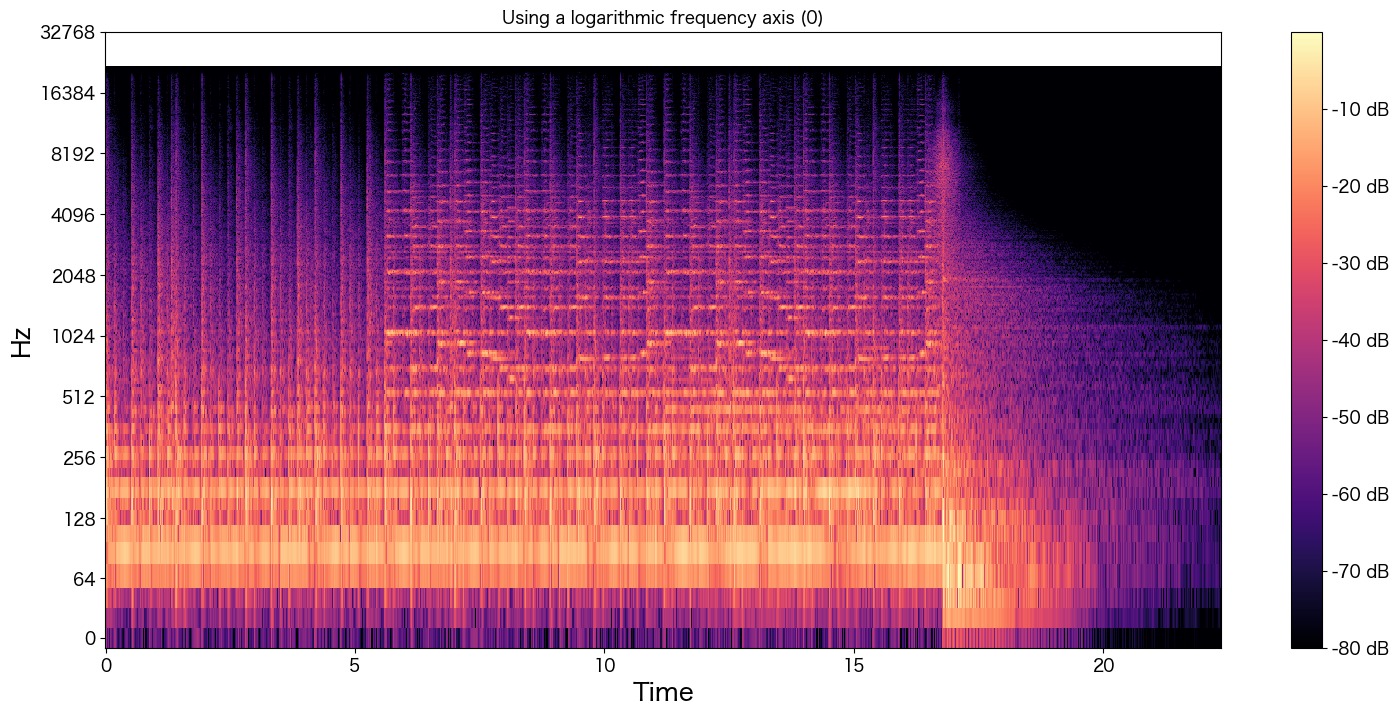
3パートぐらいに音が分かれているような波形になっています。
「0 ~ 7秒まで」、「7 ~ 18秒まで」、「18秒以降」で音が調子が変化しているのが分かりますね。
実際の音声を聴いていただけるとだいたいそのような構成になっているのが分かります。
cx_8khz.wavの確認
y, sr = librosa.load('/Users/hinomaruc/Desktop/blog/dataset/audio/cx_8khz.wav',sr=8000, mono=False)
print(sr)
# IPython.display's Audio widget
from IPython.display import Audio
Audio(data=y, rate=sr)8000
# ステレオなので、LとR両方を可視化してみた。どちらかでいいかも
for i in [0,1]:
D = librosa.stft(y[i]) # Short Term Fourie Transform of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max) # mapping the magnitudes to a decibel scale
