前回はXgBoostで分類モデルを作成しました。
暫定1位はロジスティック回帰CVで作成してモデルで、Kaggleの精度は0.76794です。
今回はAutoMLを試してみようと思います。
色々なモデルを作成して一番良い精度のものを探索してくれるのでかなりの時間節約になります。
MacでAutoMLの環境をする方法は下記記事にまとめています。pipでインストールしているのがほとんどですので、Linuxでも同じようなコードでインストールできるかも知れません。
※ brew install しているのは yum や apt に置き換える必要はあります。
(MLJAR) Pythonで3つのAutoML環境を用意してみた
(AutoGluon) Pythonで3つのAutoML環境を用意してみた
(auto-sklearn) Pythonで3つのAutoML環境を用意してみた
AutoMLは今のところ3種類の環境を準備したので、順番に試してみたいと思います。
まずは mljar から試してみます。
評価指標
タイタニックのデータセットは生存有無を正確に予測できた乗客の割合(Accuracy)を評価指標としています。
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
学習データと評価データの読み込み
import pandas as pd
import numpy as np
# タイタニックデータセットの学習用データと評価用データの読み込み
df_train = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/titanic/titanic_train.csv")
df_eval = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/titanic/titanic_eval.csv")概要確認
# 概要確認
df_train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 891 non-null object
12 FamilyCnt 891 non-null int64
13 SameTicketCnt 891 non-null int64
14 Pclass_str_1 891 non-null float64
15 Pclass_str_2 891 non-null float64
16 Pclass_str_3 891 non-null float64
17 Sex_female 891 non-null float64
18 Sex_male 891 non-null float64
19 Embarked_C 891 non-null float64
20 Embarked_Q 891 non-null float64
21 Embarked_S 891 non-null float64
dtypes: float64(10), int64(7), object(5)
memory usage: 153.3+ KB
# 概要確認
df_eval.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 418 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 418 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
11 Pclass_str_1 418 non-null float64
12 Pclass_str_2 418 non-null float64
13 Pclass_str_3 418 non-null float64
14 Sex_female 418 non-null float64
15 Sex_male 418 non-null float64
16 Embarked_C 418 non-null float64
17 Embarked_Q 418 non-null float64
18 Embarked_S 418 non-null float64
19 FamilyCnt 418 non-null int64
20 SameTicketCnt 418 non-null int64
dtypes: float64(10), int64(6), object(5)
memory usage: 68.7+ KB
# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)モデリング用に学習用データを訓練データとテストデータに分割
# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(df_train, test_size=0.20,random_state=100)
# 説明変数
FEATURE_COLS=[
'Age'
, 'Fare'
, 'SameTicketCnt'
, 'Pclass_str_1'
, 'Pclass_str_3'
, 'Sex_female'
, 'Embarked_Q'
, 'Embarked_S'
]
X_train = x_train[FEATURE_COLS] # 説明変数 (train)
Y_train = x_train["Survived"] # 目的変数 (train)
X_test = x_test[FEATURE_COLS] # 説明変数 (test)
Y_test = x_test["Survived"] # 目的変数 (test)mljar
# https://supervised.mljar.com/api/
# mljarのモデル作成
from supervised.automl import AutoML
automl = AutoML(mode="Compete", random_state=100)modeは複数選択できます。今回はCompeteモードを実行します。
Competeモードはコンペ用に精度を追求したモードになります。
モデル作成
# fitで学習させる
automl.fit(X_train,Y_train)
AutoML directory: AutoML_2
The task is binary_classification with evaluation metric logloss
AutoML will use algorithms: ['Decision Tree', 'Linear', 'Random Forest', 'Extra Trees', 'LightGBM', 'Xgboost', 'CatBoost', 'Neural Network', 'Nearest Neighbors']
AutoML will stack models
