前回、ロジスティック回帰のモデルで75%の精度でした。
(その4-2) タイタニックの乗客の生存有無をロジスティック回帰分析で予測してみた。
前回、決定木モデルで70%の精度でした。今回はロジスティック回帰を使って予測してみようと思います。私が一番好きなモデルで実業務でもよく使っています。評価指標タイタニックのデータセットは生存有無を正確に予測できた乗客の割合(Accuracy)...
www.hinomaruc.com
2023.04.28
今回はSupport vector machine(SVM)を使って予測してみようと思います。
評価指標
タイタニックのデータセットは生存有無を正確に予測できた乗客の割合(Accuracy)を評価指標としています。
SVM
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
タイタニックのモデリング用データの作成まとめ
(その3-5) タイタニックのデータセットの変数選択にてモデリング用のデータを作成し、エクスポートするコードを記載していましたが分かりずらかったので簡略しまとめました。上から順に流していけばtitanic_train.csvとtitanic...
www.hinomaruc.com
2022.09.25
学習データと評価データの読み込み
import pandas as pd
import numpy as np
# タイタニックデータセットの学習用データと評価用データの読み込み
df_train = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_train.csv")
df_eval = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_eval.csv")概要確認
# 概要確認
df_train.info()Out[0]
RangeIndex: 891 entries, 0 to 890
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 891 non-null object
12 FamilyCnt 891 non-null int64
13 SameTicketCnt 891 non-null int64
14 Pclass_str_1 891 non-null float64
15 Pclass_str_2 891 non-null float64
16 Pclass_str_3 891 non-null float64
17 Sex_female 891 non-null float64
18 Sex_male 891 non-null float64
19 Embarked_C 891 non-null float64
20 Embarked_Q 891 non-null float64
21 Embarked_S 891 non-null float64
dtypes: float64(10), int64(7), object(5)
memory usage: 153.3+ KB
# 概要確認
df_eval.info()Out[0]
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 418 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 418 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
11 Pclass_str_1 418 non-null float64
12 Pclass_str_2 418 non-null float64
13 Pclass_str_3 418 non-null float64
14 Sex_female 418 non-null float64
15 Sex_male 418 non-null float64
16 Embarked_C 418 non-null float64
17 Embarked_Q 418 non-null float64
18 Embarked_S 418 non-null float64
19 FamilyCnt 418 non-null int64
20 SameTicketCnt 418 non-null int64
dtypes: float64(10), int64(6), object(5)
memory usage: 68.7+ KB
# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)モデル作成
# https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
clf = make_pipeline(StandardScaler(), SVC(gamma='auto',random_state=0))# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(df_train, test_size=0.20,random_state=100)
# 説明変数
FEATURE_COLS=[
'Age'
, 'Fare'
, 'SameTicketCnt'
, 'Pclass_str_1'
, 'Pclass_str_3'
, 'Sex_female'
, 'Embarked_Q'
, 'Embarked_S'
]
X_train = x_train[FEATURE_COLS] # 説明変数 (train)
Y_train = x_train["Survived"] # 目的変数 (train)
X_test = x_test[FEATURE_COLS] # 説明変数 (test)
Y_test = x_test["Survived"] # 目的変数 (test)model = clf.fit(X_train,Y_train)モデルの精度の確認
# 訓練データへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
model.score(X_train,Y_train)Out[0]
0.8398876404494382
# テストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
model.score(X_test,Y_test)Out[0]
0.8268156424581006
ロジスティック回帰よりテストデータへの当てはまりがよくなったようです。
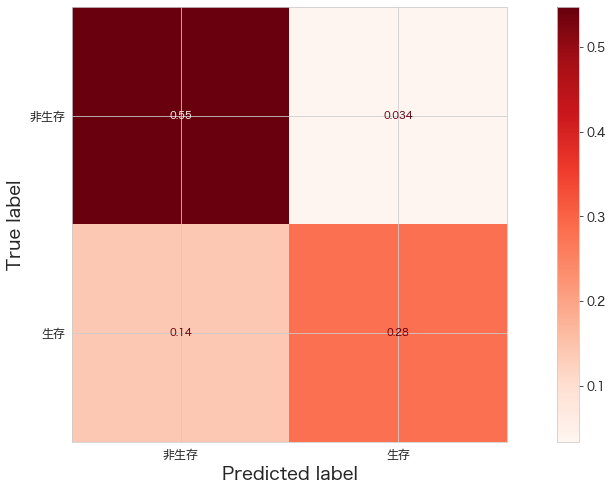
confusion matrixの確認
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_estimator(clf,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()Out[0]
# モデルパラメーターの確認
model.get_params()Out[0]
{'memory': None,
'steps': [('standardscaler', StandardScaler()),
('svc', SVC(gamma='auto', random_state=0))],
'verbose': False,
'standardscaler': StandardScaler(),
'svc': SVC(gamma='auto', random_state=0),
'standardscaler__copy': True,
'standardscaler__with_mean': True,
'standardscaler__with_std': True,
'svc__C': 1.0,
'svc__break_ties': False,
'svc__cache_size': 200,
'svc__class_weight': None,
'svc__coef0': 0.0,
'svc__decision_function_shape': 'ovr',
'svc__degree': 3,
'svc__gamma': 'auto',
'svc__kernel': 'rbf',
'svc__max_iter': -1,
'svc__probability': False,
'svc__random_state': 0,
'svc__shrinking': True,
'svc__tol': 0.001,
'svc__verbose': False}
クロスバリデーションで精度を確認
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
# StratifiedKFold with KFold = 10
from sklearn.model_selection import cross_val_score
X = df_train[FEATURE_COLS] # 説明変数 (train)
Y = df_train["Survived"] # 目的変数 (train)
np.mean(cross_val_score(clf, X, Y, cv=10,verbose=3))Out[0]
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers. [Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s [Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.2s remaining: 0.0s [CV] END ................................ score: (test=0.844) total time= 0.1s [CV] END ................................ score: (test=0.798) total time= 0.1s [CV] END ................................ score: (test=0.775) total time= 0.1s [CV] END ................................ score: (test=0.876) total time= 0.1s [CV] END ................................ score: (test=0.865) total time= 0.1s [CV] END ................................ score: (test=0.820) total time= 0.1s [CV] END ................................ score: (test=0.820) total time= 0.1s [CV] END ................................ score: (test=0.775) total time= 0.1s [CV] END ................................ score: (test=0.843) total time= 0.1s [CV] END ................................ score: (test=0.831) total time= 0.1s [Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 0.7s finished 0.8248938826466917
82%でした。
Kaggle提出用データの作成
df_eval["Survived"] = clf.predict(df_eval[FEATURE_COLS])df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)Kaggleへアップロード
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #003. SVM"Out[0]
100%|████████████████████████████████████████| 2.77k/2.77k [00:03<00:00, 716B/s] Successfully submitted to Titanic - Machine Learning from Disaster
コンペの精度確認
Out[0]

77%になりました!
まとめ
SVMの精度は77%でした。
徐々に上がってきてますね。