fig, ax = plt.subplots()
img = librosa.display.specshow(S_db, x_axis='time', y_axis='log', ax=ax, sr=8000)
ax.set(title='Using a logarithmic frequency axis (' + str(i) + ')')
ax.label_outer()
ax.set_yticks([0, 64, 128, 256, 512, 1024,2048,4096,8192])
fig.colorbar(img, ax=ax, format="%+2.f dB")
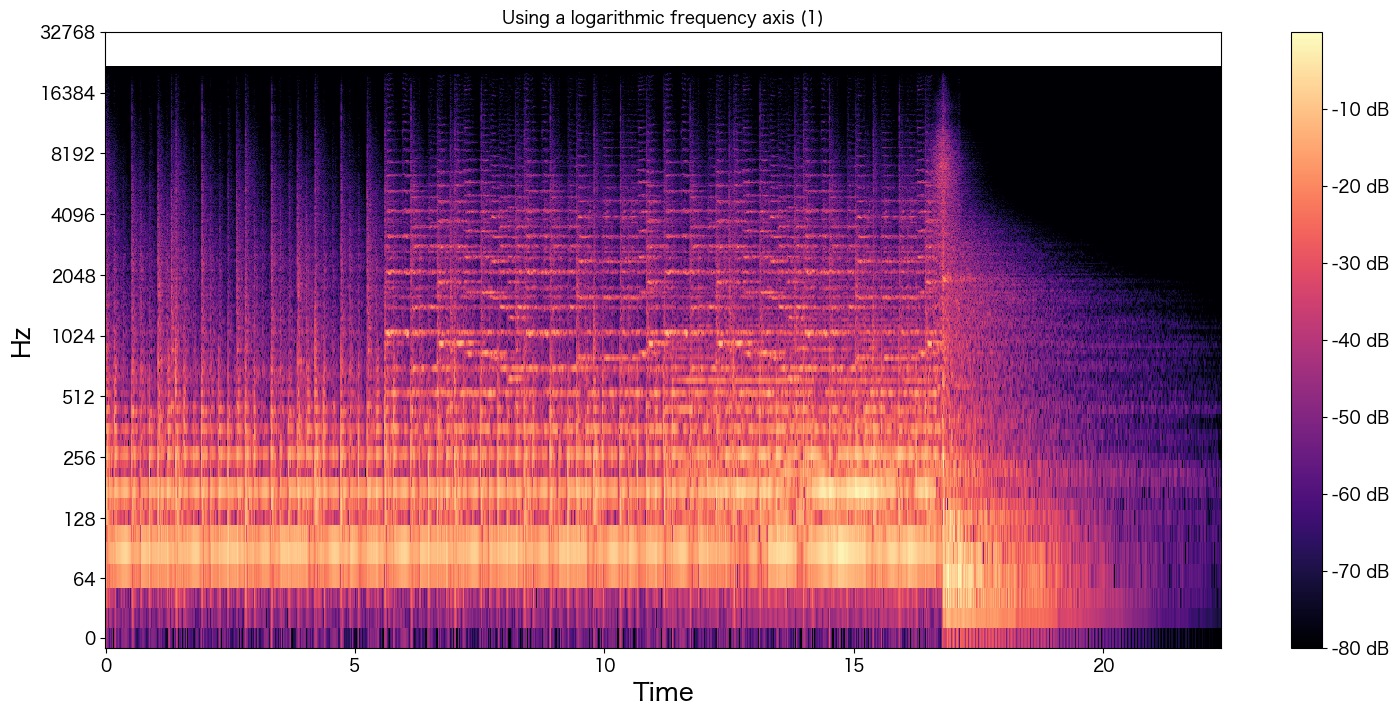
plt.show()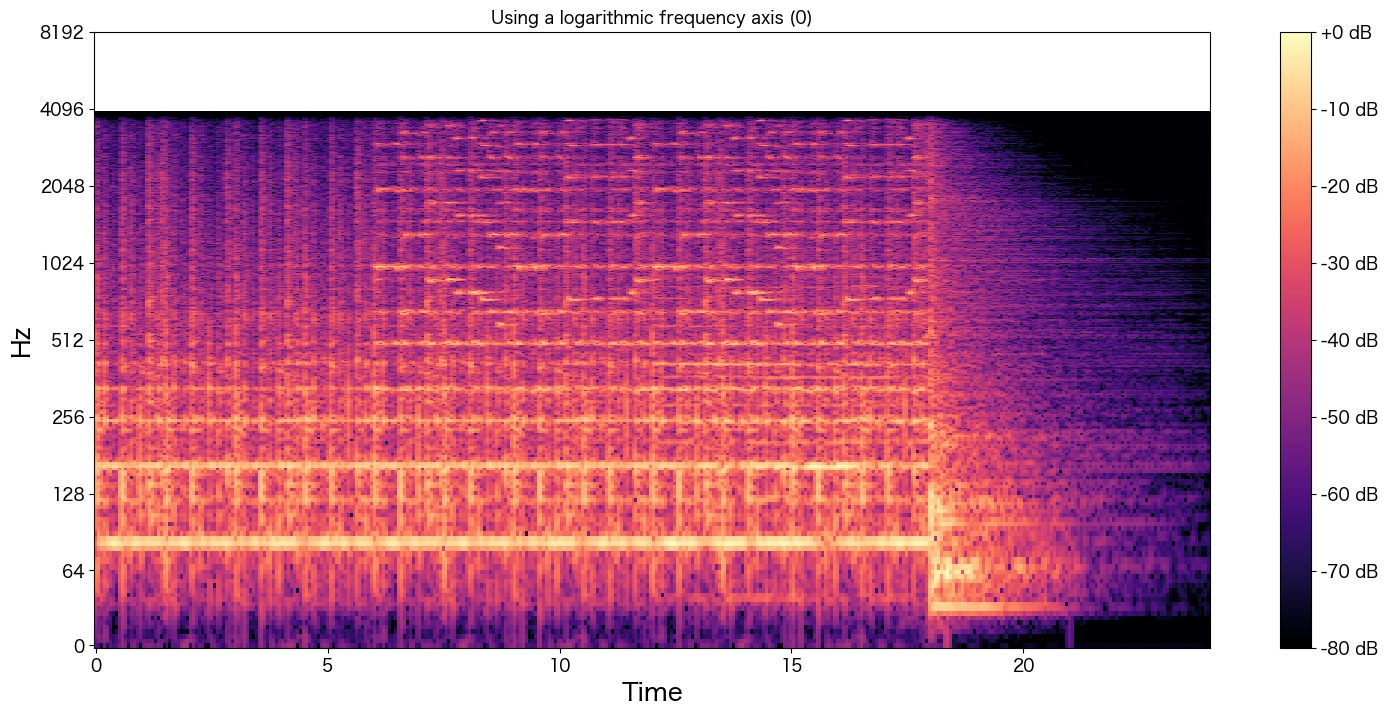
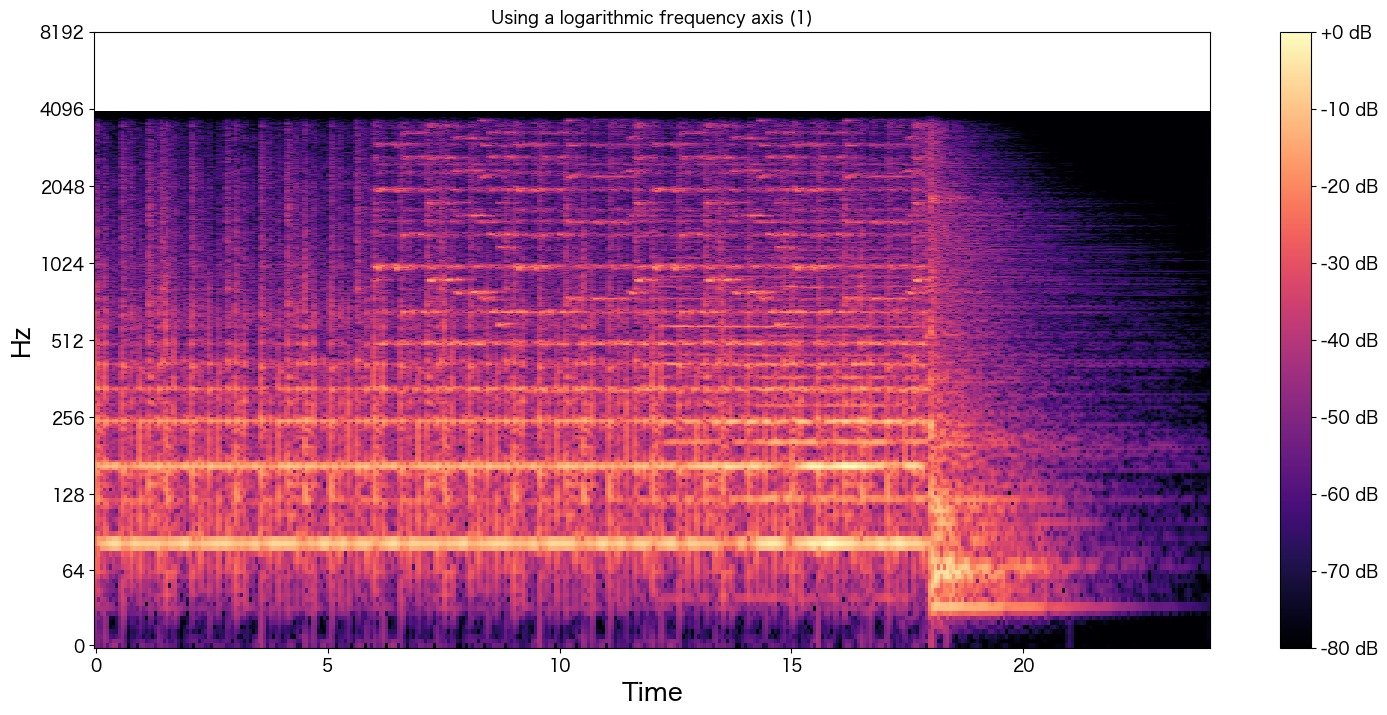
8kHzの半分の4kHzあたりでしょうか?Hzが途中でばっさり切られているのが分かります。
他の音声ファイル(a-place-dear-to-ones-heart_320k.mp3)も確認