AutoML will ensemble available models
AutoML steps: ['adjust_validation', 'simple_algorithms', 'default_algorithms', 'not_so_random', 'golden_features', 'kmeans_features', 'insert_random_feature', 'features_selection', 'hill_climbing_1', 'hill_climbing_2', 'boost_on_errors', 'ensemble', 'stack', 'ensemble_stacked']
* Step adjust_validation will try to check up to 1 model
1_DecisionTree logloss 0.567949 trained in 1.19 seconds
Adjust validation. Remove: 1_DecisionTree
Validation strategy: 10-fold CV Shuffle,Stratify
* Step simple_algorithms will try to check up to 4 models
1_DecisionTree logloss 0.602245 trained in 4.38 seconds
2_DecisionTree logloss 0.563085 trained in 4.04 seconds
3_DecisionTree logloss 0.455007 trained in 4.42 seconds
4_Linear logloss 0.450752 trained in 8.04 seconds
* Step default_algorithms will try to check up to 7 models
5_Default_LightGBM logloss 0.421875 trained in 6.39 seconds
6_Default_Xgboost logloss 0.419798 trained in 6.82 seconds
7_Default_CatBoost logloss 0.39265 trained in 6.3 seconds
8_Default_NeuralNetwork logloss 0.452638 trained in 8.01 seconds
9_Default_RandomForest logloss 0.412185 trained in 11.74 seconds
10_Default_ExtraTrees logloss 0.447975 trained in 11.89 seconds
11_Default_NearestNeighbors logloss 0.920078 trained in 6.0 seconds
* Step not_so_random will try to check up to 61 models
21_LightGBM logloss 0.418538 trained in 7.4 seconds
12_Xgboost logloss 0.41681 trained in 8.47 seconds
30_CatBoost logloss 0.388772 trained in 7.15 seconds
39_RandomForest logloss 0.410939 trained in 13.22 seconds
48_ExtraTrees logloss 0.414481 trained in 12.63 seconds
57_NeuralNetwork logloss 0.47381 trained in 9.41 seconds
66_NearestNeighbors logloss 0.807434 trained in 7.35 seconds
22_LightGBM logloss 0.410037 trained in 8.64 seconds
13_Xgboost logloss 0.43098 trained in 9.28 seconds
31_CatBoost logloss 0.39616 trained in 10.19 seconds
40_RandomForest logloss 0.414593 trained in 18.0 seconds
49_ExtraTrees logloss 0.417487 trained in 14.32 seconds
58_NeuralNetwork logloss 0.460169 trained in 12.2 seconds
67_NearestNeighbors logloss 1.049051 trained in 8.35 seconds
23_LightGBM logloss 0.430469 trained in 9.81 seconds
14_Xgboost logloss 0.438132 trained in 10.99 seconds
32_CatBoost logloss 0.400784 trained in 14.11 seconds
41_RandomForest logloss 0.405409 trained in 15.38 seconds
50_ExtraTrees logloss 0.420452 trained in 14.92 seconds
59_NeuralNetwork logloss 0.51347 trained in 12.73 seconds
68_NearestNeighbors logloss 1.427616 trained in 10.03 seconds
24_LightGBM logloss 0.426847 trained in 12.63 seconds
15_Xgboost logloss 0.402373 trained in 12.21 seconds
33_CatBoost logloss 0.390621 trained in 12.36 seconds
42_RandomForest logloss 0.41898 trained in 20.05 seconds
51_ExtraTrees logloss 0.423715 trained in 16.42 seconds
60_NeuralNetwork logloss 0.52747 trained in 13.77 seconds
69_NearestNeighbors logloss 1.427616 trained in 10.48 seconds
25_LightGBM logloss 0.419036 trained in 12.17 seconds
