今回はAutoMLを試してみたいと思います。AutoMLは今のところ3種類の環境を用意しているのですが本記事ではMLJARというAutoMLライブラリをエイムズのデータセットに試してみたいと思います。
MacでAutoMLの環境をする方法は下記記事にまとめています。pipでインストールしているのがほとんどですので、Linuxでも同じようなコードでインストールできるかと思います。
※ brew install しているのは yum や apt に置き換える必要はあります。
(MLJAR) Pythonで3つのAutoML環境を用意してみた
(AutoGluon) Pythonで3つのAutoML環境を用意してみた
(auto-sklearn) Pythonで3つのAutoML環境を用意してみた
それではやってみます。
評価指標
住宅IdごとのSalePrice(販売価格)を予測するコンペです。
評価指標は予測SalePriceと実測SalePriceの対数を取ったRoot-Mean-Squared-Error(RMSE)の値のようです。

MLJAR
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
(その3-2) エイムズの住宅価格のデータセットのデータ加工①
(その3-3) エイムズの住宅価格のデータセットのデータ加工②
学習用データとスコア付与用データの読み込み
import pandas as pd
import numpy as np
# エイムズの住宅価格のデータセットの訓練データとテストデータを読み込む
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/ames_train.csv")
df_test = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/ames_test.csv")# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)# 説明変数と目的変数を指定
# 学習データ
X_train = df.drop(["Id","SalePrice"],axis=1)
Y_train = df["SalePrice"] # 販売価格
# テストデータ
X_test = df_test.drop(["Id"],axis=1)MLJARでモデルの作成
# https://supervised.mljar.com/api/
# mljarのモデル作成
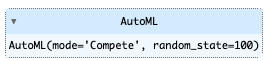
from supervised.automl import AutoML
automl = AutoML(mode="Compete", random_state=100)# fitで学習させる
automl.fit(X_train,Y_train)AutoML directory: AutoML_1 The task is regression with evaluation metric rmse AutoML will use algorithms: ['Decision Tree', 'Linear', 'Random Forest', 'Extra Trees', 'LightGBM', 'Xgboost', 'CatBoost', 'Neural Network', 'Nearest Neighbors'] AutoML will stack models AutoML will ensemble available models AutoML steps: ['adjust_validation', 'simple_algorithms', 'default_algorithms', 'not_so_random', 'golden_features', 'insert_random_feature', 'features_selection', 'hill_climbing_1', 'hill_climbing_2', 'boost_on_errors', 'ensemble', 'stack', 'ensemble_stacked'] * Step adjust_validation will try to check up to 1 model ・・・省略・・・ Ensemble_Stacked rmse 24246.711368 trained in 26.4 seconds AutoML fit time: 3660.06 seconds AutoML best model: Ensemble_Stacked
# 学習データの精度を確認。テストデータへの精度が確認できないので参考程度
print("train",automl.score(X_train,Y_train))train 0.9774953828315942
### モデルを適用し、SalePriceの予測をする
df_test["SalePrice"] = automl.predict(X_test)df_test[["Id","SalePrice"]]
Id SalePrice 0 1461 121357.396517 1 1462 168013.565509 2 1463 181916.642581 3 1464 186828.246474 4 1465 191528.222564 ... ... ... 1454 2915 90059.383585 1455 2916 87930.939078 1456 2917 166045.148323 1457 2918 118191.061911 1458 2919 228410.572345 1459 rows × 2 columns
# SalePrice(予測) の分布を確認
sns.histplot(df_test["SalePrice"],bins=20)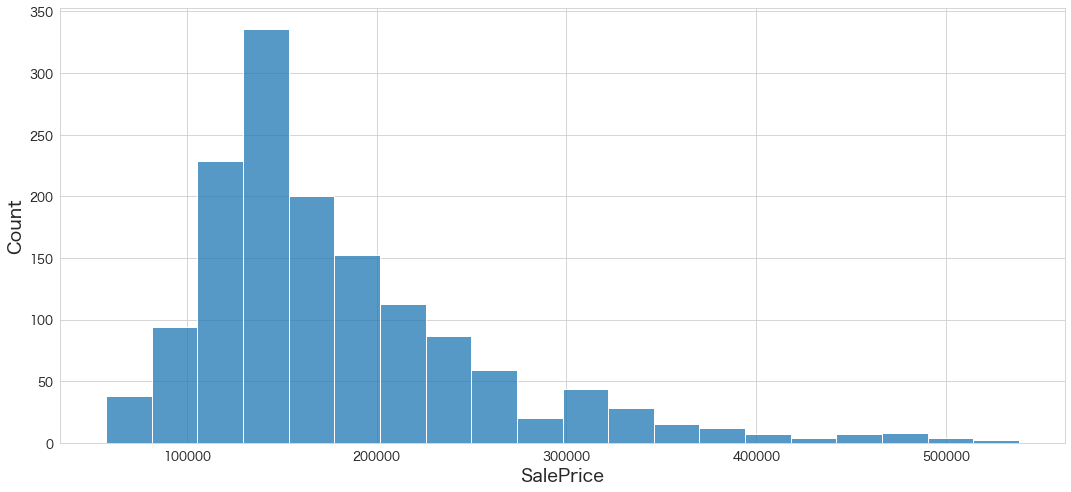
Kaggleにスコア付与結果をアップロード
df_test[["Id","SalePrice"]].to_csv("ames_submission.csv",index=False)!/Users/hinomaruc/Desktop/blog/my-venv/bin/kaggle competitions submit -c house-prices-advanced-regression-techniques -f ames_submission.csv -m "#8 automl mljar"100%|██████████████████████████████████████| 33.7k/33.7k [00:05<00:00, 6.48kB/s] Successfully submitted to House Prices - Advanced Regression Techniques #8 automl mljar Score: 0.12843
今までで一番の精度を出すことが出来ました。
ほんの数行のコードで最高のパフォーマンスを出せるAutoMLはクセになってしまいそうですが、内部的に何をしているか理解することも大切かも知れません。
使用ライブラリのバージョン
pandas Version: 1.4.2
numpy Version: 1.22.4
scikit-learn Version: 1.1.1
seaborn Version: 0.11.2
matplotlib Version: 3.5.2
mljar-supservised: 0.11.2
まとめ
やっぱりAutoMLはすごいですね、分析者のノウハウが詰め込められているのではないかと思います。
他の分析者と差別化をするには、AutoMLにどんなデータを渡すか突き詰める (前処理を頑張る) こともしくは AutoMLでもまだ実装されていない手法を試すなどが考えられるのではないかと思っています。
次回はAutoGluonを試してみたいと思います。