「アイキャッチ1」ではない、違う音声ファイルも解析してみました。
ダウンロードした時にファイル名が「Home」ではなく、「a-place-dear-to-ones-heart.wav」でしたのでそのままにしています。
事前に320kbpsのmp3に変換済みです。
ぜひご自分の好きな音楽で試してみてください。長すぎる場合はlibrosaでの読み込みの時にduration=30オプションで秒数を指定して読み込みができます。
# 最初の15秒だけ読み込む
y, sr = librosa.load('/Users/hinomaruc/Desktop/blog/dataset/audio/a-place-dear-to-ones-heart_320k.mp3', duration=15,sr=41100, mono=False)
print(sr)
# 音声をiPython.widgetで聴いて確認する
from IPython.display import Audio
Audio(data=y, rate=sr)41100

# ステレオなので、LとR両方を可視化してみた。どちらかでいいかも
for i in [0,1]:
D = librosa.stft(y[i]) # Short Term Fourie Transform of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max) # mapping the magnitudes to a decibel scale
fig, ax = plt.subplots()
img = librosa.display.specshow(S_db, x_axis='time', y_axis='log', ax=ax, sr=44100)
ax.set(title='Using a logarithmic frequency axis (' + str(i) + ')')
ax.label_outer()
ax.set_yticks([0, 64, 128, 256, 512, 1024,2048,4096,8192,16384,32768])
fig.colorbar(img, ax=ax, format="%+2.f dB")
plt.show()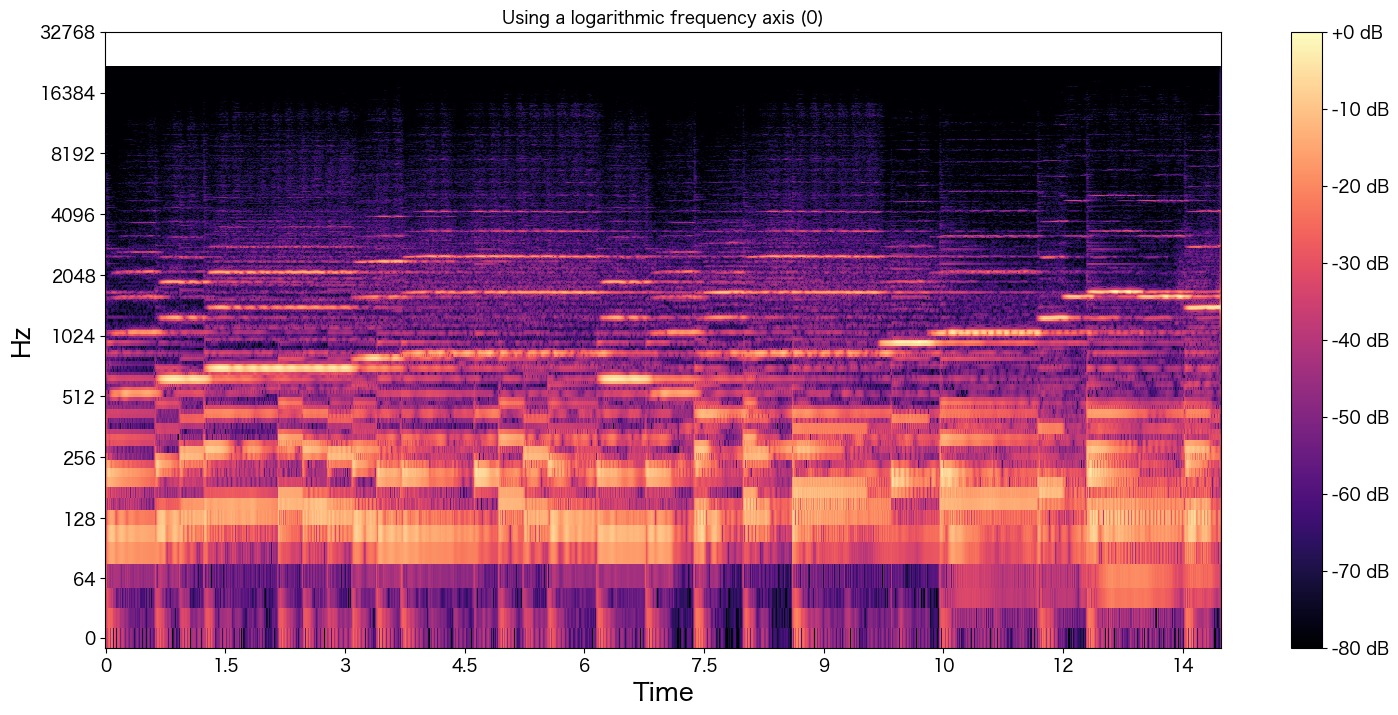
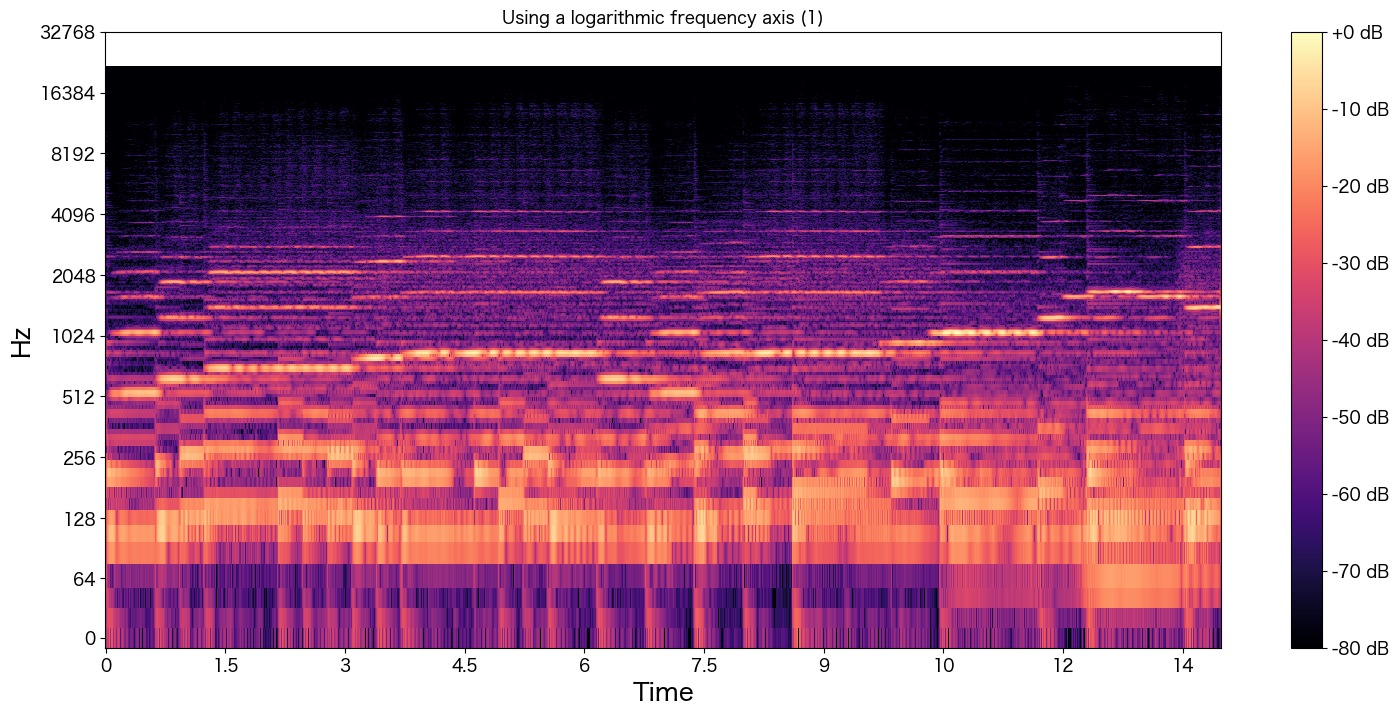
mp3ファイルだからか圧縮時に高い周波数の音は削除されているようにも見えます。(20kHz近くがほとんどなさそう?)