16_Xgboost logloss 0.463085 trained in 12.62 seconds
34_CatBoost logloss 0.402524 trained in 13.88 seconds
43_RandomForest logloss 0.416642 trained in 23.7 seconds
52_ExtraTrees logloss 0.435716 trained in 20.86 seconds
61_NeuralNetwork logloss 0.546483 trained in 15.6 seconds
70_NearestNeighbors logloss 1.049051 trained in 11.85 seconds
26_LightGBM logloss 0.406914 trained in 13.12 seconds
17_Xgboost logloss 0.585177 trained in 14.25 seconds
35_CatBoost logloss 0.397436 trained in 16.04 seconds
44_RandomForest logloss 0.414609 trained in 19.83 seconds
53_ExtraTrees logloss 0.454507 trained in 21.77 seconds
62_NeuralNetwork logloss 0.643082 trained in 15.52 seconds
71_NearestNeighbors logloss 1.608606 trained in 12.84 seconds
27_LightGBM logloss 0.424306 trained in 14.85 seconds
18_Xgboost logloss 0.596754 trained in 14.84 seconds
36_CatBoost logloss 0.396218 trained in 15.97 seconds
45_RandomForest logloss 0.421922 trained in 23.84 seconds
54_ExtraTrees logloss 0.470755 trained in 20.88 seconds
63_NeuralNetwork logloss 0.475343 trained in 17.87 seconds
72_NearestNeighbors logloss 1.427616 trained in 14.14 seconds
28_LightGBM logloss 0.409946 trained in 15.94 seconds
19_Xgboost logloss 0.430856 trained in 16.9 seconds
37_CatBoost logloss 0.389202 trained in 17.44 seconds
46_RandomForest logloss 0.413533 trained in 23.31 seconds
55_ExtraTrees logloss 0.442965 trained in 20.53 seconds
64_NeuralNetwork logloss 0.480929 trained in 17.99 seconds
29_LightGBM logloss 0.417319 trained in 16.69 seconds
20_Xgboost logloss 0.584405 trained in 18.04 seconds
38_CatBoost logloss 0.395742 trained in 18.44 seconds
47_RandomForest logloss 0.414602 trained in 26.64 seconds
56_ExtraTrees logloss 0.418954 trained in 25.37 seconds
65_NeuralNetwork logloss 0.500499 trained in 19.26 seconds
* Step golden_features will try to check up to 3 models
None 10
Add Golden Feature: Pclass_str_3_diff_Sex_female
Add Golden Feature: Sex_female_sum_Pclass_str_1
Add Golden Feature: Sex_female_ratio_SameTicketCnt
Add Golden Feature: Sex_female_multiply_SameTicketCnt
Add Golden Feature: SameTicketCnt_ratio_Sex_female
Add Golden Feature: Sex_female_diff_Embarked_S
Add Golden Feature: Embarked_Q_sum_Sex_female
Add Golden Feature: Sex_female_sum_SameTicketCnt
Add Golden Feature: Sex_female_multiply_Pclass_str_1
Add Golden Feature: Sex_female_ratio_Pclass_str_1
Created 10 Golden Features in 11.27 seconds.
30_CatBoost_GoldenFeatures logloss 0.390194 trained in 30.33 seconds
37_CatBoost_GoldenFeatures logloss 0.3996 trained in 19.95 seconds
33_CatBoost_GoldenFeatures logloss 0.398953 trained in 20.31 seconds
* Step kmeans_features will try to check up to 3 models
30_CatBoost_KMeansFeatures logloss 0.394747 trained in 20.3 seconds
37_CatBoost_KMeansFeatures logloss 0.403682 trained in 21.41 seconds
33_CatBoost_KMeansFeatures logloss 0.402157 trained in 21.79 seconds
* Step insert_random_feature will try to check up to 1 model
30_CatBoost_RandomFeature logloss 0.398843 trained in 20.69 seconds
