アノテーションや物体検知のために画像の一部分を黒く塗りつぶしたいという要件が出てきました。例えばアノテーションだと不必要な物体までアノテーションする必要は無くなりますし、物体検知も必要ない部分は検知しなくても良くなります。
「YOLOv8で特定のエリアのみ物体検知する方法」でも画像の一部分を黒塗りして物体検知に活用していますが、もっと複雑な形で黒く塗りつぶしたいという欲求を叶えたいと思います 笑
四角形ではなく、様々な形のポリゴンを描画すれば可能かなと思いやってみました。ただポリゴンを描画するにはピクセルの位置を特定する必要があります。
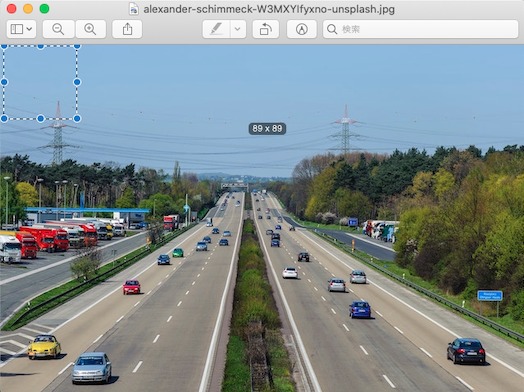
Macだと良さそうなツールがなく、Previewを使えば出来なくはないですが、下記のようにピクセルの位置を特定するのに左上から点線のボックスを描画することによってピクセルのコーディネートが分かります。「YOLOv8で指定領域内の精度と物体検知数を出力する方法」ではPreviewを使ってピクセルの位置をちまちま特定しました 笑
ちなみにここまではMacの話で、WindowsだとMicrosoft Paintを使えばピクセルの位置も分かりますし、黒塗りも比較的簡単にできるのではないかと思います。
ポリゴン描画ツールの起動
それではやってみます。長いコードになりますが、実行すればそのまま使えると思います。(GUIツール化してみようかと思案中です)
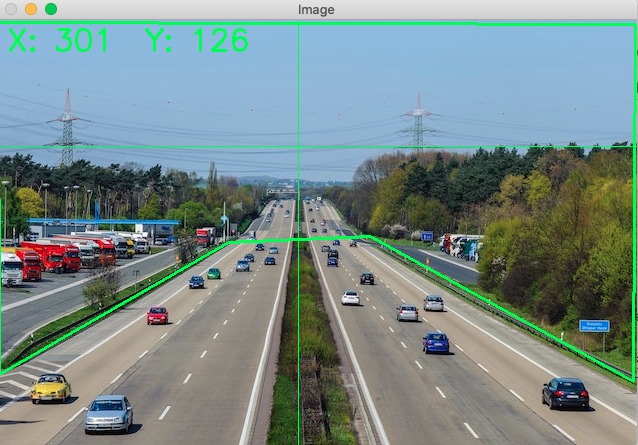
使い方はシンプル(のはず)。
・XがX軸のピクセルの値でYがY軸のピクセルの値になります。マウスを画像上で動かすと動的に変わります。
・ポリゴンを描くにはクリックで線を描いていきます。間違ったら「d」キーを押したら消せます。
・最終的に2つの線が近くに重なりそうになったら自動的にポリゴンを閉じるようになっています。
・ポリゴンが作成されたら、ログにポリゴンのコーディネートが出力されます。
・終了する時は「q」キーを押してください。
import cv2
import numpy as np
# 変数定義
drawing = False
polygons = []
current_polygon = []
min_distance = 10 # 距離
# マウスコールバック
def mouse_callback(event, x, y, flags, param):
global polygons, current_polygon
if event == cv2.EVENT_MOUSEMOVE:
# x,yの更新
param['x'] = x
param['y'] = y
elif event == cv2.EVENT_LBUTTONDOWN:
# ポリゴンを作成する
if len(current_polygon) > 4 and is_close_enough(x, y, current_polygon[0][0], current_polygon[0][1]):
polygons.append(current_polygon)
print("Polygon Coordinates:", current_polygon) # コーディネートを出力しておく
current_polygon = []
else:
current_polygon.append((x, y))
# 2つのポイント間の距離
def is_close_enough(x1, y1, x2, y2):
distance = np.sqrt((x2 - x1)**2 + (y2 - y1)**2)
return distance <= min_distance
# 画像の読み込み
image = cv2.imread("/Users/hinomaruc/Desktop/blog/dataset/aidetection_cars/alexander-schimmeck-W3MXYIfyxno-unsplash.jpg")
output_image = image.copy()
# ウィンドウの作成
cv2.namedWindow("Image")
mouse_coords = {'x': -1, 'y': -1}
cv2.setMouseCallback("Image", mouse_callback, mouse_coords)
while True:
output_image = image.copy()
# ポリゴンの描画
for polygon in polygons:
pts = np.array(polygon, np.int32)
pts = pts.reshape((-1, 1, 2))