とはいえ320kbpsの音声ファイルを使ったので音質はいいです 笑
HiFi-GAN+モデルを使ってみる
hifi-gan-bweのインストール
python3 -m pip install --upgrade hifi-gan-bwe・・・省略・・・ Successfully installed Click-8.1.3 GitPython-3.1.29 PyYAML-6.0 audioread-3.0.0 certifi-2022.9.24 cffi-1.15.1 charset-normalizer-2.1.1 contourpy-1.0.5 cycler-0.11.0 docker-pycreds-0.4.0 fonttools-4.37.4 gitdb-4.0.9 hifi-gan-bwe-0.1.14 idna-3.4 kiwisolver-1.4.4 matplotlib-3.6.1 numpy-1.23.4 pathtools-0.1.2 pillow-9.2.0 promise-2.3 protobuf-4.21.7 pycparser-2.21 requests-2.28.1 sentry-sdk-1.9.10 setproctitle-1.3.2 shortuuid-1.0.9 smmap-5.0.0 soundfile-0.11.0 torch-1.12.1 torchaudio-0.12.1 tqdm-4.64.1 typing-extensions-4.4.0 urllib3-1.26.12 wandb-0.13.4
HiFi-GAN+モデルの適用 (cx_8khz.wav)
8kHzにダウンサンプリングしたオーディオファイルをモデルにかけてみます。
import audioread
import numpy as np
import torch
from IPython.display import Audio
from hifi_gan_bwe import BandwidthExtender# 適用するモデルの選択
# https://github.com/brentspell/hifi-gan-bwe#pretrained-models
model = BandwidthExtender.from_pretrained("hifi-gan-bwe-10-42890e3-vctk-48kHz")
path = '/Users/hinomaruc/Desktop/blog/dataset/audio/cx_8khz.wav'
# https://pypi.org/project/audioread/
# 音声の読み込み
with audioread.audio_open(path) as f:
print(f.channels, f.samplerate, f.duration)
sample_rate = f.samplerate
x = (np.hstack([np.frombuffer(b, dtype=np.int16) for b in f]).reshape([-1, f.channels]).astype(np.float32) / 32767.0)