Drop features ['Embarked_S', 'random_feature', 'Embarked_Q']
* Step features_selection will try to check up to 6 models
30_CatBoost_SelectedFeatures logloss 0.39354 trained in 21.2 seconds
15_Xgboost_SelectedFeatures logloss 0.402946 trained in 20.32 seconds
41_RandomForest_SelectedFeatures logloss 0.408014 trained in 26.05 seconds
26_LightGBM_SelectedFeatures logloss 0.407294 trained in 19.79 seconds
48_ExtraTrees_SelectedFeatures logloss 0.410218 trained in 24.66 seconds
8_Default_NeuralNetwork_SelectedFeatures logloss 0.431012 trained in 22.16 seconds
* Step hill_climbing_1 will try to check up to 31 models
73_CatBoost logloss 0.389943 trained in 20.52 seconds
74_CatBoost_GoldenFeatures logloss 0.395436 trained in 20.95 seconds
75_Xgboost logloss 0.40114 trained in 21.68 seconds
76_Xgboost logloss 0.405252 trained in 22.0 seconds
77_Xgboost_SelectedFeatures logloss 0.402009 trained in 22.96 seconds
78_Xgboost_SelectedFeatures logloss 0.403257 trained in 22.28 seconds
79_RandomForest logloss 0.411572 trained in 28.07 seconds
80_RandomForest logloss 0.407432 trained in 27.12 seconds
81_LightGBM logloss 0.410037 trained in 21.76 seconds
82_LightGBM logloss 0.40899 trained in 21.47 seconds
83_LightGBM_SelectedFeatures logloss 0.408176 trained in 22.33 seconds
84_LightGBM_SelectedFeatures logloss 0.406016 trained in 22.01 seconds
85_RandomForest_SelectedFeatures logloss 0.411539 trained in 30.15 seconds
86_RandomForest_SelectedFeatures logloss 0.408014 trained in 28.85 seconds
87_LightGBM logloss 0.415542 trained in 22.73 seconds
88_LightGBM logloss 0.419886 trained in 22.69 seconds
89_ExtraTrees_SelectedFeatures logloss 0.410218 trained in 28.21 seconds
90_RandomForest logloss 0.410939 trained in 29.69 seconds
91_ExtraTrees logloss 0.414481 trained in 28.02 seconds
92_Xgboost logloss 0.418173 trained in 24.23 seconds
93_ExtraTrees logloss 0.417487 trained in 40.5 seconds
94_NeuralNetwork_SelectedFeatures logloss 0.443693 trained in 37.7 seconds
95_NeuralNetwork_SelectedFeatures logloss 0.514071 trained in 41.13 seconds
96_NeuralNetwork logloss 0.465475 trained in 29.56 seconds
97_NeuralNetwork logloss 0.479735 trained in 32.72 seconds
98_DecisionTree logloss 0.514448 trained in 30.53 seconds
99_NeuralNetwork logloss 0.531638 trained in 28.44 seconds
100_DecisionTree logloss 0.464915 trained in 24.23 seconds
101_DecisionTree logloss 0.723283 trained in 24.46 seconds
102_DecisionTree logloss 0.514448 trained in 24.73 seconds
103_NearestNeighbors logloss 1.1462 trained in 24.79 seconds
* Step hill_climbing_2 will try to check up to 10 models
104_CatBoost logloss 0.394675 trained in 26.15 seconds
105_Xgboost logloss 0.411168 trained in 27.43 seconds
106_Xgboost_SelectedFeatures logloss 0.411864 trained in 41.72 seconds
107_Xgboost logloss 0.40767 trained in 37.67 seconds
108_LightGBM_SelectedFeatures logloss 0.410488 trained in 30.6 seconds
109_LightGBM logloss 0.406375 trained in 33.79 seconds