cv2.polylines(output_image, [pts], True, (0, 255, 0), 2)
# 現在描画中のポリゴン
if len(current_polygon) > 0:
pts = np.array(current_polygon, np.int32)
pts = pts.reshape((-1, 1, 2))
cv2.polylines(output_image, [pts], False, (0, 255, 0), 2)
# カーソルのコーディネートをテキストとして描画
text = f"X: {mouse_coords['x']} Y: {mouse_coords['y']}"
cv2.putText(output_image, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 十字キーの描画
cv2.line(output_image, (mouse_coords['x'], 0), (mouse_coords['x'], image.shape[0]), (0, 255, 0), 1)
cv2.line(output_image, (0, mouse_coords['y']), (image.shape[1], mouse_coords['y']), (0, 255, 0), 1)
cv2.imshow("Image", output_image)
key = cv2.waitKey(1) & 0xFF
# 最後に作成したポリゴンの削除 (dを押下)
if key == ord('d'):
if len(polygons) > 0:
polygons.pop()
current_polygon = []
# 終了 (qを押下)
if key == ord('q'):
break
# ウィンドウのクローズ
cv2.destroyAllWindows()Polygon Coordinates: [(638, 4), (636, 361), (373, 216), (231, 222), (2, 354), (1, 2)]
ポリゴンを黒く塗りつぶした画像を作成する
ポリゴンのコーディネートが分かればいいという方はここまでOKですが、ポリゴンを黒く塗りつぶした画像を作成したい場合は下記コードを実行します。
作成したポリゴンのコーディネートをpolygon_verticesに入力してください。複数ポリゴンも渡しても動作するはずです。
from PIL import Image, ImageDraw
# ポリゴンの指定
polygon_vertices = [(638, 4), (636, 361), (373, 216), (231, 222), (2, 354), (1, 2)]
# パスの指定
original_image_path = "/Users/hinomaruc/Desktop/blog/dataset/aidetection_cars/alexander-schimmeck-W3MXYIfyxno-unsplash.jpg"
new_image_path = "/Users/hinomaruc/Desktop/alexander-schimmeck-W3MXYIfyxno-unsplash_modified.jpg"
# 画像の読み込みと新しい画像イメージに作成
original_image = Image.open(original_image_path)
new_image = Image.new(original_image.mode, original_image.size)
# 元の画像に残したい部分を白色、それ以外を黒色の背景にしたマスク画像を作成
mask = Image.new("L", original_image.size, 255)
draw = ImageDraw.Draw(mask)
draw.polygon(polygon_vertices, fill=0)
# 元画像にマスク画像を貼り付ける
new_image.paste(original_image, (0, 0), mask)
new_image.save(new_image_path)
# 閉じる
original_image.close()
new_image.close()
どうでしょうか?便利ですね 笑 レイアウトが決まっている画像だったりするとこの処理を関数化してあげて、ループで処理させてあげると良いと思います。(名称は動的に変えてあげる必要あり)
アノテーションはバリエーションを持たせるため元画像にある物体をなるべく含めてあげると良いかと思いますが、ある程度画角も検知させたい物体の形状も決まっているのであればノイズを減らせるので不必要な部分をカットするのは意外と有効な手段だと考えています。