# モデルの適用
with torch.no_grad():
y = np.stack([model(torch.from_numpy(x), sample_rate) for x in x.T]).T
# 確認
Audio(y.T, rate=int(model.sample_rate), autoplay=True)2 8000 24.0
HiFi-GAN+モデルを適用したデータをwavファイルに出力する
# wavファイルに出力
sf.write("/Users/hinomaruc/Desktop/blog/dataset/audio/r_cx_8khz.wav", y, samplerate=int(model.sample_rate))
# numpyデータをsave & loadする場合
# np.save('/Users/hinomaruc/Desktop/blog/dataset/audio/r_cx_8khz', y)
# y = np.load('/Users/hinomaruc/Desktop/blog/dataset/audio/r_cx_8khz.npy')HiFi-GAN+モデルを適用したwavファイルの解析
y, sr = librosa.load('/Users/hinomaruc/Desktop/blog/dataset/audio/r_cx_8khz.wav',sr=48000, mono=False)
print(sr)
# IPython.display's Audio widget
from IPython.display import Audio
Audio(data=y, rate=sr)48000
# ステレオなので、LとR両方を可視化してみた。どちらかでいいかも
for i in [0,1]:
D = librosa.stft(y[i]) # Short Term Fourie Transform of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max) # mapping the magnitudes to a decibel scale
fig, ax = plt.subplots()
img = librosa.display.specshow(S_db, x_axis='time', y_axis='log', ax=ax, sr=48000)
ax.set(title='Using a logarithmic frequency axis (' + str(i) + ')')
ax.label_outer()
ax.set_yticks([0, 64, 128, 256, 512, 1024,2048,4096,8192,16384,32768])
fig.colorbar(img, ax=ax, format="%+2.f dB")
plt.show()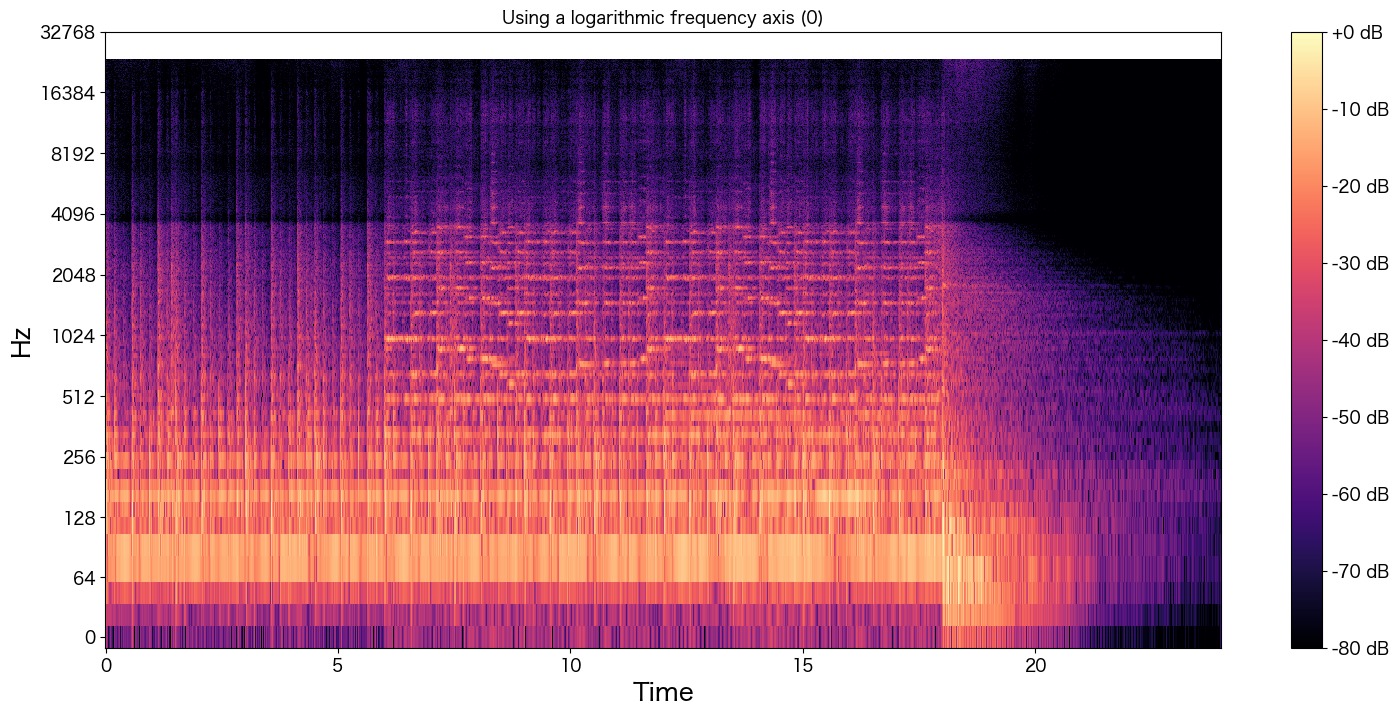
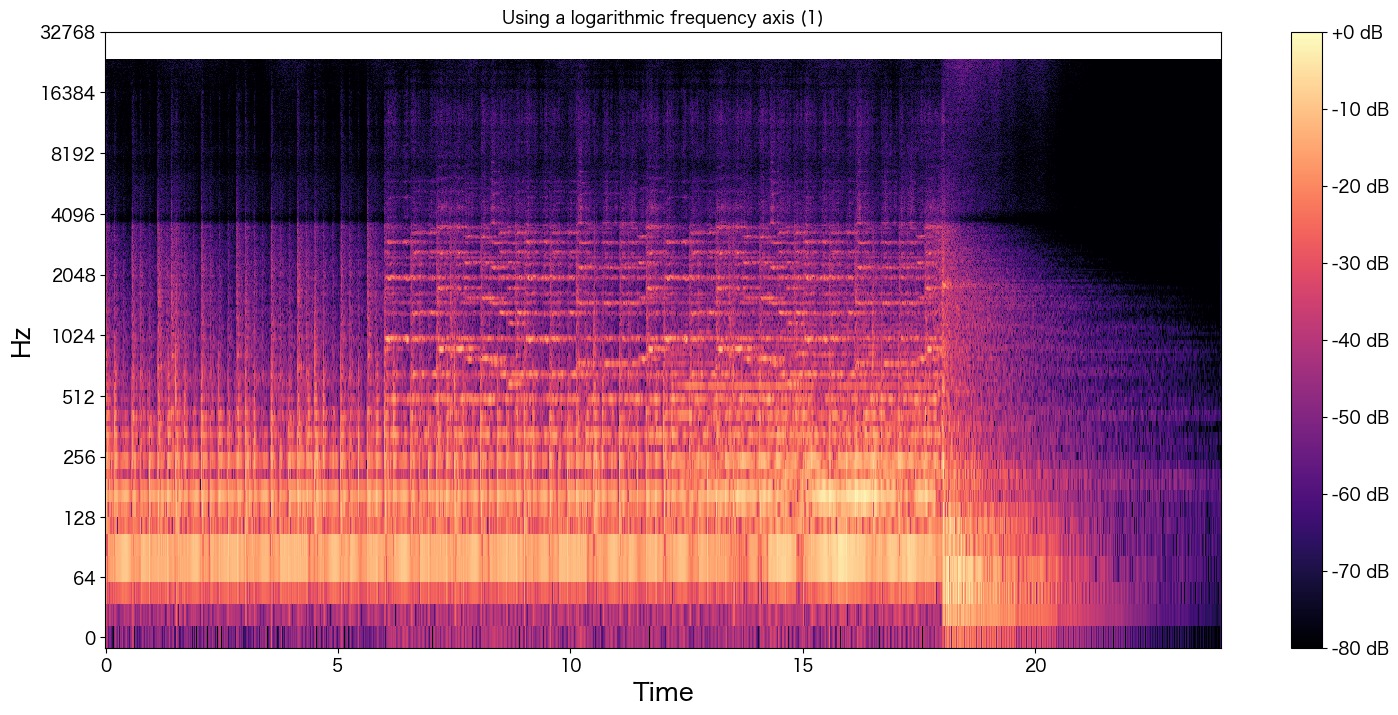
4000Hzよりも高音域の波形が存在することが分かります。cx.wavのグラフと比較するとどうでしょうか?