110_LightGBM_SelectedFeatures logloss 0.407976 trained in 36.19 seconds
111_RandomForest logloss 0.418069 trained in 42.58 seconds
112_ExtraTrees_SelectedFeatures logloss 0.411296 trained in 37.63 seconds
113_NeuralNetwork_SelectedFeatures logloss 0.489014 trained in 33.15 seconds
* Step boost_on_errors will try to check up to 1 model
30_CatBoost_BoostOnErrors logloss 0.393569 trained in 30.84 seconds
* Step ensemble will try to check up to 1 model
Ensemble logloss 0.384841 trained in 84.58 seconds
* Step stack will try to check up to 59 models
30_CatBoost_Stacked logloss 0.373164 trained in 38.49 seconds
75_Xgboost_Stacked logloss 0.389562 trained in 40.42 seconds
41_RandomForest_Stacked logloss 0.391046 trained in 43.91 seconds
84_LightGBM_SelectedFeatures_Stacked logloss 0.39183 trained in 30.89 seconds
89_ExtraTrees_SelectedFeatures_Stacked logloss 0.370869 trained in 40.62 seconds
8_Default_NeuralNetwork_SelectedFeatures_Stacked logloss 0.412413 trained in 32.7 seconds
37_CatBoost_Stacked logloss 0.387002 trained in 42.13 seconds
77_Xgboost_SelectedFeatures_Stacked logloss 0.39166 trained in 42.12 seconds
80_RandomForest_Stacked logloss 0.390082 trained in 43.68 seconds
109_LightGBM_Stacked logloss 0.389491 trained in 35.17 seconds
48_ExtraTrees_SelectedFeatures_Stacked logloss 0.372773 trained in 40.27 seconds
94_NeuralNetwork_SelectedFeatures_Stacked logloss 0.445272 trained in 33.97 seconds
73_CatBoost_Stacked logloss 0.373393 trained in 62.72 seconds
15_Xgboost_Stacked logloss 0.390611 trained in 38.46 seconds
41_RandomForest_SelectedFeatures_Stacked logloss 0.383395 trained in 52.86 seconds
26_LightGBM_Stacked logloss 0.393751 trained in 35.58 seconds
* Step ensemble_stacked will try to check up to 1 model
Ensemble_Stacked logloss 0.366951 trained in 112.21 seconds
AutoML fit time: 3754.78 seconds
AutoML best model: Ensemble_Stacked
実に様々な手法を自動で探索してくれます。
最終的に一番精度がよかったのは、Ensemble_Stackedになりました。
精度確認
# Return the mean accuracy on the given data and labels.
print("train",automl.score(X_train,Y_train))
print("test",automl.score(X_test,Y_test))
train 0.8637640449438202
test 0.8156424581005587
過学習しすぎていない精度だと思います。
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
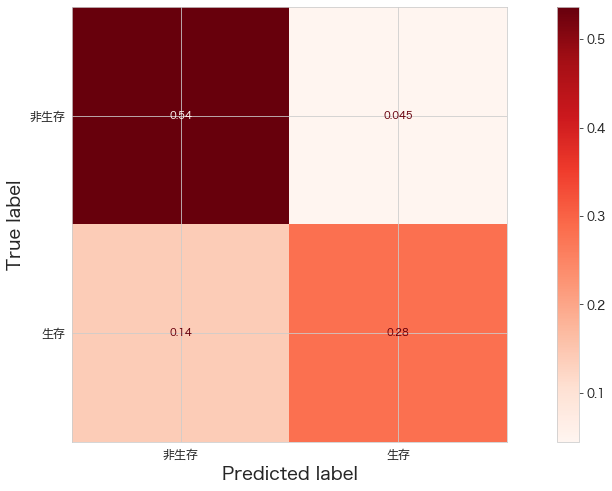
print(confusion_matrix(Y_test,automl.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(automl,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[96 8]
[25 50]]
Kaggleへ予測データをアップロード
df_eval["Survived"] = automl.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/blog/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #009. mljar"
100%|████████████████████████████████████████| 2.77k/2.77k [00:05<00:00, 566B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
0.77511
ロジスティック回帰CVの精度は0.76794だったのでmljarで作成したモデルが暫定1位になりました。
やっぱりAutoMLはすごいですね。
モデル手法というよりは、どうモデリング用のデータを作るのかが分析者の知見とセンスにかかわってくるのでしょうか?
自分のキャリアの方向性もどう他の人と差別化できるのか真剣に考えようと思います。
まとめ
mljarの精度が0.775で暫定1位になりました。
単純に全数データを投入した場合と変数選択やデータ加工をしなかった場合どうなるかなど番外編でまた検証してみたいと思います。