何となく全体のボリューム感は復元できていそうでしょうか?
中盤の波形「7 ~ 18秒まで」はあまり上手に元の音声を表現できていないかも知れませんが、少なくとも音質はあがっていそうです。
元々よい音質のmp3ファイルに対してHiFi-GAN+モデルを適用してみる
48kHzに変換してくれるのでもしかしたら41.1kHzよりも高音質になってくれるかも知れませんし、mp3化により失われた高音域も復元してくれるかも知れませんので試してみます。
# 適用するモデルの選択
# https://github.com/brentspell/hifi-gan-bwe#pretrained-models
model = BandwidthExtender.from_pretrained("hifi-gan-bwe-10-42890e3-vctk-48kHz")
path = '/Users/hinomaruc/Desktop/blog/dataset/audio/a-place-dear-to-ones-heart_320k.mp3'
# https://pypi.org/project/audioread/
# 音声の読み込み
with audioread.audio_open(path) as f:
print(f.channels, f.samplerate, f.duration)
sample_rate = f.samplerate
x = (np.hstack([np.frombuffer(b, dtype=np.int16) for b in f]).reshape([-1, f.channels]).astype(np.float32) / 32767.0)
# モデルの適用
with torch.no_grad():
y = np.stack([model(torch.from_numpy(x), sample_rate) for x in x.T]).T
# 確認
Audio(y.T, rate=int(model.sample_rate), autoplay=True)2 44100 21.098956916099773

# save the output file
sf.write("/Users/hinomaruc/Desktop/blog/dataset/audio/r_a-place-dear-to-ones-heart_320k.wav", y, samplerate=int(model.sample_rate))y, sr = librosa.load('/Users/hinomaruc/Desktop/blog/dataset/audio/r_a-place-dear-to-ones-heart_320k.wav',sr=48000, mono=False)
print(sr)
# ステレオなので、LとR両方を可視化してみた。どちらかでいいかも
for i in [0,1]:
D = librosa.stft(y[i]) # Short Term Fourie Transform of y
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max) # mapping the magnitudes to a decibel scale
fig, ax = plt.subplots()
img = librosa.display.specshow(S_db, x_axis='time', y_axis='log', ax=ax, sr=48000)
ax.set(title='Using a logarithmic frequency axis (' + str(i) + ')')
ax.label_outer()
ax.set_yticks([0, 64, 128, 256, 512, 1024,2048,4096,8192,16384,32768])
fig.colorbar(img, ax=ax, format="%+2.f dB")
plt.show()48000
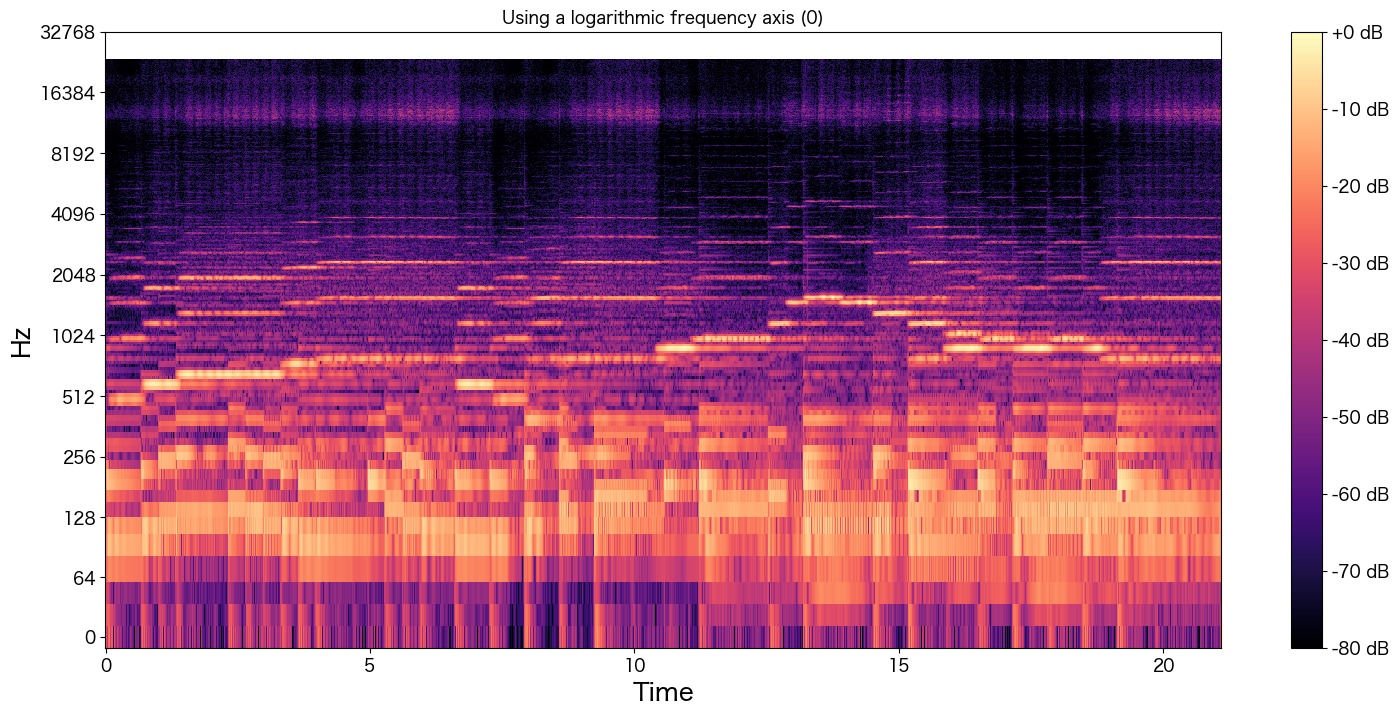
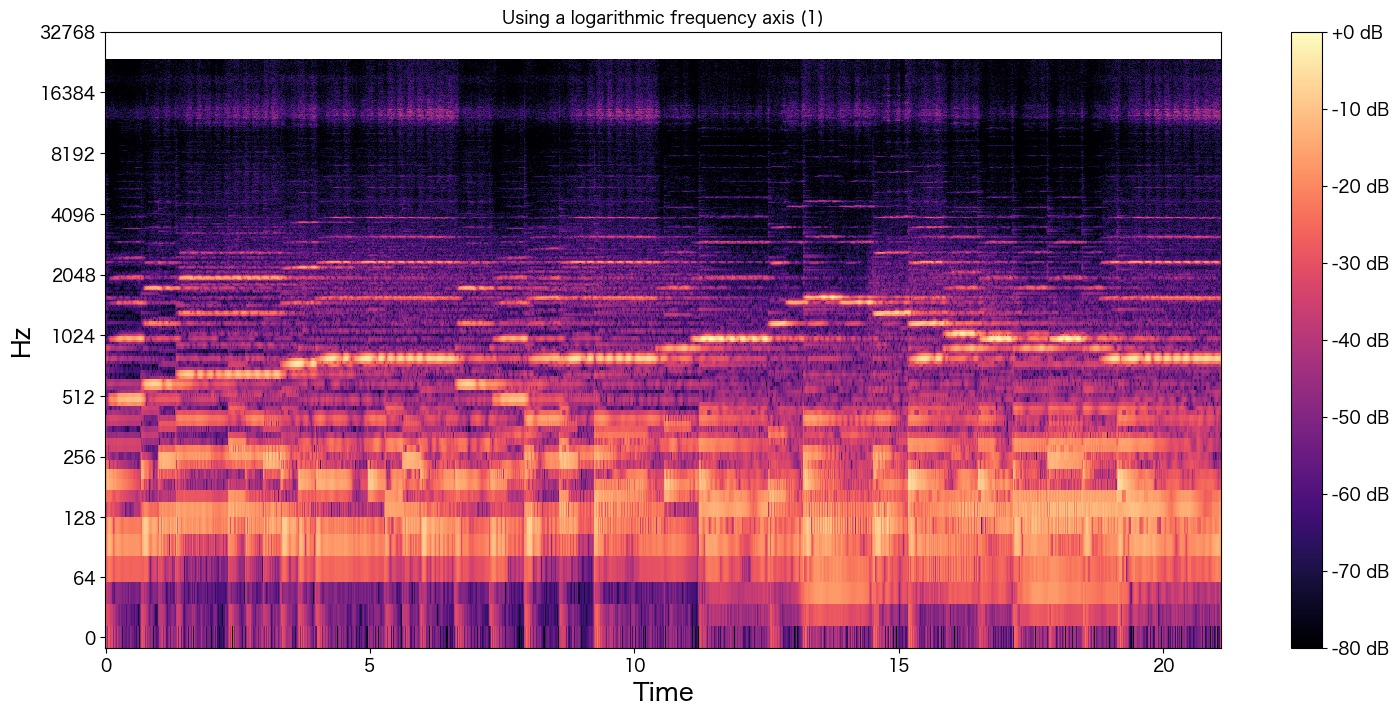
高音域も復元されているように見えます。確かに高音がクリアで綺麗になったように聴こえました。
まとめ
「音」の世界はとても興味深くまだまだ勉強したりないことがありますがHiFi-GAN+モデルを適用することによって音声データの高音質化を実現することができました。
ただCPUだと1分ほどのデータをインプットにしただけでも結果が出るのにかなり時間がかかりました。。体感10分くらいでしょうか。可能であればやはりGPUを使った方がいいですね。